Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles
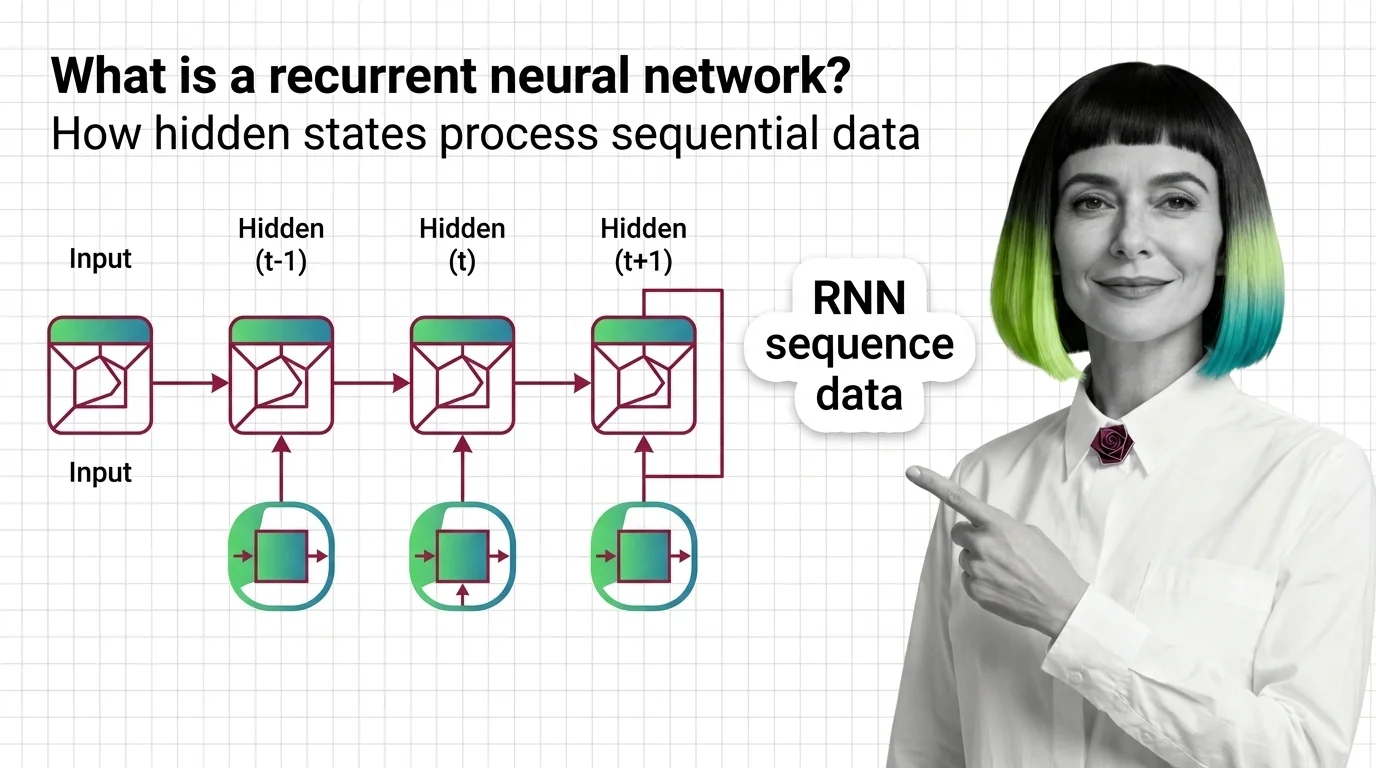
What Is a Recurrent Neural Network and How Hidden States Process Sequential Data
RNNs use hidden states to carry memory across time steps. Learn how recurrent neural networks process sequences, why …

Benchmark Contamination, Score Divergence, and the Technical Limits of LLM Evaluation Harnesses
Same model, same benchmark, different scores. Understand why evaluation harnesses diverge and how benchmark …

How to Benchmark LLMs with lm-evaluation-harness, HELM, and OpenCompass in 2026
Choose the right LLM evaluation harness — lm-evaluation-harness, HELM, or OpenCompass — with a spec-first workflow for …
Inspect AI, DeepEval, and the Open-Source Evaluation Race Reshaping LLM Benchmarking in 2026
LLM evaluation has split into three lanes: government safety, enterprise CI/CD, and academic benchmarks. Here's who …
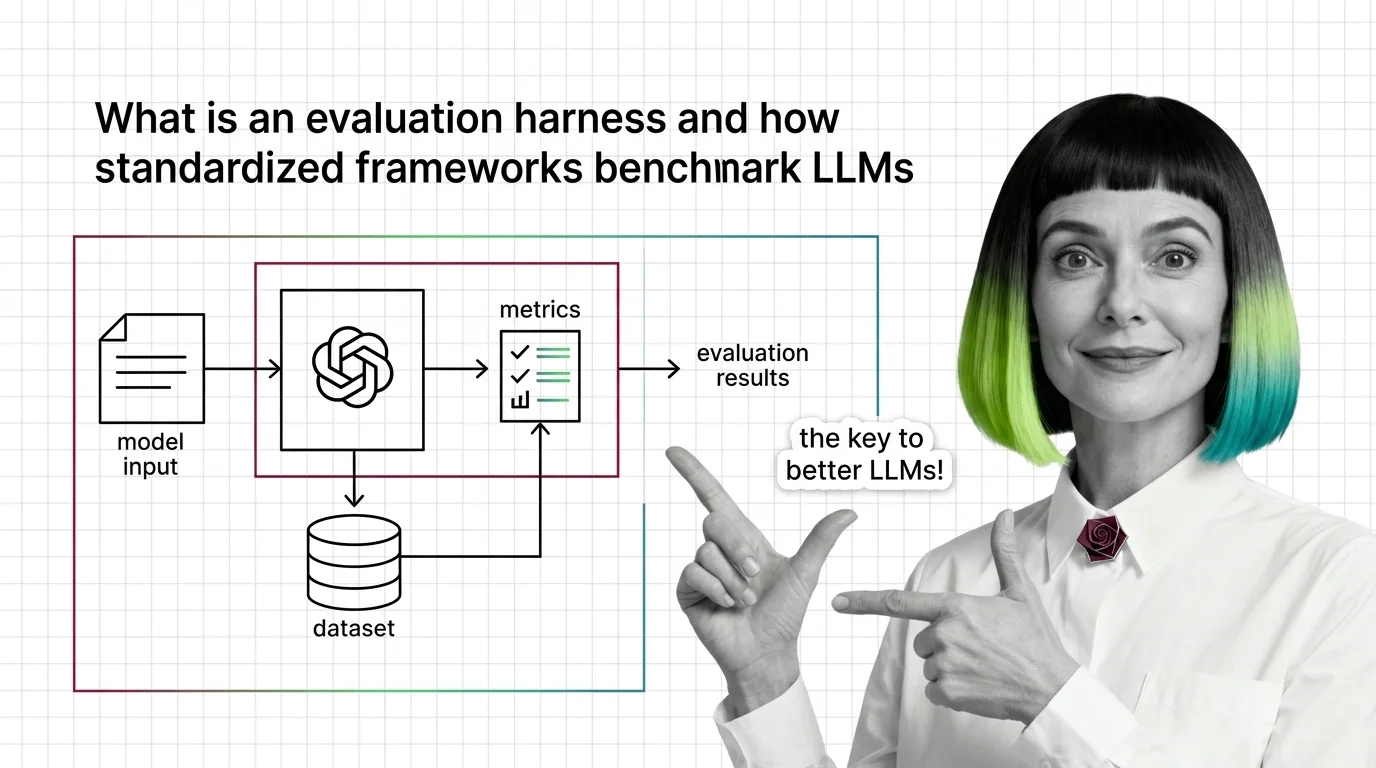
What Is an Evaluation Harness and How Standardized Frameworks Benchmark LLMs
Evaluation harnesses standardize LLM benchmarking by fixing prompts, scoring, and conditions. Learn how the pipeline …

Who Decides What Gets Measured: The Accountability Gap in Standardized LLM Evaluation
Standardized LLM evaluation harnesses shape which AI models succeed, yet their design choices go unaudited. Explore the …

Benchmark Contamination: N-Gram Overlap and Hard Limits
Benchmark contamination and overfitting look identical in scores. Understand what n-gram overlap, deduplication, and …

How to Detect and Prevent Benchmark Contamination with CoDeC, CCV, and LiveBench in 2026
Detect benchmark contamination in LLMs using CoDeC, CCV, and LiveBench. A step-by-step workflow for auditing evaluations …

MMLU Leakage, LiveCodeBench, and the 2026 Race to Build Contamination-Proof AI Evaluation
MMLU scores dropped up to 17 points when contamination was removed. How LiveBench, MMLU-CF, and new detection methods …
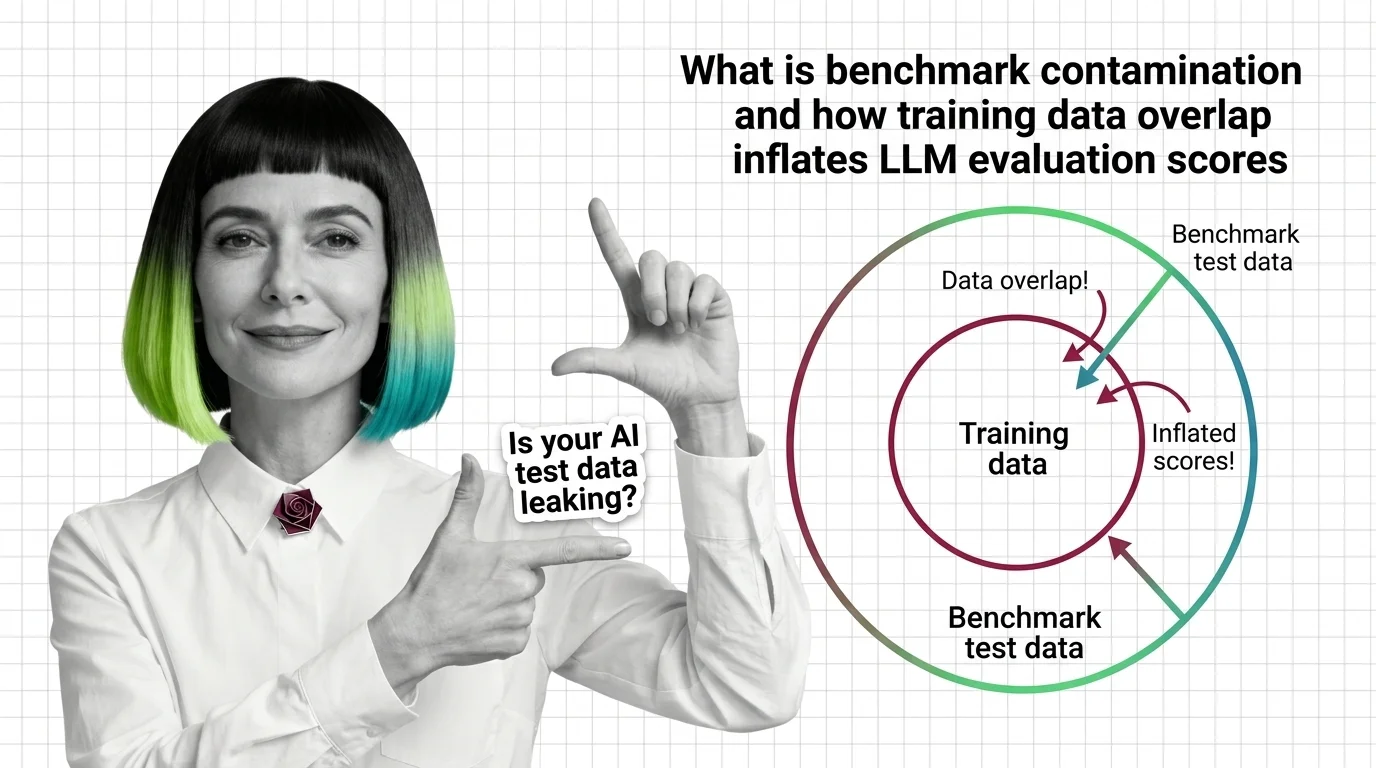
What Is Benchmark Contamination and How Training Data Overlap Inflates LLM Evaluation Scores
Benchmark contamination inflates LLM scores when training data overlaps with test sets. Learn how data leaks in and why …

Inflated Scores, Misplaced Trust: The Ethical Cost of Benchmark Contamination in AI Procurement
Inflated benchmark scores shape AI procurement in healthcare and finance. An ethical examination of contamination, …
Ablation Studies: From ResNet to AblationMage Analysis by 2026
Ablation studies evolved from manual methods to LLM-powered tools. Track the shift from ResNet to AblationMage and the …
From Baselines to Factorial Design: Prerequisites and Core Components of Ablation Experiment Design
Ablation studies reveal which components matter, but only with the right baselines, controls, and statistical methods. …

How to Design and Run Rigorous Ablation Experiments with ABLATOR, W&B Sweeps, and PyTorch in 2026
Design rigorous ablation experiments with ABLATOR, W&B Sweeps, and PyTorch 2.11. Specify, isolate, and prove which of …
Selective Reporting and Missing Baselines: How Incomplete Ablation Undermines AI Research Credibility
Selective ablation reporting hides whether AI breakthroughs are real. Explore how missing baselines erode research trust …
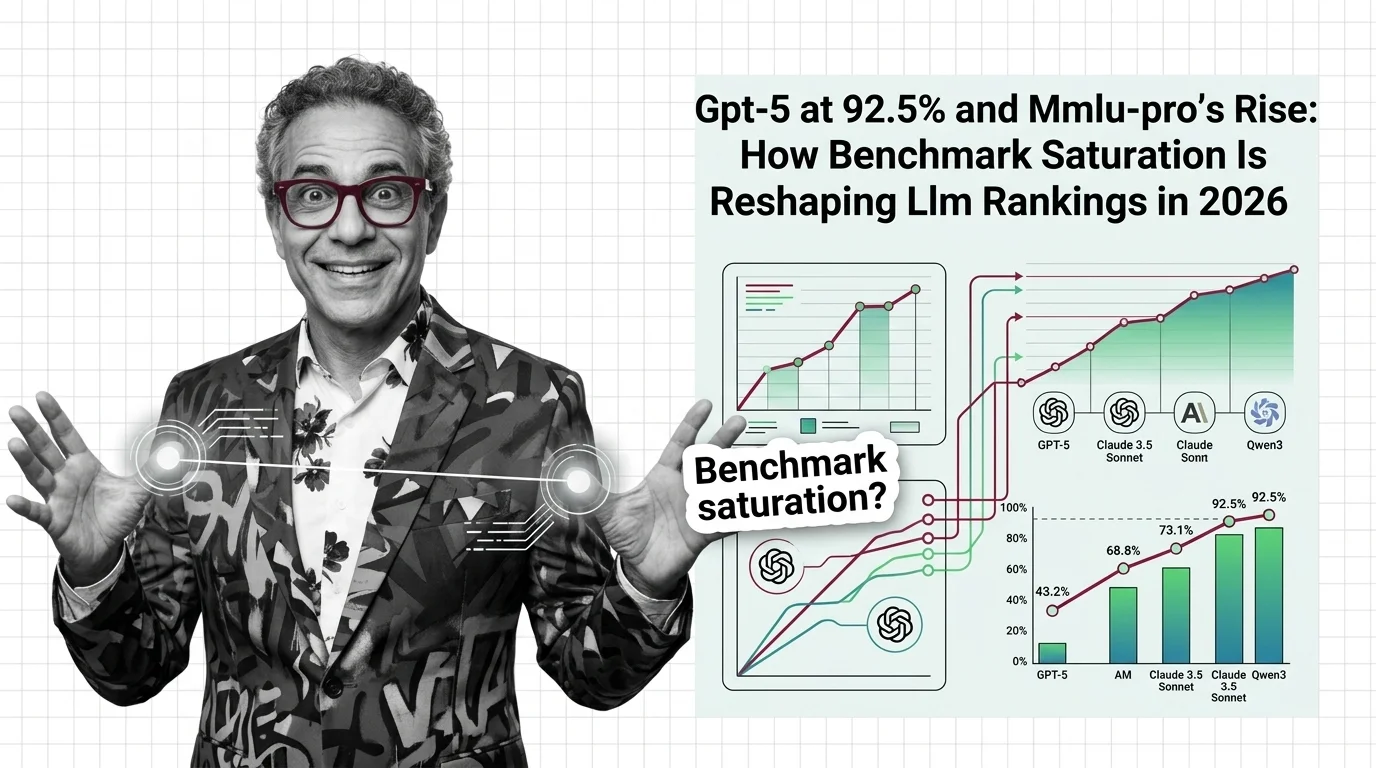
GPT-5 at 92.5% and MMLU-Pro's Rise: How Benchmark Saturation Is Reshaping LLM Rankings in 2026
Frontier LLMs cluster within 4 points on MMLU, making the benchmark useless for differentiation. See how saturation is …
How to Run MMLU Evaluation and Interpret Benchmark Scores for Model Selection in 2026
Run MMLU and MMLU-Pro evaluations correctly, avoid common configuration mistakes, and interpret benchmark scores to …
The Benchmark Trap: How MMLU Optimization Drives Data Contamination and Rewards Western Academic Bias
MMLU scores dominate AI headlines, but data contamination and cultural bias undermine what they actually measure. An …

Accuracy Theater: How Confusion Matrices Obscure Bias in High-Stakes AI Decisions
Overall accuracy hides who bears the cost of AI errors. Explore how confusion matrices obscure racial and gender bias in …

Class Imbalance, Normalization Traps, and the Hard Limits of Confusion Matrix Analysis
Confusion matrices hide failures under class imbalance. Learn how normalization direction changes what you see and why …
Combinatorial Explosion, Interaction Effects, and the Hard Limits of Ablation Studies at Scale
Ablation studies hit a wall at scale: combinatorial explosion and non-additive interactions make exhaustive testing of …

Confusion Matrices: scikit-learn, TorchMetrics & W&B (2026)
Specify, build, and validate confusion matrix pipelines with scikit-learn 1.8, TorchMetrics 1.9, and Weights & Biases …

Confusion Matrix: Real-World Misclassifications in 2026
COMPAS and FDA recalls demonstrate how confusion matrix analysis shifts from post-mortem diagnostic tools to automated …
From Binary to Multi-Class: Deriving Precision, Recall, and F1 from a Confusion Matrix
The confusion matrix scales from four binary cells to N² in multi-class problems. What the diagonal and margins record …
From Perplexity to Few-Shot Prompting: Prerequisites for Understanding Evaluation Harness Internals
Evaluation harness scores depend on perplexity, few-shot prompting, and tokenization most teams skip. Learn the …

MMLU's 6.5% Label Error Rate and Benchmark Score Saturation
MMLU's 6.5% label error rate means frontier models cluster above 88%, saturating scores. Score saturation explains why …
Model Evaluation for Developers: What Maps and What Misleads
Model evaluation mapped for backend developers. Learn which testing instincts transfer to LLM benchmarks, where scores …

What Is a Confusion Matrix and How It Reveals Where Your Classifier Fails
A confusion matrix reveals exactly where classifiers fail. Understand true positives, false negatives, and why accuracy …
What Is an Ablation Study and How Removing Components Reveals What Makes AI Models Work
Ablation studies reveal what each model component does by removing it. Learn the experimental design and failure modes …
What Is the MMLU Benchmark and How 57 Academic Subjects Test LLM Knowledge
MMLU tests large language models across 57 academic subjects with 15,908 questions. Learn how it works, where it breaks, …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.