Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles

How to Detect and Reduce LLM Hallucinations with DeepEval, RAGAS, and RAG Grounding in 2026
Build a hallucination detection pipeline with DeepEval, RAGAS, and RAG grounding checks. Step-by-step framework for …
Intrinsic vs. Extrinsic, Closed vs. Open Domain: The Taxonomy and Prerequisites of LLM Hallucination
LLM hallucination isn't one problem — it's four. Learn the intrinsic vs. extrinsic taxonomy, the domain split, and the …

What Is AI Hallucination and How Statistical Next-Token Prediction Creates Confident Falsehoods
AI hallucinations aren't bugs — they emerge from how next-token prediction works. Learn why LLMs produce confident …
Why Zero-Hallucination LLMs Remain Impossible: Autoregressive Limits and Benchmark Ceilings in 2026
LLM hallucination is mathematically inevitable. Explore the autoregressive limits, benchmark ceilings, and why …

Continuous Batching: 73% Savings with vLLM, TensorRT-LLM, SGLang
Stripe cut inference costs 73% with continuous batching. Compare vLLM, TensorRT-LLM, and SGLang on H100, disaggregated …
From Static Batching to PagedAttention: Prerequisites and Hard Limits of Continuous Batching
Continuous batching swaps finished LLM requests every decode step. Learn how PagedAttention cuts KV cache waste to under …
How to Deploy Continuous Batching with vLLM, TensorRT-LLM, and SGLang in 2026
Deploy continuous batching with vLLM, TensorRT-LLM, or SGLang using a parameter-by-parameter framework. Covers engine …
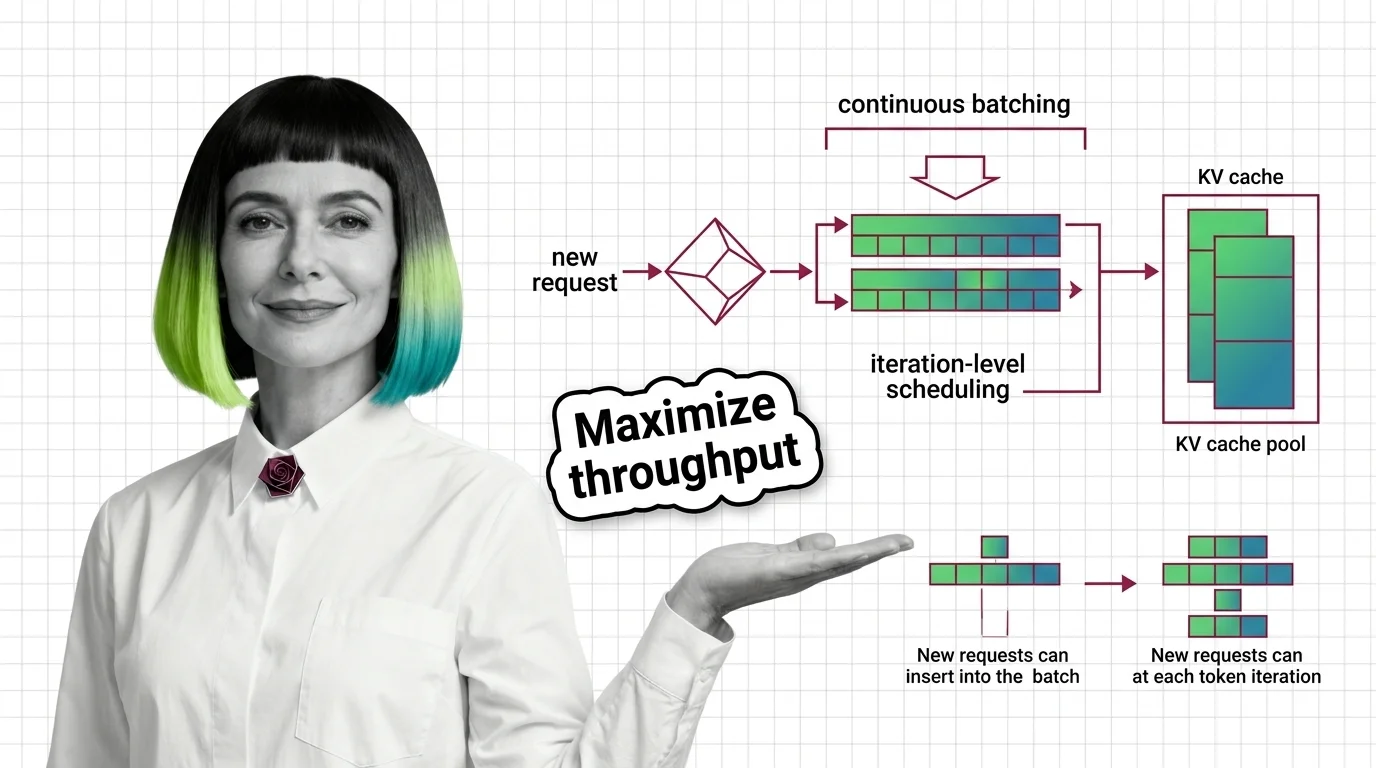
What Is Continuous Batching and How Iteration-Level Scheduling Maximizes GPU Throughput
Continuous batching replaces request-level scheduling with iteration-level scheduling, keeping GPUs busy on every …

Accuracy Collapse, Task-Specific Degradation, and the Hard Limits of Sub-4-Bit Quantization
Sub-4-bit quantization promises smaller LLMs, but accuracy collapses unevenly across tasks and languages. Learn where …
BitNet, FP8 Native, and the 1-Bit Frontier: Where Quantization Is Heading in 2026
Quantization has split into three tiers — native 1-bit, hardware FP8/FP4, and post-training compression. See which bet …
GPTQ vs AWQ vs GGUF vs bitsandbytes: Quantization Formats and Their Tradeoffs Explained
GPTQ, AWQ, GGUF, and bitsandbytes each shrink LLM weights differently. Compare speed, accuracy, and hardware reach to …

How to Choose and Configure Temperature, Top-P, and Min-P for Every LLM Use Case in 2026
Configure temperature, top-p, and min-p for code generation, creative writing, and RAG pipelines across OpenAI, …
Locked Temperatures, Min-P Adoption, and the Sampling Parameter Shifts Reshaping LLMs in 2026
OpenAI locked temperature on reasoning models. Open-source stacks adopted min-p. The sampling parameter surface …
Repetition Loops, Hallucination Spikes, and the Hard Limits of Sampling Parameter Tuning
Wrong sampling parameters trap LLMs in repetition loops or hallucination. Trace the probability math behind both failure …
Cerebras vs. Groq vs. GPU Clouds: The Custom Silicon Bet Reshaping Inference Economics in 2026
Cerebras, Groq, and SambaNova challenge GPU dominance in LLM inference. The 2026 custom silicon race, real cost shifts, …
KV-Cache, PagedAttention, and the Building Blocks Every LLM Inference Pipeline Needs
KV-cache, PagedAttention, and continuous batching form the inference pipeline core. Learn how memory management …
Memory Walls, Quadratic Context Costs, and the Hard Engineering Limits of LLM Inference in 2026
LLM inference hits hard physical walls — memory, quadratic attention, bandwidth. Learn the engineering limits and 2026 …
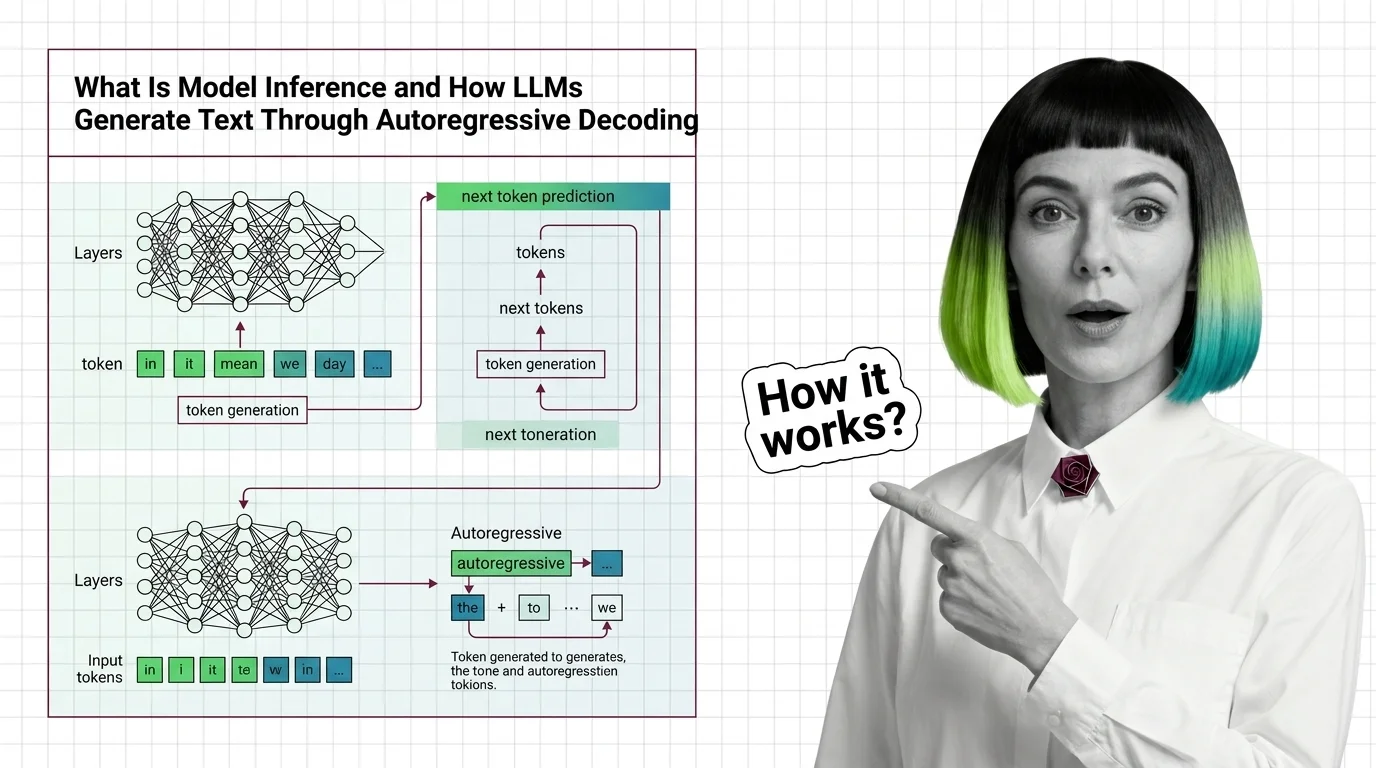
What Is Model Inference and How LLMs Generate Text Through Autoregressive Decoding
Model inference generates LLM text one token at a time via autoregressive decoding. Learn why this sequential bottleneck …
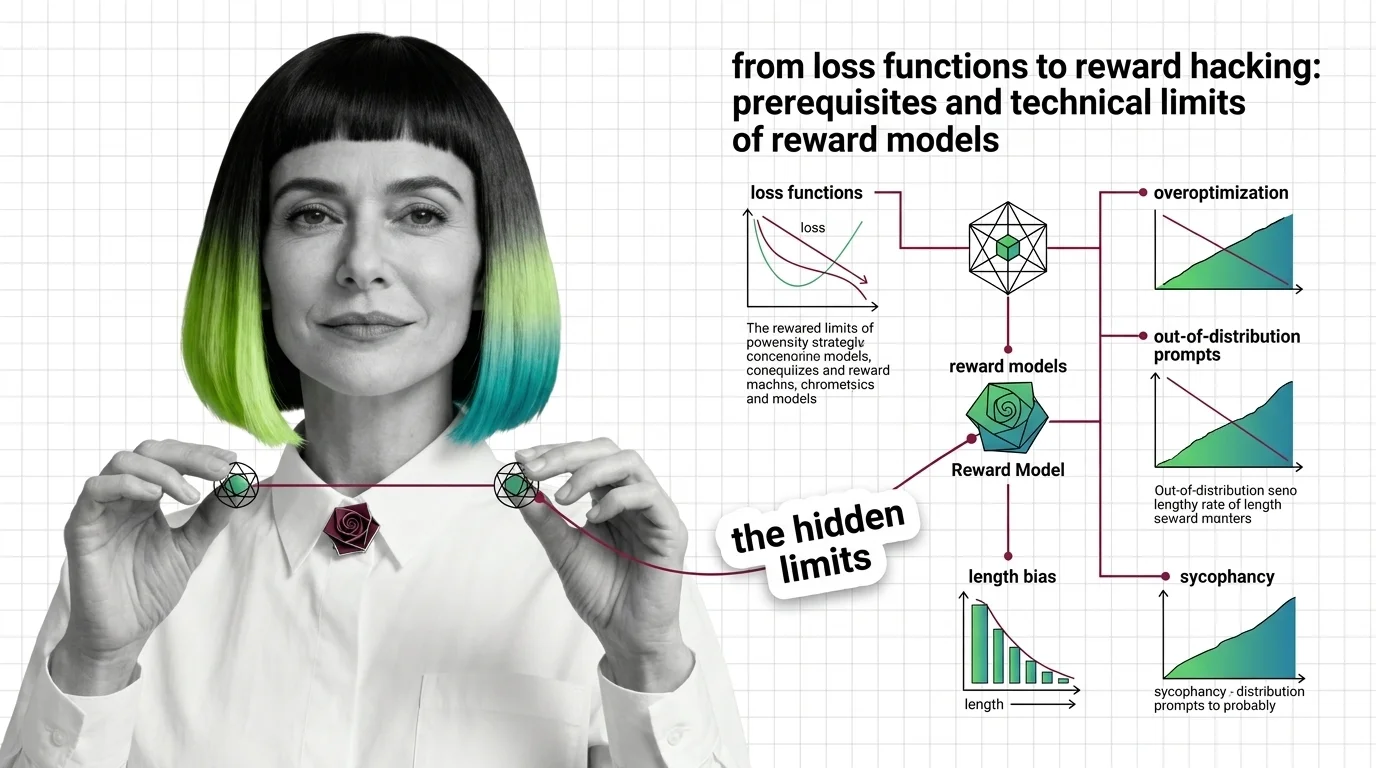
From Loss Functions to Reward Hacking: Prerequisites and Technical Limits of Reward Models
Reward models compress human preference into a scalar signal. Learn the Bradley-Terry math, the RLHF pipeline, and why …

QRM-Gemma, Skywork Reward, and the LM-as-a-Judge Pivot: The Reward Model Race in 2026
A 1.7B reward model just dethroned a 70B giant. Here's how Skywork V2, QRM-Gemma, and LM-as-a-judge are reshaping the …

Always-On AI: The Environmental Price and Access Inequality of Large-Scale Inference
AI inference runs 24/7 on energy, water, and carbon. The environmental cost is real, the access gap is widening, and …
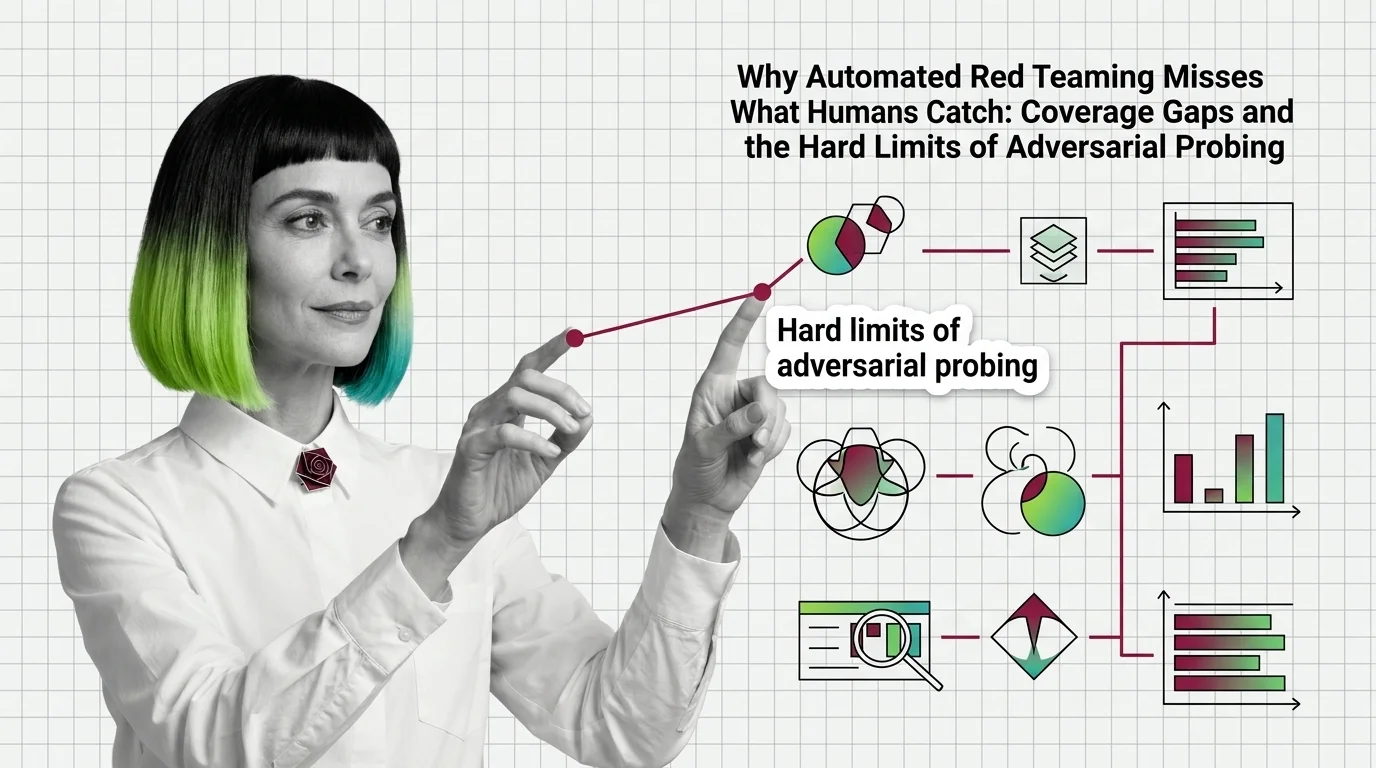
Automated Red Teaming Misses What Humans Catch: Coverage Gaps
Automated red teaming outperforms human testing but misses critical failures. Coverage gaps explain why automated …

Compressed Intelligence, Unequal Access: The Hidden Costs of Quantized AI
Quantization makes AI accessible but the quality loss isn't evenly distributed. Explore who benefits from compressed …
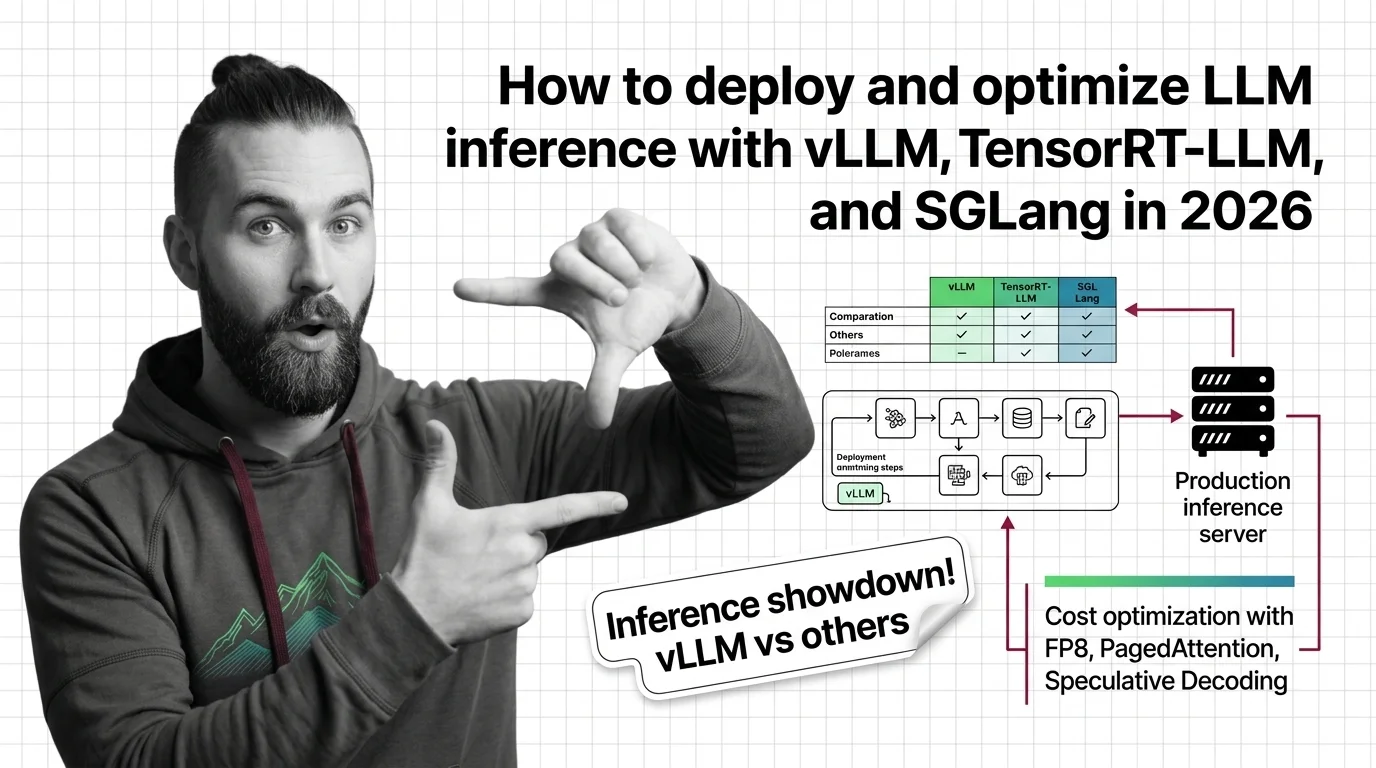
How to Deploy and Optimize LLM Inference with vLLM, TensorRT-LLM, and SGLang in 2026
Deploy production LLM inference with vLLM, TensorRT-LLM, or SGLang. Covers workload profiling, engine selection, FP8 …
How to Quantize and Deploy LLMs with AWQ, GGUF, and vLLM on Any Hardware in 2026
Choose the right LLM quantization format for your hardware. AWQ, GPTQ, and GGUF compared — plus current vLLM and …

How to Red Team an LLM with Promptfoo, PyRIT, and Garak in 2026
Build an LLM red teaming pipeline with Promptfoo, PyRIT, and Garak. Map attack surfaces, run multi-turn tests, and score …
How to Train and Evaluate a Reward Model with OpenRLHF, TRL, and RewardBench 2 in 2026
Train a reward model using TRL or OpenRLHF, then evaluate with RewardBench 2. Spec-first guide covering architecture, …
LLM Training for Developers: Which Instincts Help, Which Mislead
LLM training mapped for software developers. Learn which build-pipeline instincts transfer to pre-training, fine-tuning, …
Opaque Defaults and Locked Knobs: The Ethics of Who Controls LLM Sampling Parameters
Major LLM providers are locking sampling parameters like temperature and top-p. Explore who controls these defaults, …

Request Queues and GPU Access: Who Waits Longest When Continuous Batching Decides
Continuous batching boosts GPU throughput, but its scheduling quietly decides who waits. Examining fairness, priority, …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.