Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles
Top-K, Top-P, Min-P, and Beam Search: Every LLM Sampling Method Compared
Compare top-k, top-p, min-p, and beam search LLM sampling methods. Learn how each reshapes probability distributions and …
What Is Quantization and How FP32-to-INT4 Compression Makes LLMs Run on Consumer Hardware
Quantization compresses LLM weights from FP32 to INT4, cutting memory up to 8x. Learn how GPTQ, AWQ, and calibration …
What Is Reward Model Architecture and How Bradley-Terry Scoring Shapes LLM Alignment
Reward models turn human preferences into scores that guide LLM alignment. Learn how Bradley-Terry scoring and pairwise …
What Is Temperature in LLMs and How Softmax Scaling Controls Text Generation Randomness
Temperature divides logits before softmax, reshaping the token probability distribution. Learn how this parameter, …

When AI Lies Confidently: Liability, Disclosure, and the Unsolved Ethics of LLM Hallucination
LLM hallucination is no longer a quality bug. It is a liability, disclosure, and governance problem. Explore who bears …

Who Gets to Break the Model: Power, Access, and Accountability Gaps in AI Red Teaming
AI red teaming promises safety through adversarial testing, but who selects the testers, defines harm, and bears …
Whose Preferences Count: How Reward Models Encode Bias and Shape What LLMs Refuse to Say
Reward models encode human preferences into LLM behavior — but whose preferences? Examine how annotator bias, preference …
Diminishing Returns, Data Exhaustion, and the Hard Technical Limits of Neural Scaling
Scaling laws predict how AI models improve with compute, but power-law exponents guarantee diminishing returns. Learn …
How to Apply Scaling Laws and Chinchilla-Optimal Ratios to LLM Training Decisions in 2026
Apply scaling laws and Chinchilla-optimal ratios to real LLM training decisions. Compute budgeting, model sizing, and …

What Are Scaling Laws and How Power-Law Curves Predict LLM Performance
Scaling laws predict LLM performance from model size, data, and compute via power-law curves. Learn the math behind …
From ChatGPT's PPO to DeepSeek's GRPO: How RLHF Alternatives Reshaped Alignment Through 2026
Classical RLHF with PPO launched ChatGPT, but DPO and GRPO now dominate LLM alignment. See how reward-model-free methods …

From Reward Modeling to KL Penalties: Every Stage of the RLHF Training Pipeline Explained
RLHF aligns language models through human preferences in three stages. Learn how reward models, PPO, and KL penalties …

How to Train a Language Model with RLHF Using OpenRLHF and TRL in 2026
Decompose, specify, and validate a full RLHF training pipeline with OpenRLHF and TRL in 2026. Covers SFT, reward …

Reward Hacking, Mode Collapse, and the Unsolved Technical Limits of RLHF Alignment
Reward hacking, mode collapse, and KL divergence failure — the three unsolved technical limits of RLHF alignment and why …
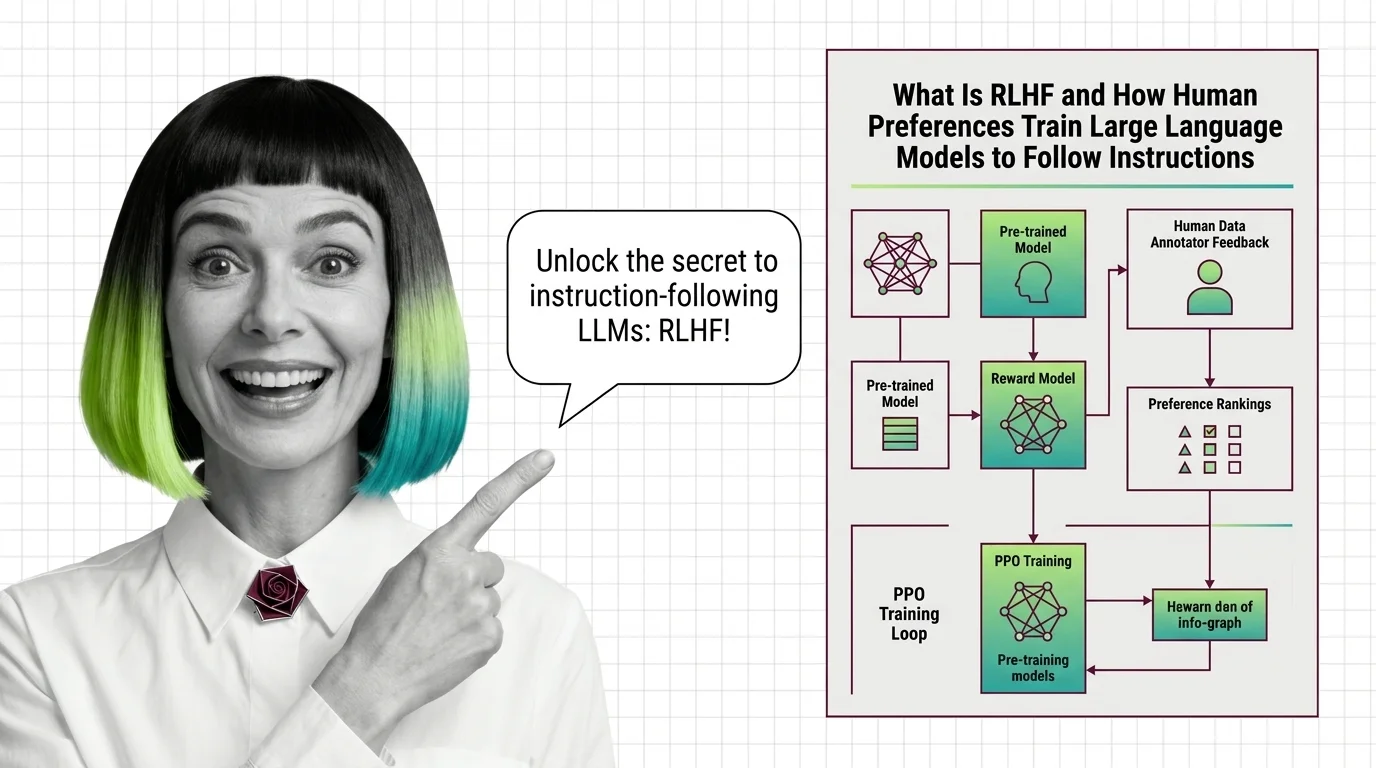
What Is RLHF and How Human Preferences Train Large Language Models to Follow Instructions
RLHF uses human preferences and reward models to train language models to follow instructions. Learn the three-stage PPO …
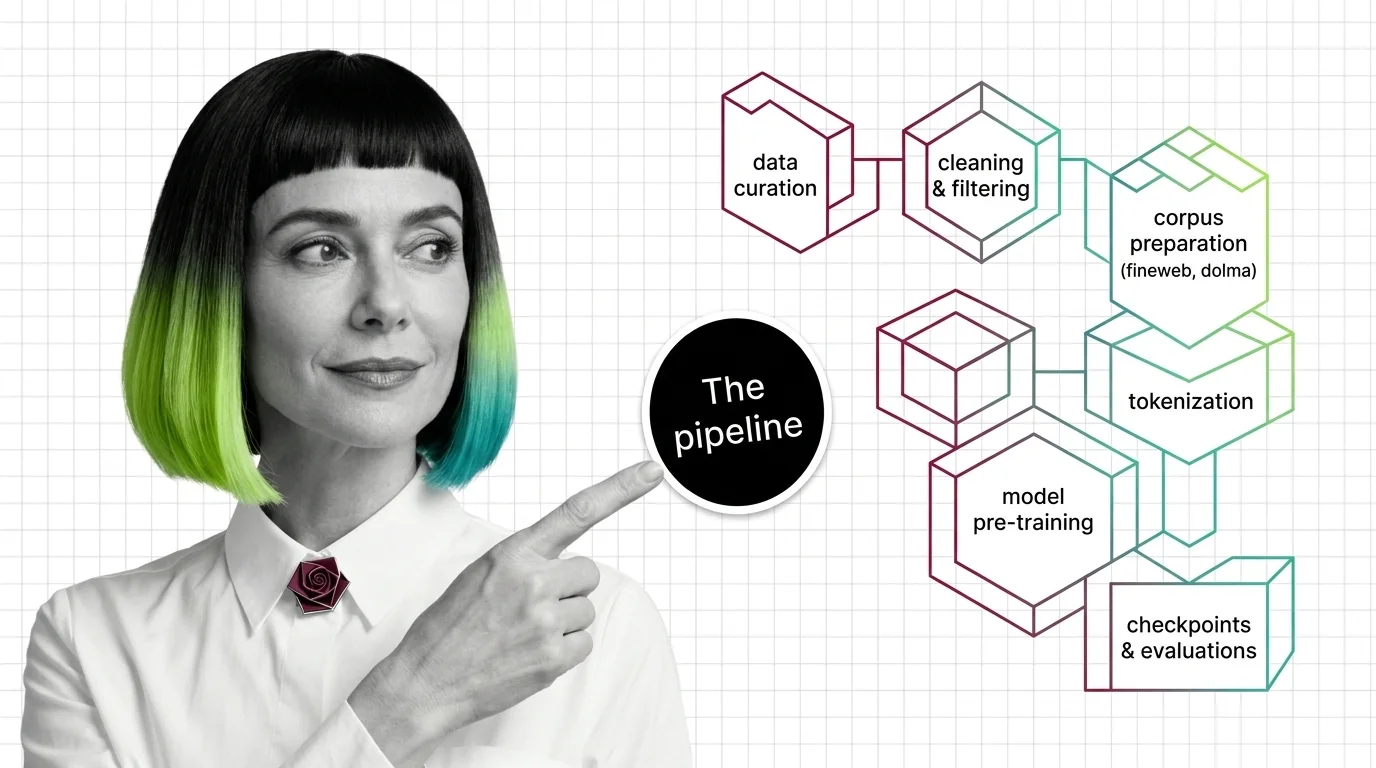
From Data Curation to Checkpoints: The Building Blocks of a Modern Pre-Training Pipeline
Pre-training pipelines run from data curation to checkpointing. Learn how FineWeb, Dolma, and Megatron-Core build the …

GLM-5, FineWeb2, and the 28-Trillion-Token Race: Pre-Training Breakthroughs Reshaping AI in 2026
GLM-5, Qwen3, and Llama 4 are rewriting pre-training records. The real race is data quality, synthetic augmentation, and …
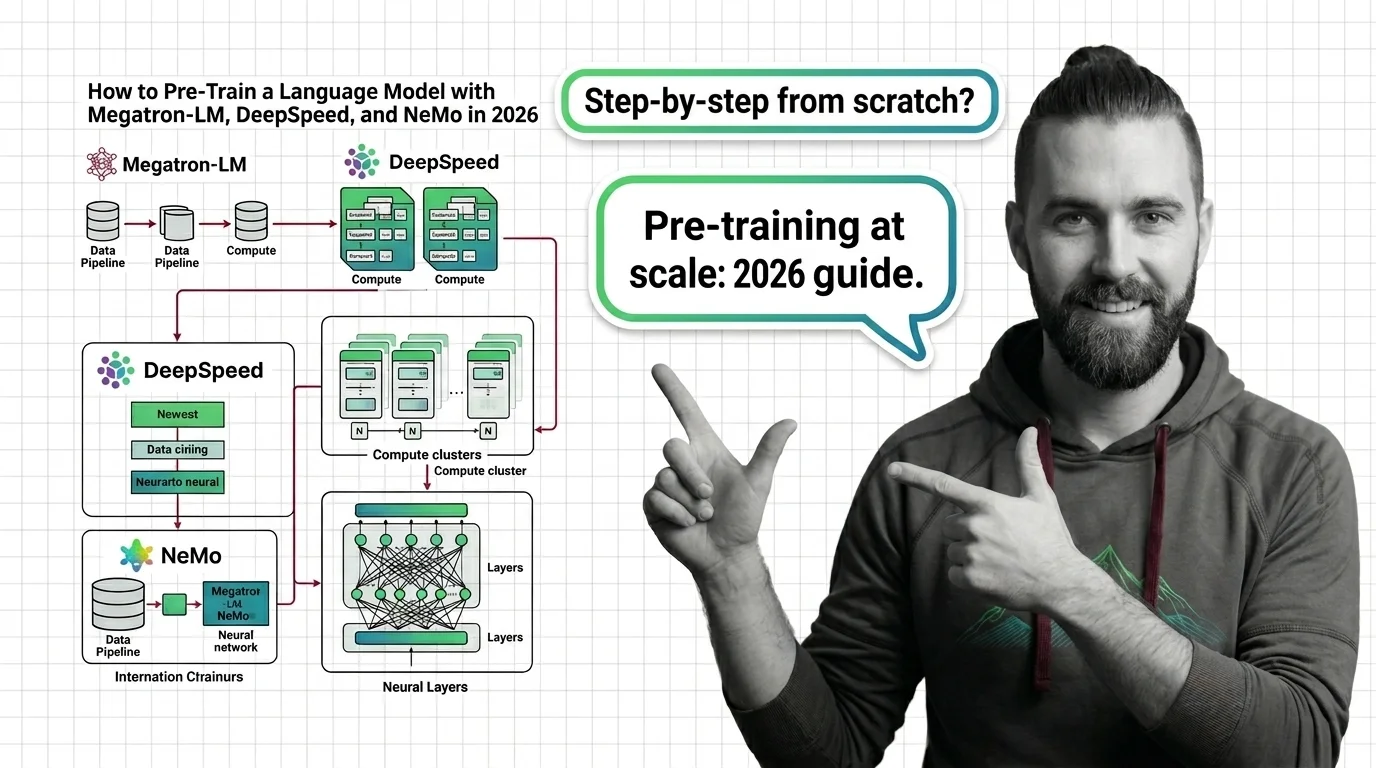
How to Pre-Train a Language Model with Megatron-LM, DeepSpeed, and NeMo in 2026
Pre-train a language model using Megatron-LM, DeepSpeed, and Megatron Bridge in 2026. Specification-first guide to …
Scaling Walls, Data Exhaustion, and the Technical Limits of Pre-Training in 2026
Pre-training compute grows 4-5x yearly while data runs out. Learn the three scaling walls — cost, data exhaustion, and …
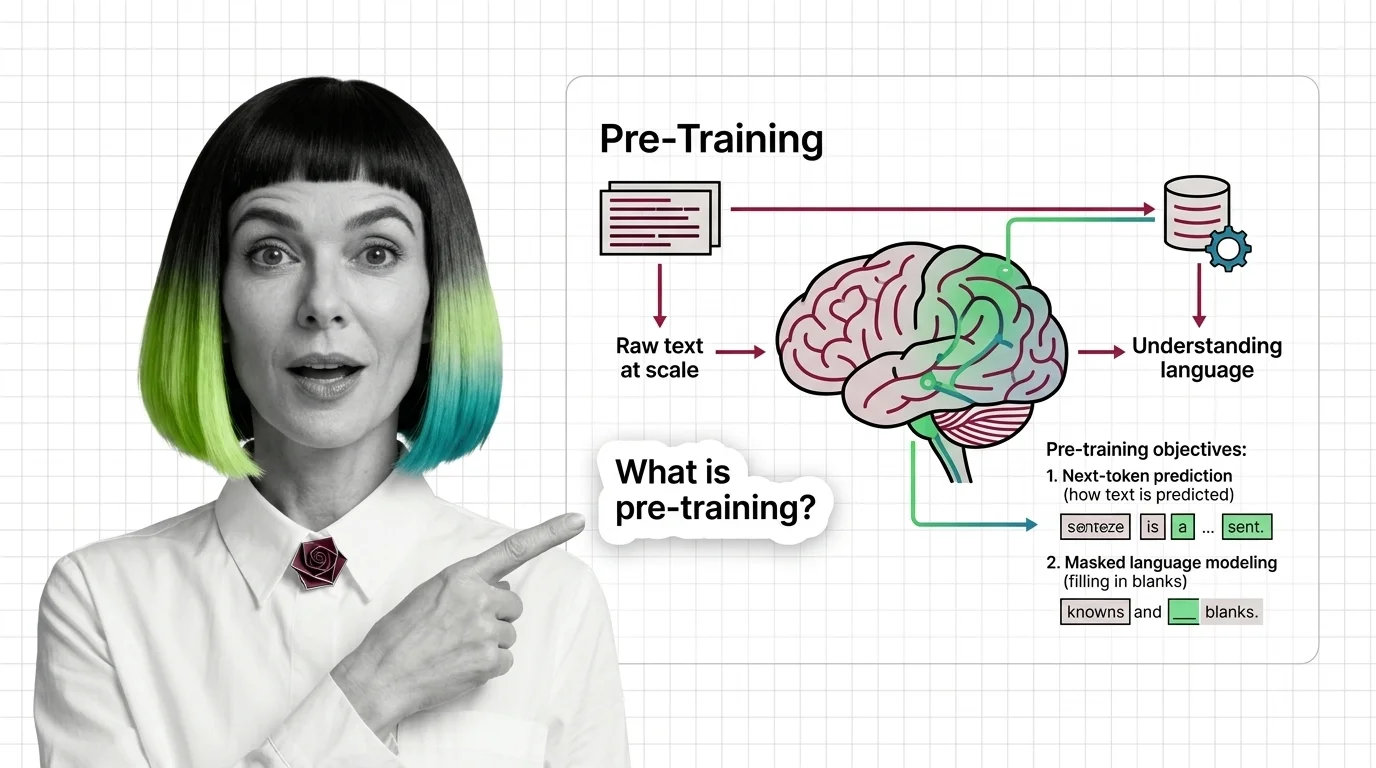
What Is Pre-Training and How LLMs Learn Language from Raw Text at Scale
Pre-training teaches LLMs to predict text, not understand it — yet prediction at scale produces something that resembles …

Catastrophic Forgetting, Overfitting, and the Hard Technical Limits of LLM Fine-Tuning
Fine-tuning can destroy what your LLM already knows. Learn why catastrophic forgetting and overfitting define the hard …
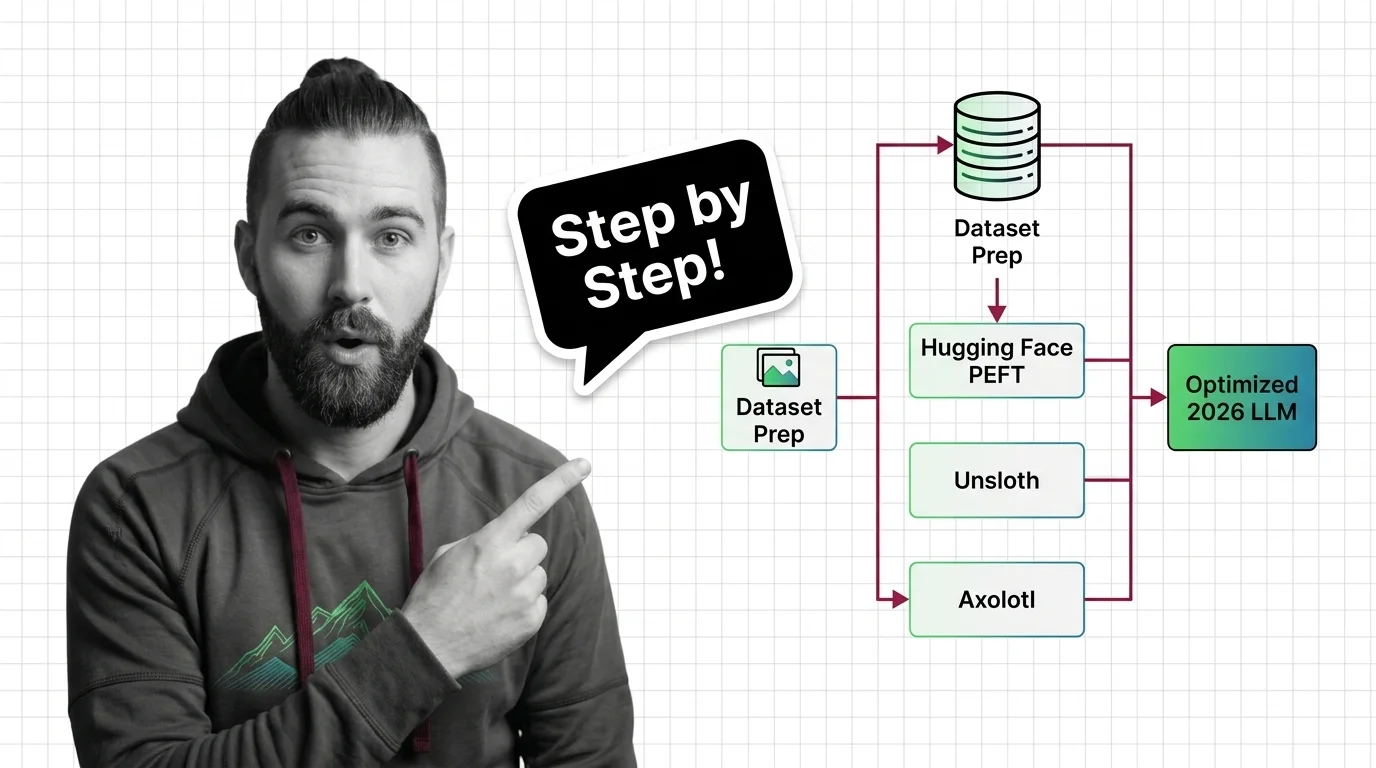
How to Fine-Tune an Open-Source LLM with Hugging Face PEFT, Unsloth, and Axolotl in 2026
Fine-tune open-source LLMs with PEFT, Unsloth, and Axolotl using a specification-first framework. Dataset prep, LoRA …

Together AI at $0.48/M, Unsloth 5x Speedups, and the Fine-Tuning Platform Race in 2026
Together AI's $0.48/M pricing and Unsloth's training speedups are reshaping LLM fine-tuning economics. Here's who wins …

Annotator Exploitation, Preference Bias, and the Hidden Human Cost of RLHF Alignment
RLHF alignment relies on annotators paid poverty wages to label traumatic content. Explore the ethical cost of …
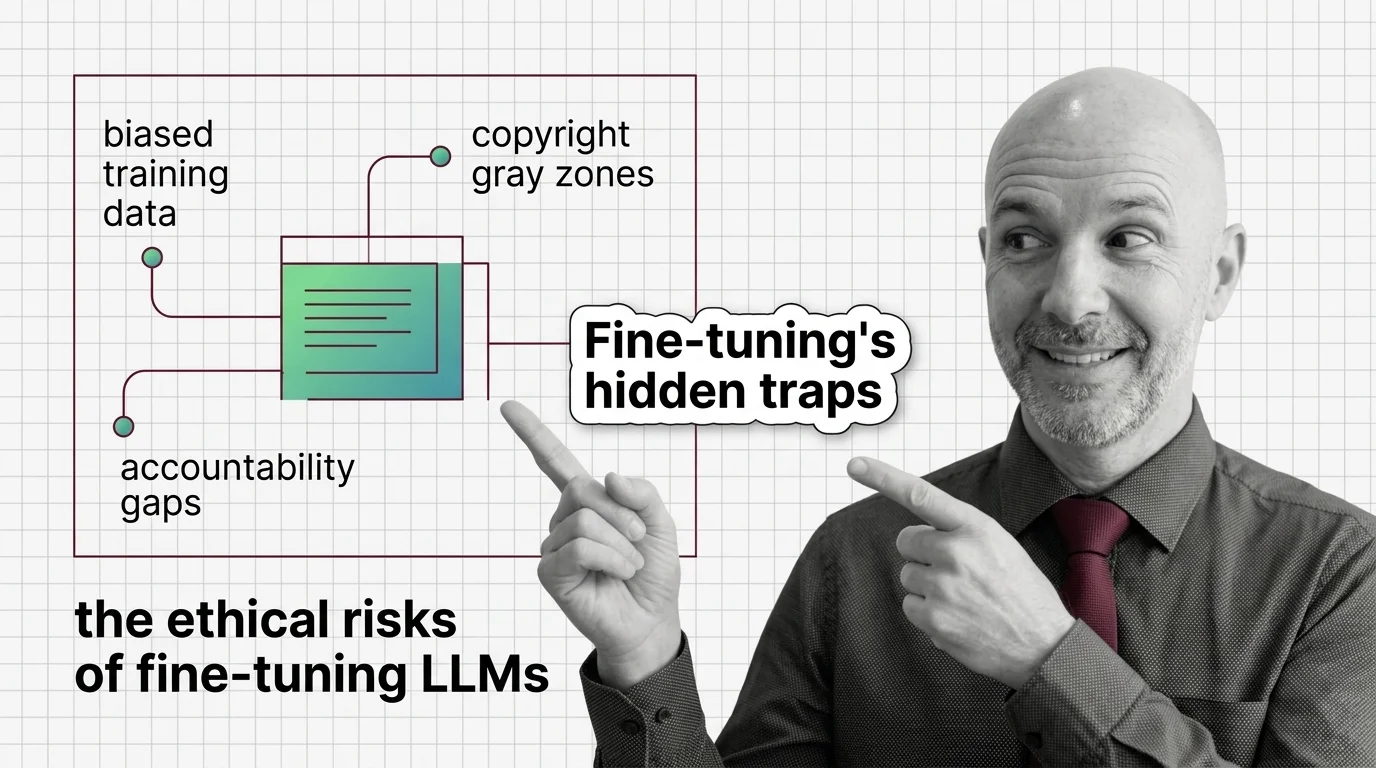
Biased Training Data, Copyright Gray Zones, and Accountability Gaps in Fine-Tuned LLMs
Fine-tuning LLMs raises ethical risks: biased data, copyright gray zones, and no clear accountability. Who bears …

Copyright, Carbon, and Consent: The Ethical Price of Training on Trillions of Tokens
AI pre-training extracts creative work and burns through environmental resources at industrial scale, all without …
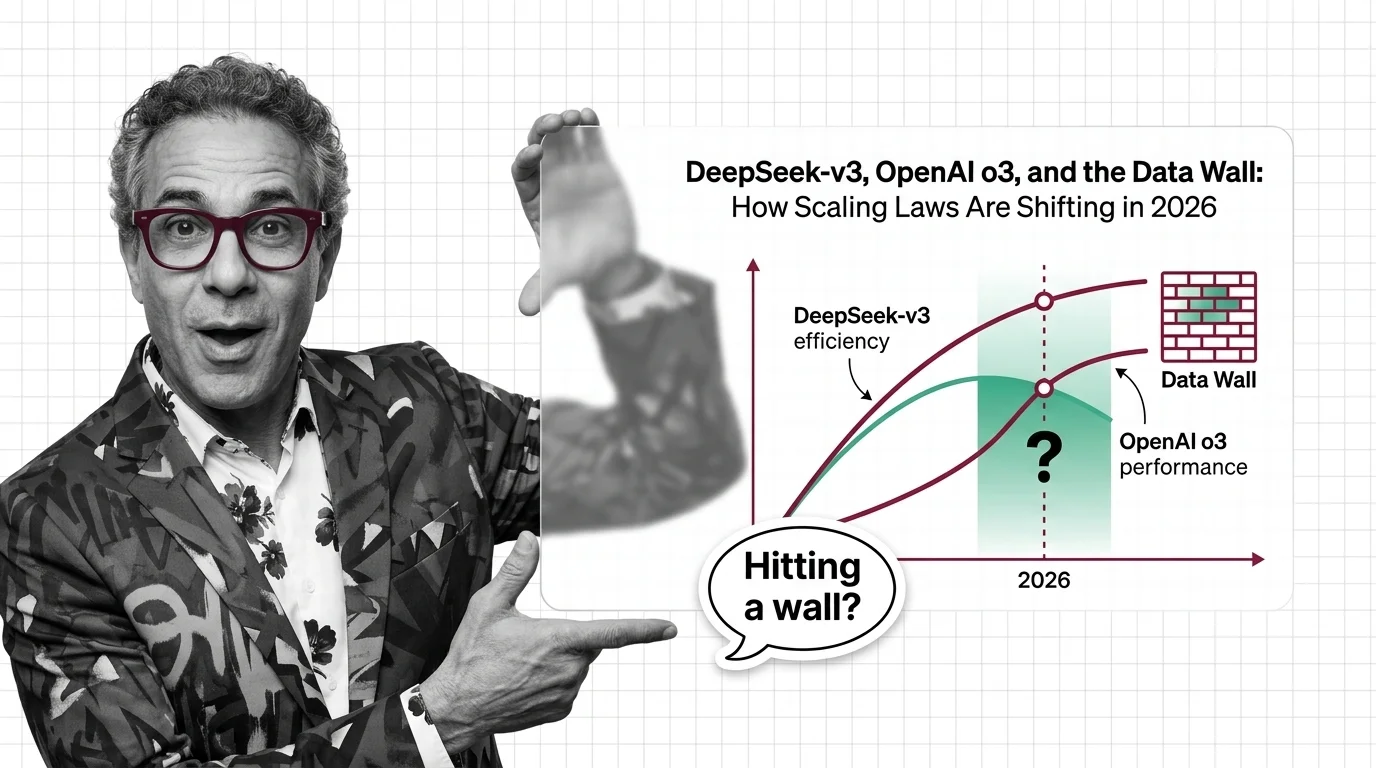
DeepSeek-v3, OpenAI o3, and the Data Wall: How Scaling Laws Are Shifting in 2026
Scaling laws split in 2025 along three axes. DeepSeek proved efficiency, o3 proved inference-time compute, and the data …
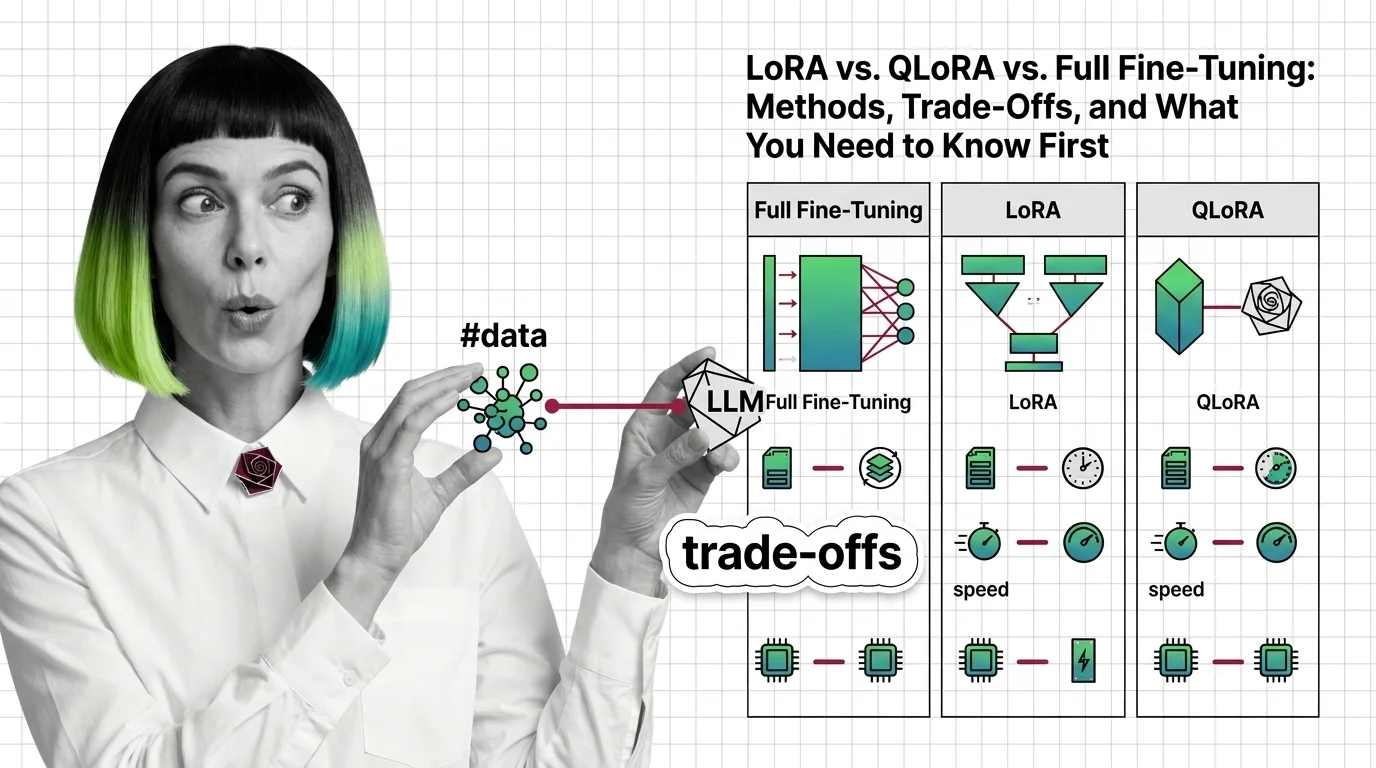
LoRA vs. QLoRA vs. Full Fine-Tuning: Methods, Trade-Offs, and What You Need to Know First
LoRA, QLoRA, and full fine-tuning each change different parts of an LLM. Learn which method fits your GPU budget, data …
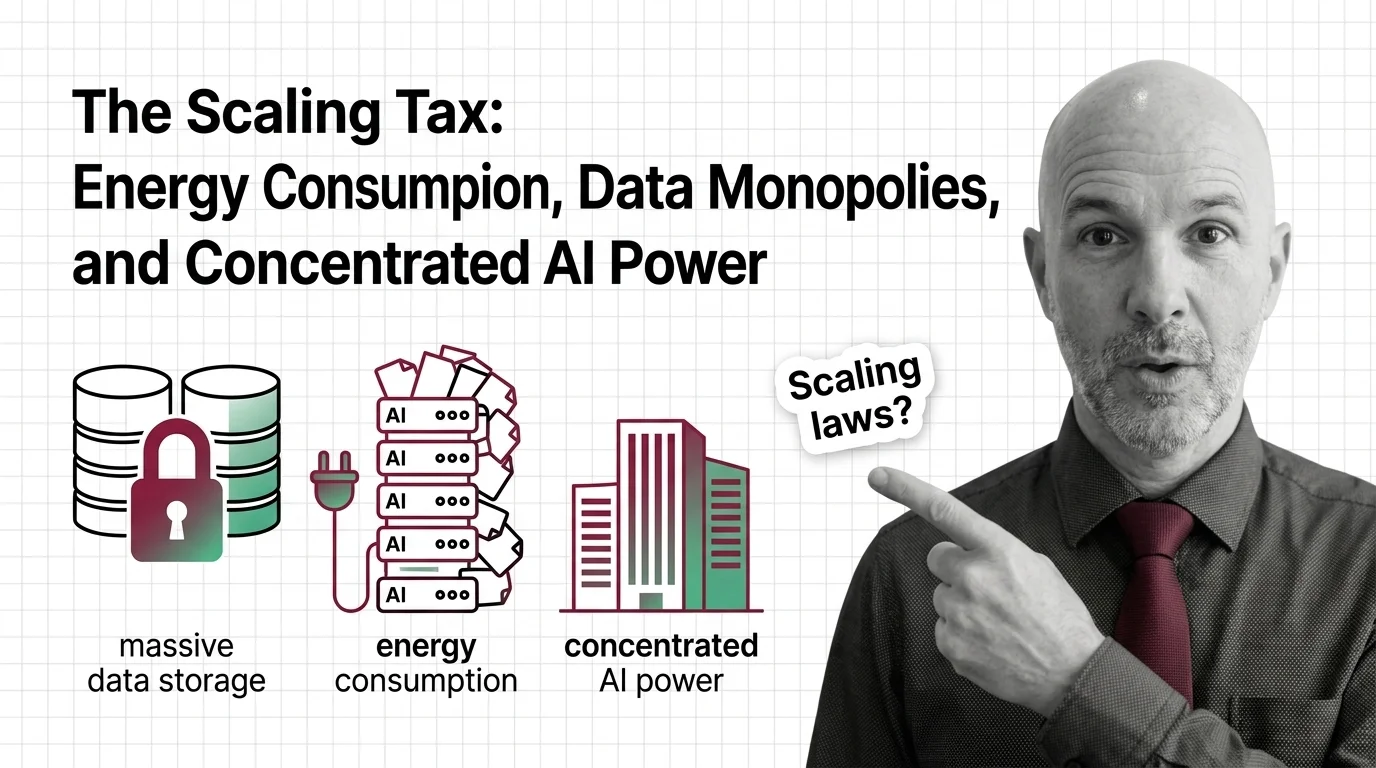
The Scaling Tax: Energy Consumption, Data Monopolies, and Concentrated AI Power
Scaling laws promise better AI through more compute, but the energy, water, and capital costs concentrate power among …
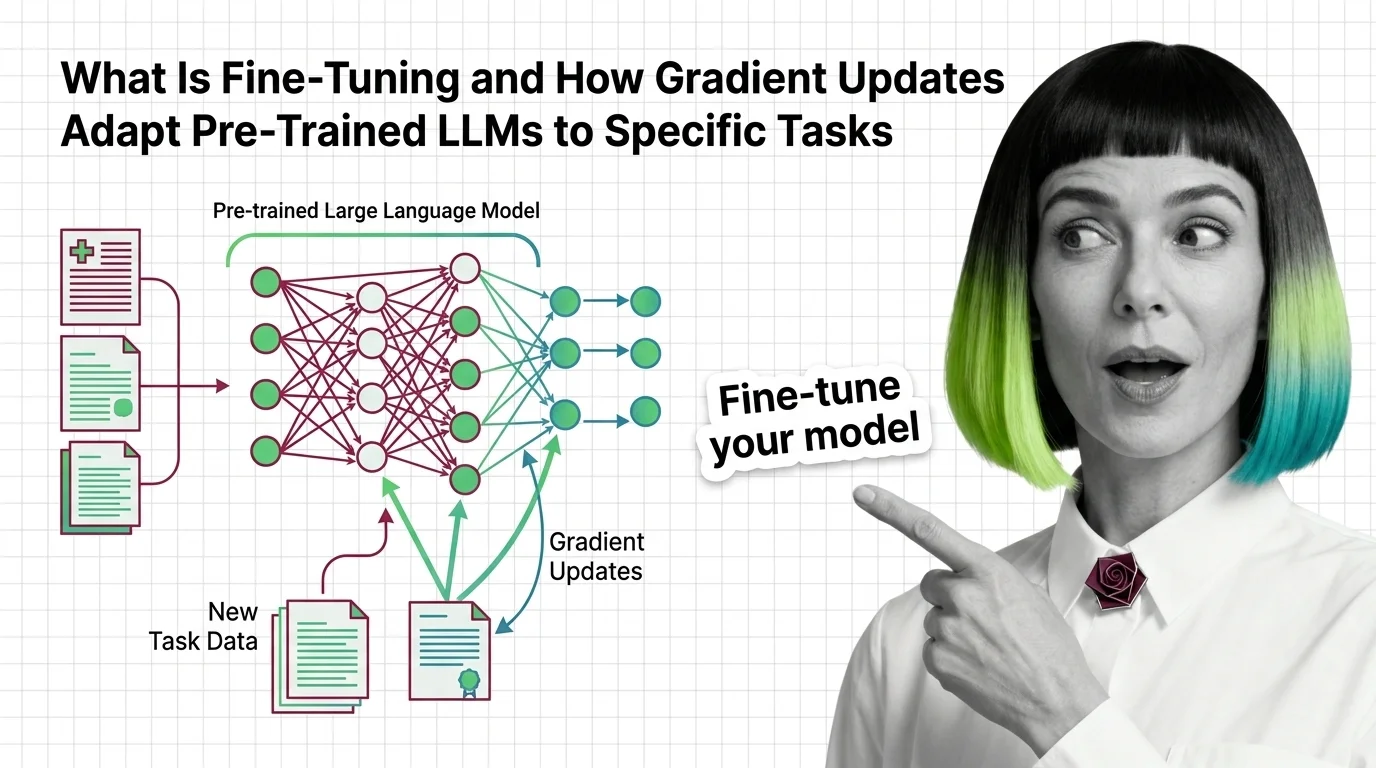
What Is Fine-Tuning and How Gradient Updates Adapt Pre-Trained LLMs to Specific Tasks
Fine-tuning adapts pre-trained LLMs by updating weights on task-specific data. Learn how gradient descent reshapes model …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.