Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
How to Build a Decoder-Only Transformer and Select the Right Pretrained Model in 2026
Build a decoder-only transformer with correct causal masking in PyTorch, then pick between GPT-5, LLaMA 4, and DeepSeek …
How to Build and Fine-Tune Transformer Models with Hugging Face and PyTorch in 2026
Build and fine-tune transformer models the specification-first way. PyTorch 2.10, Hugging Face Transformers v5, and the …
How to Train and Choose a Custom Tokenizer with tiktoken, SentencePiece, and HF Tokenizers in 2026
Learn how to choose, train, and validate a custom tokenizer using tiktoken, SentencePiece, and HF Tokenizers with a …
Implementing Attention from Scratch: PyTorch, FlashAttention, and Grouped-Query Optimization
Spec your attention implementation before writing code. Learn to decompose QKV projections, configure FlashAttention …
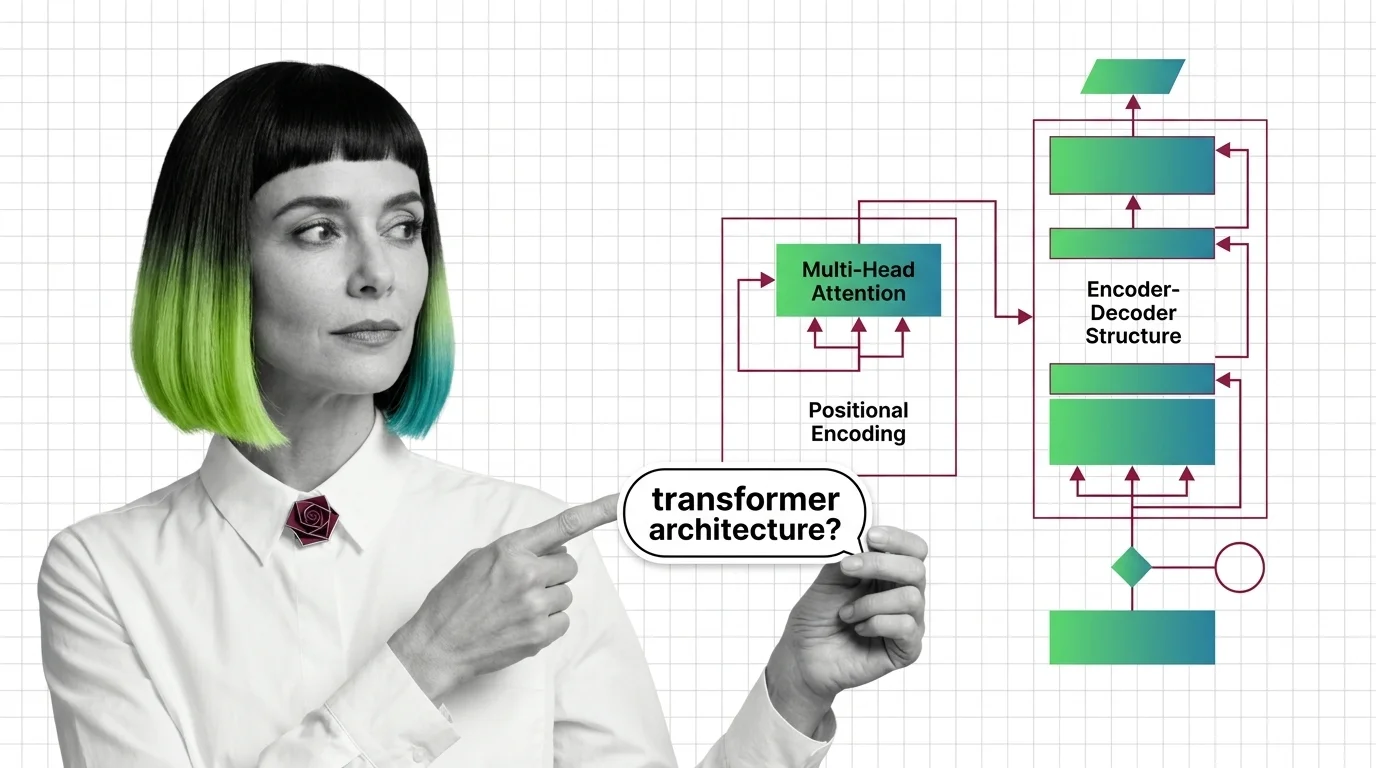
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …

NV-Embed v2, Qwen3-Embedding, and the Open-Source Surge Reshaping the Embedding Market in 2026
Open-weight embedding models now match proprietary APIs on benchmarks at a fraction of the cost. What the 2026 market …
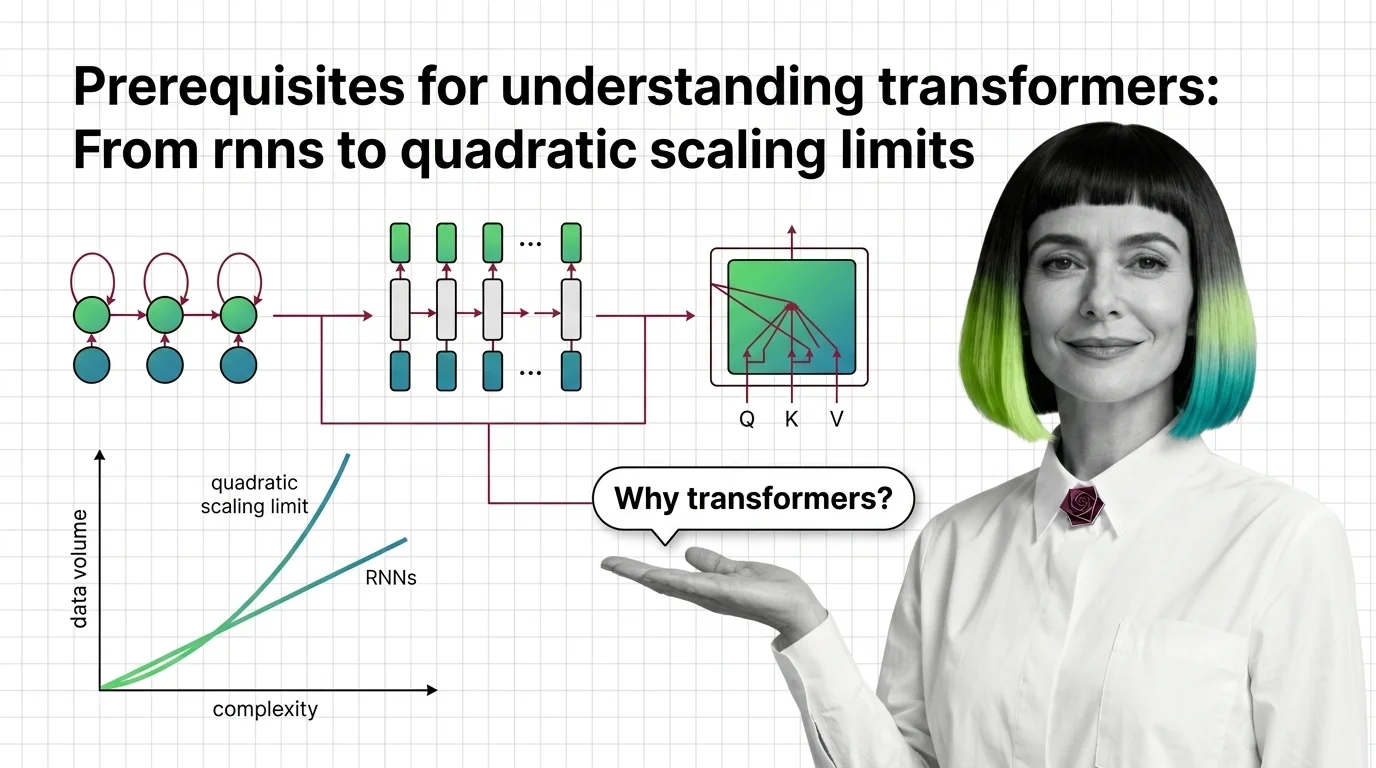
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
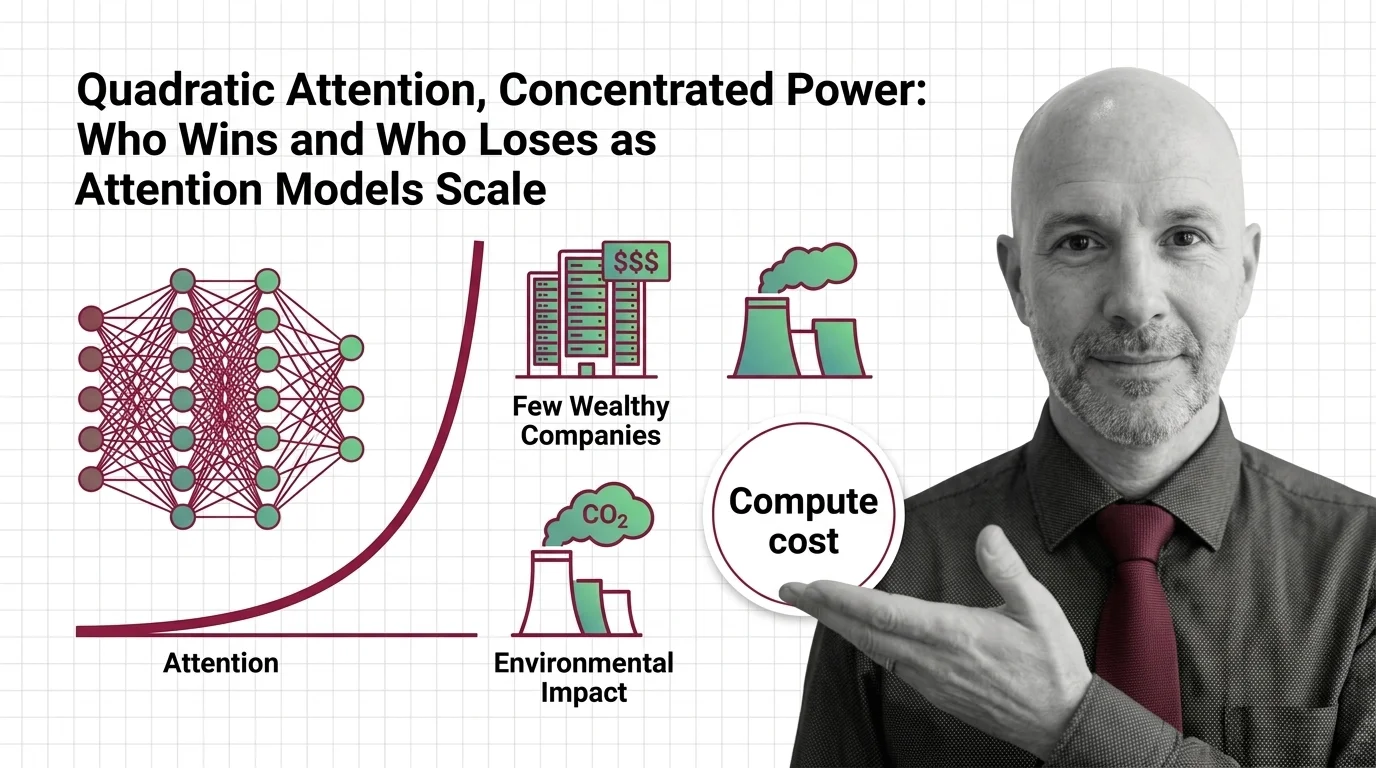
Quadratic Attention, Concentrated Power: Who Wins and Who Loses as Attention Models Scale
Quadratic attention scaling isn't just a compute problem — it shapes who builds frontier AI, who profits, and whose …
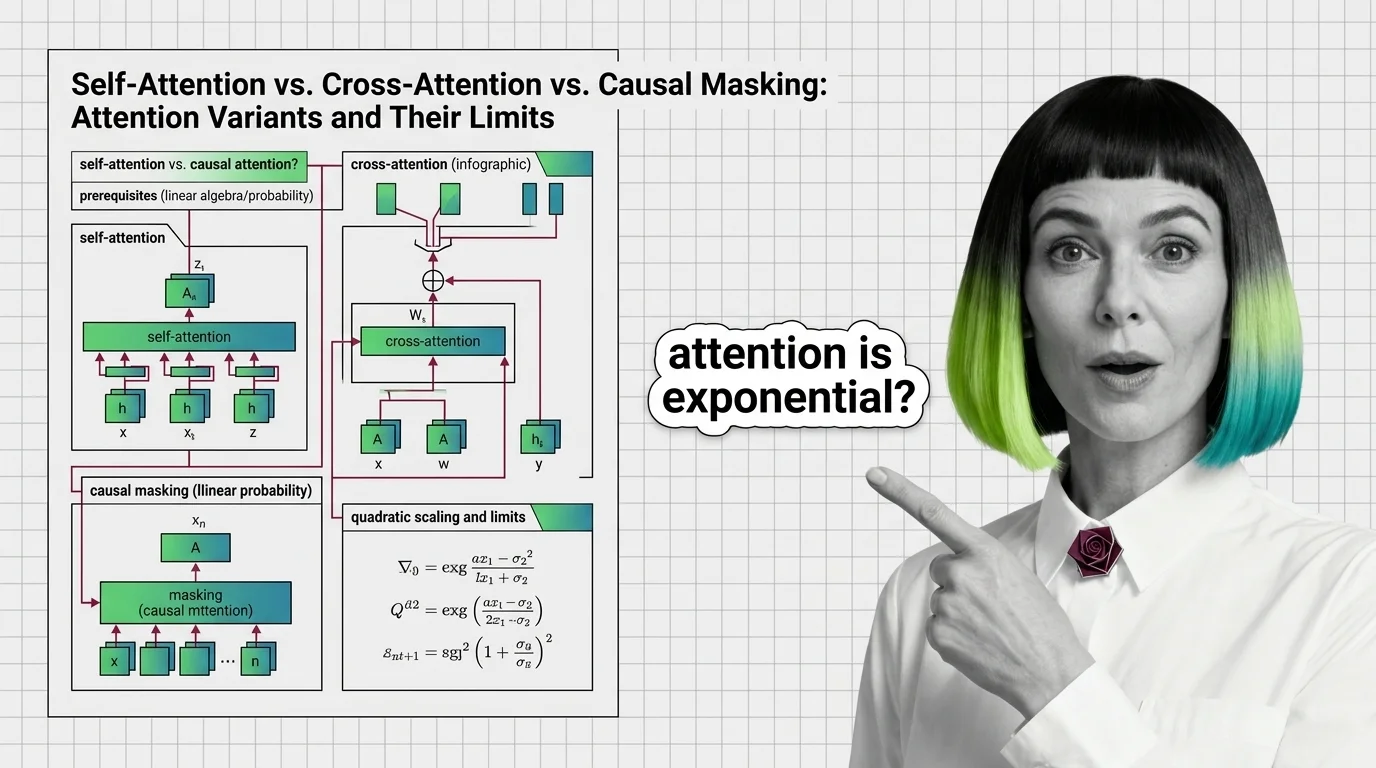
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …
Similarity Search Pipeline: FAISS, HNSWlib, ScaNN (2026)
Select between FAISS, HNSWlib, and ScaNN for production vector search. Specification-first approach covering index …

SuperBPE, LiteToken, 262K Vocab: 2026 Tokenizer Breakthrough
Tokenization is the overlooked frontier. SuperBPE and LiteToken expose 262K vocabulary gains in inference costs, …

The Decoder-Only Monoculture: What the AI Industry Risks by Betting on a Single Architecture
The AI industry converged on decoder-only architecture without rigorous comparison. Explore the ethical and structural …

The Ethical Cost of Transformers: Energy Use, Centralization, and Access Inequality
Transformer architecture demands enormous energy and capital. Explore the ethical costs of quadratic compute, …
The Hidden Bias in Tokenizers: Why Non-English Speakers Pay More Per Token
Tokenizer bias means non-English speakers pay more per API token. Explore why this structural disparity exists and who …
Transformers in 2026: GPT to Gemini, Mamba-3, and the Hybrid Architecture Shift
Mamba-3 and Nvidia Nemotron signal the hybrid architecture era. See which AI models still run pure transformers, who is …
What Are Similarity Search Algorithms and How Nearest Neighbor Methods Find Matching Vectors
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …

What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token
Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive …
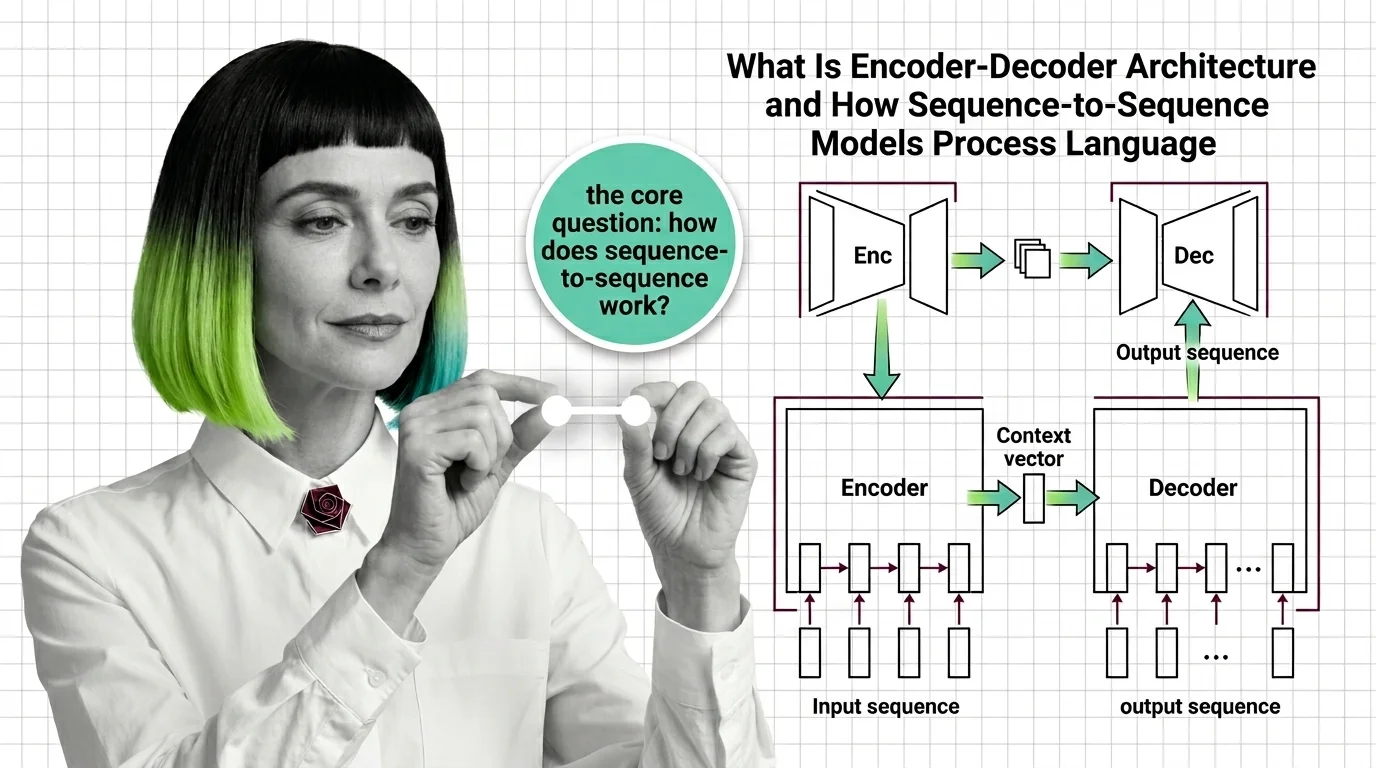
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …
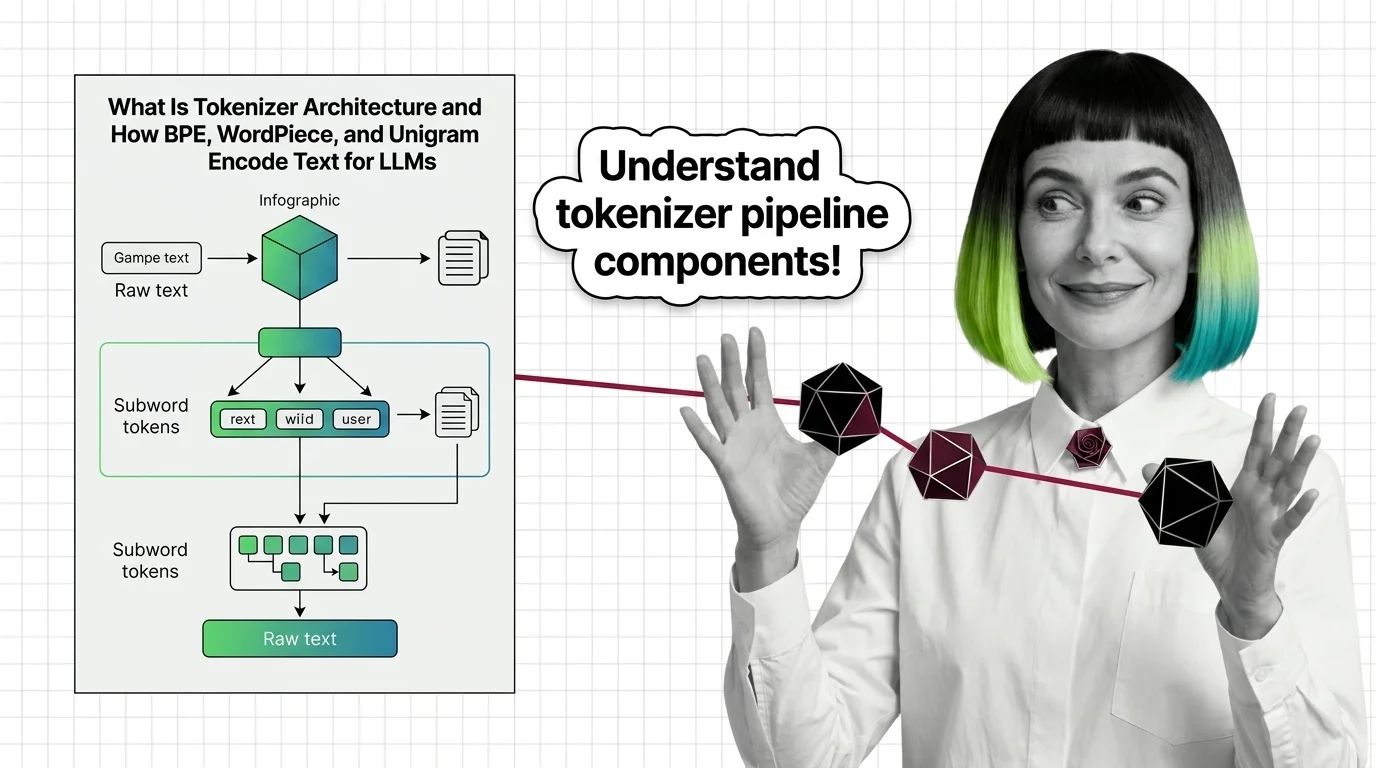
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …
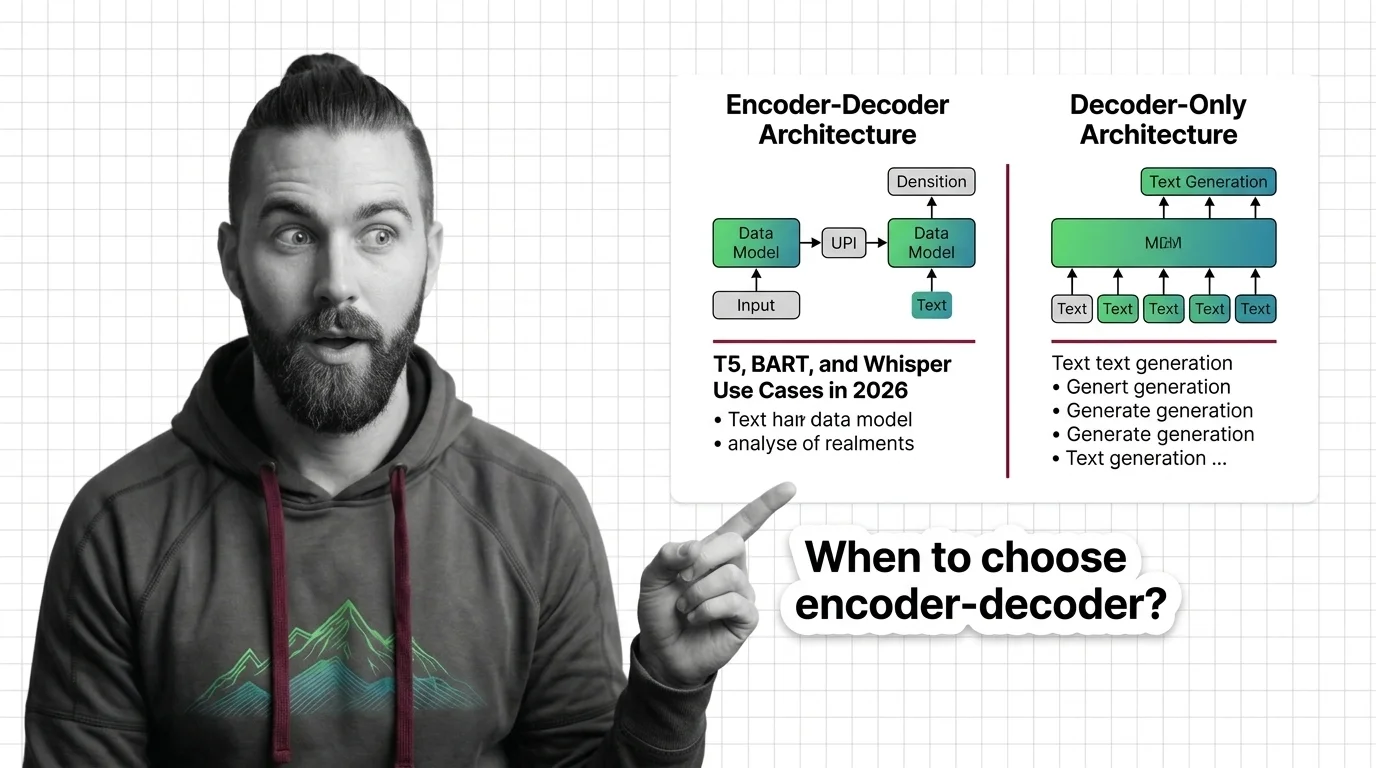
When to Choose Encoder-Decoder Over Decoder-Only: T5, BART, and Whisper Use Cases in 2026
Learn when encoder-decoder models like T5, BART, and Whisper outperform decoder-only alternatives. A spec framework for …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
Why Google's T5Gemma 2 Bets on Encoder-Decoder Architecture
T5Gemma 2 brings 128K context and multimodal input via encoder-decoder, defying the decoder-only trend. Learn why Google …
Attention Mechanism: Scaled Dot-Product, Self vs Cross
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and …

Flash Attention, Linear Attention, and the Race to Fix the Bottleneck in 2026
FlashAttention-4 and linear attention models are racing to solve the quadratic bottleneck in transformers. Here's who …
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
How to Build a Transformer from Scratch Using PyTorch and Hugging Face
Specify a transformer from scratch in PyTorch and Hugging Face. Decompose attention, embeddings, and training loops into …
How to Implement Multi-Head Attention in PyTorch and Visualize Attention Patterns
Specify multi-head attention for AI-assisted PyTorch builds. Decompose QKV projections, constrain SDPA kernels, and …
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.