Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles
How to Build a Graph Neural Network with PyTorch Geometric and DGL in 2026
Specify graph neural networks for AI-assisted development. Covers PyTorch Geometric and DGL decomposition, data …
Oversmoothing, Scalability Walls, and the Hard Technical Limits of Graph Neural Networks
Oversmoothing and neighbor explosion set hard ceilings on graph neural network depth and scale. Learn the mathematical …
PyG vs DGL, GNN+LLM Fusion, and Where Graph Neural Networks Are Heading in 2026
NVIDIA is consolidating on PyG and dropping DGL support. Learn which GNN framework wins, how GNN+LLM fusion changes …
What Is a Graph Neural Network and How Message Passing Propagates Information Across Nodes
Graph neural networks learn from connections, not grids. Understand message passing, how graph convolution differs from …
Amplified Bias and Opaque Connections: The Ethical Risks of Graph Neural Networks in High-Stakes Decisions
Graph neural networks judge people by connections. When those relationships encode historical inequality, bias amplifies …
SD-VAE, VQ-VAE, and NVAE: How Variational Autoencoders Power Image Generation in 2026
SD-VAE evolved from 4 to 32 channels while rivals eliminate the encoder entirely. See which VAE strategies lead image …
Synthetic Faces and Learned Distributions: The Ethical Risks When VAEs Recreate Private Data
Variational autoencoders can memorize and recreate private training data. Why synthetic faces and medical records are …
From Autoencoders to KL Divergence: Prerequisites and Hard Limits of Variational Autoencoders
Learn the math behind variational autoencoders — KL divergence, ELBO, the reparameterization trick — and why VAEs blur …

How to Build a VAE in PyTorch and Apply It to Anomaly Detection and Data Augmentation in 2026
Build a variational autoencoder in PyTorch 2.11 the specification-first way. Decompose, specify, and validate your VAE …
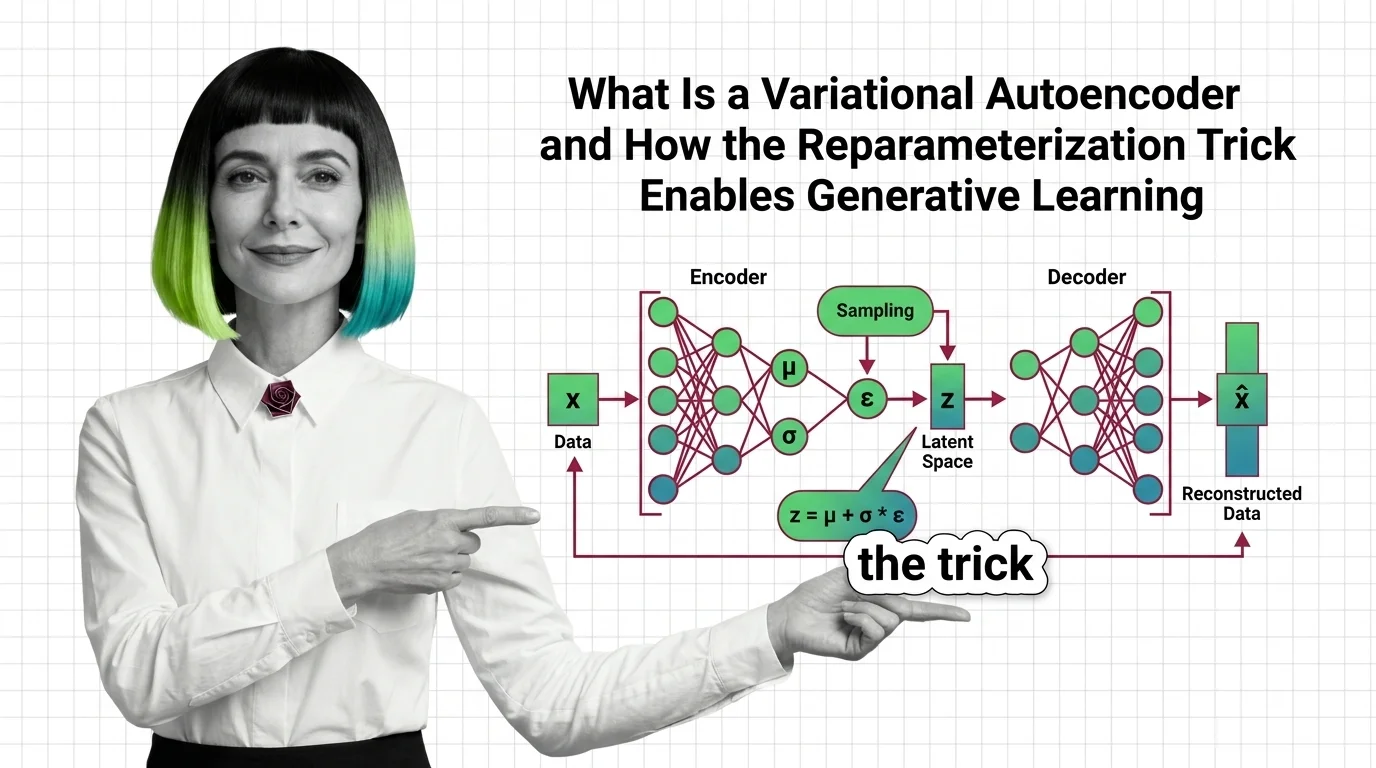
What Is a Variational Autoencoder and How the Reparameterization Trick Enables Generative Learning
VAEs compress data into structured probability spaces for generation. Learn how the reparameterization trick and ELBO …
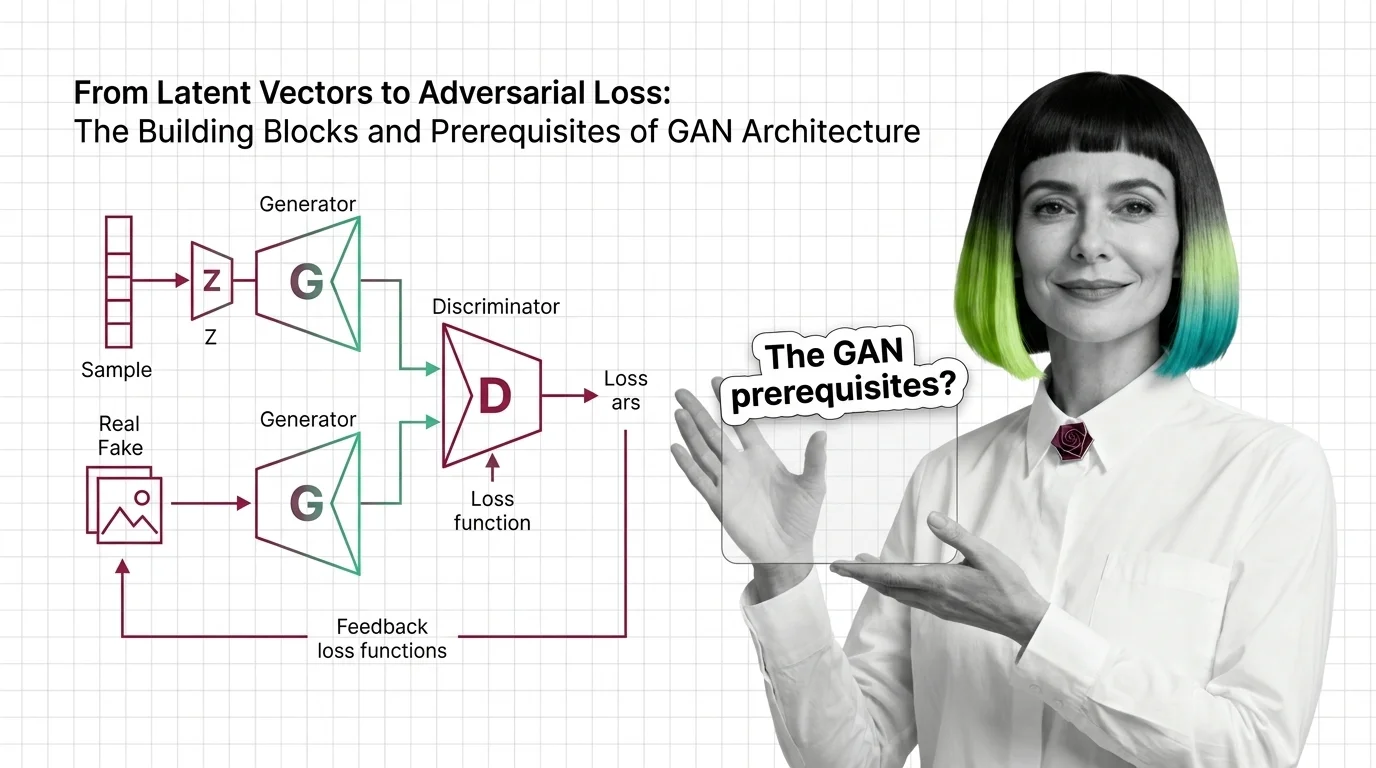
From Latent Vectors to Adversarial Loss: The Building Blocks and Prerequisites of GAN Architecture
Understand GAN architecture from the ground up: generator, discriminator, latent space, and the adversarial loss that …
GigaGAN, Real-ESRGAN, and the Diffusion Rivalry: Where GANs Still Compete in 2026
GANs aren't dead — they're specializing. GigaGAN, Real-ESRGAN, and R3GAN prove adversarial networks still dominate …
How to Build a GAN with PyTorch and Apply It to Super-Resolution and Synthetic Data in 2026
Build a GAN in PyTorch by decomposing the architecture into generator, discriminator, and training loop specs. Covers …
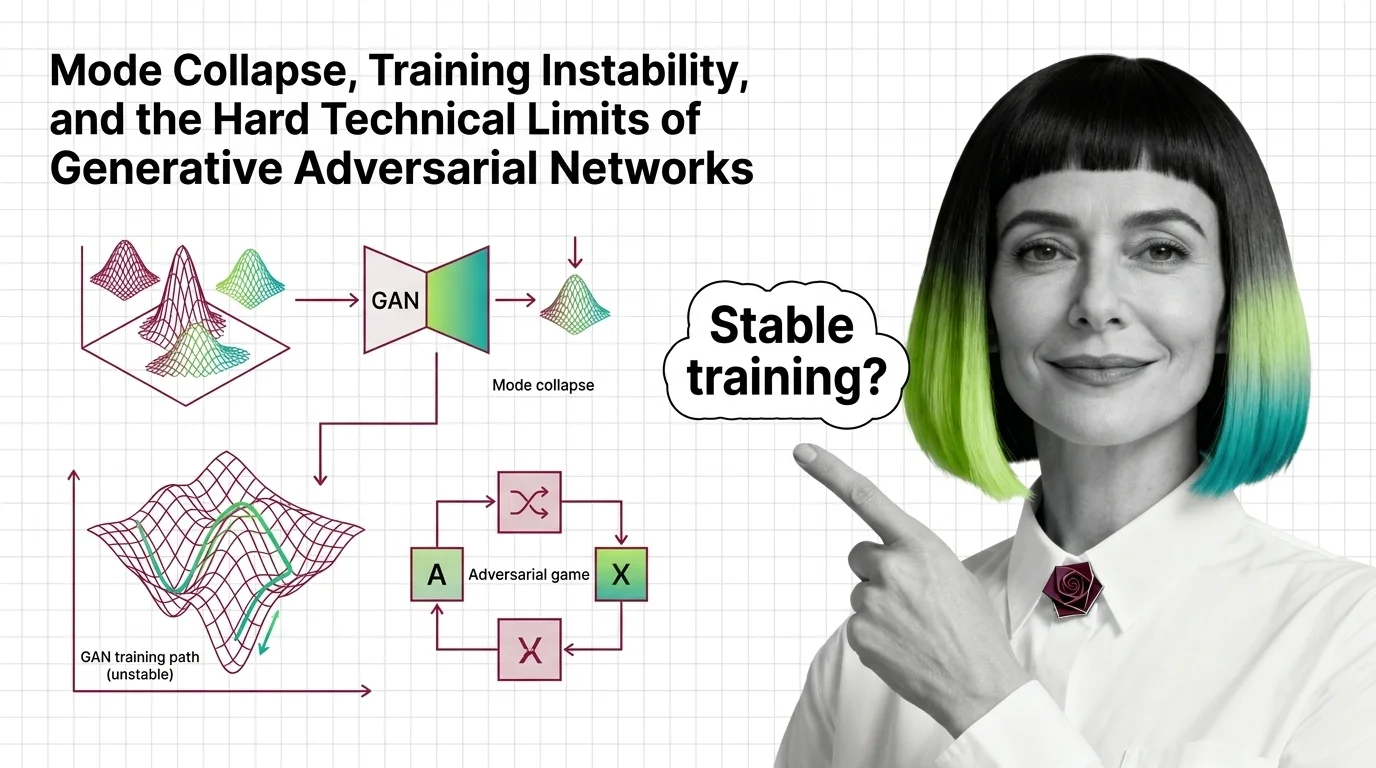
Mode Collapse, Training Instability, and the Hard Technical Limits of Generative Adversarial Networks
Mode collapse and training instability aren't GAN bugs — they're structural limits of adversarial training. Learn the …

Backpropagation Through Time, Vanishing Gradients, and Why Transformers Replaced Recurrent Networks
Gradients decay exponentially in recurrent networks during backpropagation through time. The eigenvalue math behind the …
How to Build an LSTM in PyTorch and Where RNNs Still Outperform Transformers in 2026
Learn when LSTMs beat transformers in 2026 — edge deployment, anomaly detection, time series — and how to specify an …

Sequential Bias and Opaque Memory: The Ethical Risks of Recurrent Networks in High-Stakes Decisions
RNNs carry opaque sequential memory into high-stakes decisions. Explore why hidden states resist auditing and what that …
xLSTM, minLSTM, and the Recurrent Revival: How RNN Ideas Are Challenging Transformers in 2026
xLSTM, minLSTM, and Mamba-3 prove recurrent architectures rival transformer quality at linear cost. What the hybrid …

From LeNet to ConvNeXt: How CNN Architectures Evolved and Where Spatial Inductive Bias Falls Short
Trace CNN evolution from LeNet to ConvNeXt. Understand how spatial inductive bias enables efficient vision but limits …

PyTorch CNN: EfficientNetV2 vs ResNet vs ConvNeXt (2026)
Evaluate EfficientNetV2, ResNet, and ConvNeXt. Get a clear decision framework to choose the right PyTorch model for your …

How to Build a Neural Network Language Model from Scratch with PyTorch in 2026
Decompose a neural network language model into four specification layers for AI-assisted development. Covers …
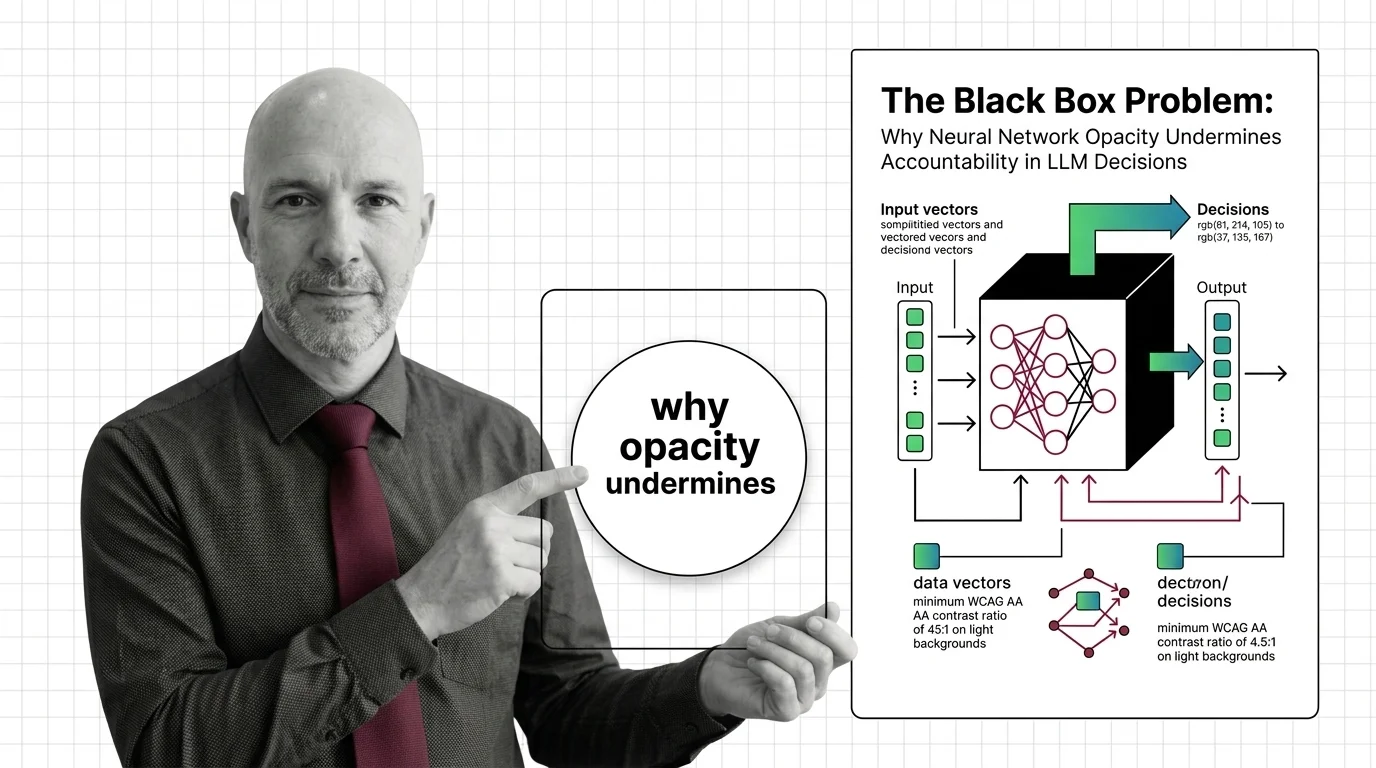
The Black Box Problem: Why Neural Network Opacity Undermines Accountability in LLM Decisions
Neural networks powering LLM decisions are opaque by design. This essay traces why that opacity creates an …

What Is a Neural Network and How It Learns to Generate Language
Neural networks learn language by adjusting millions of weights through backpropagation. Learn how layers, gradients, …
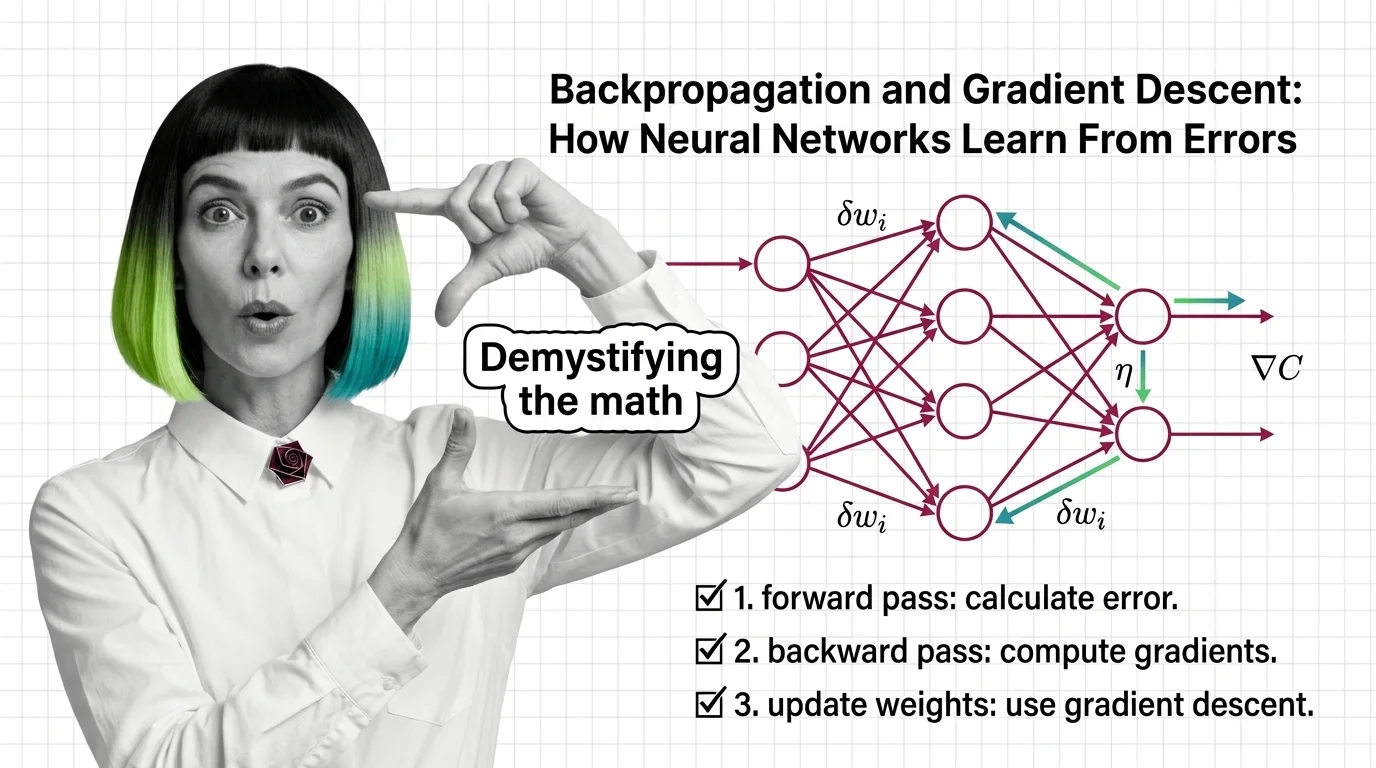
Backpropagation and Gradient Descent: How Neural Networks Learn From Errors
Learn how backpropagation and gradient descent train neural networks by propagating error signals backward through …

From Radiology to Autonomous Vehicles: How CNNs Power Real-World Computer Vision in 2026
CNNs aren't fading — they're merging with transformers and powering FDA-cleared diagnostics, robotaxis, and real-time …
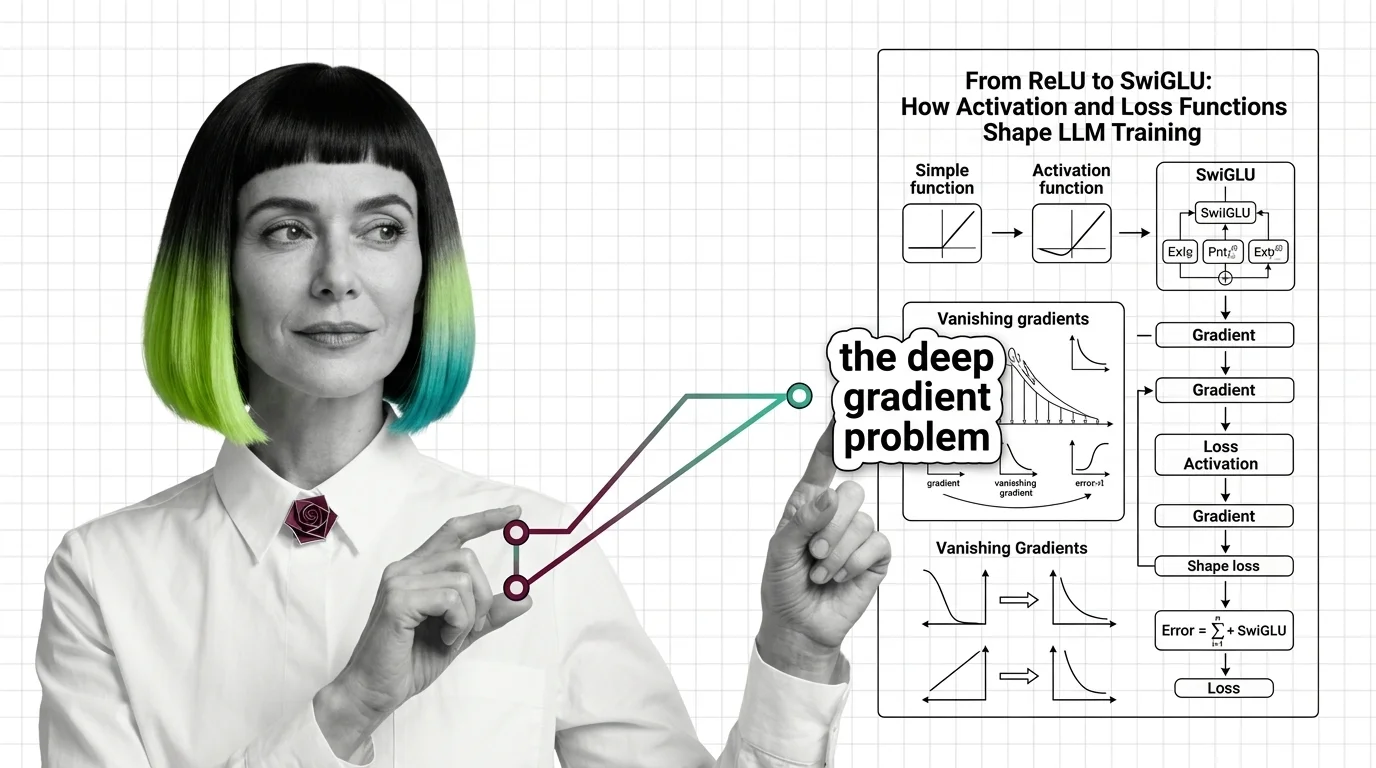
From ReLU to SwiGLU: How Activation and Loss Functions Shape LLM Training
Trace the path from ReLU to SwiGLU and understand how activation functions, cross-entropy loss, and gradient dynamics …
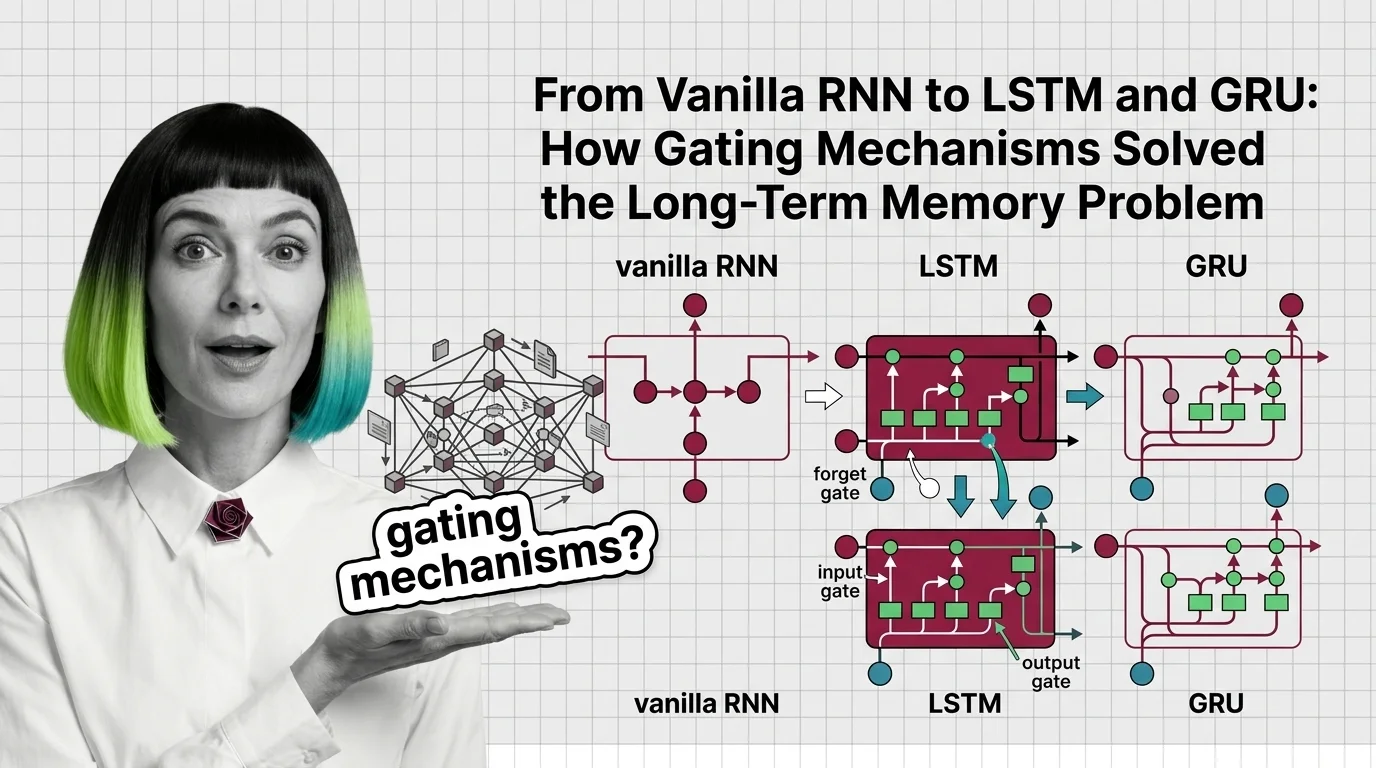
From Vanilla RNN to LSTM and GRU: How Gating Mechanisms Solved the Long-Term Memory Problem
Trace how LSTM forget, input, and output gates fix the vanishing gradient problem that crippled vanilla RNNs, and how …
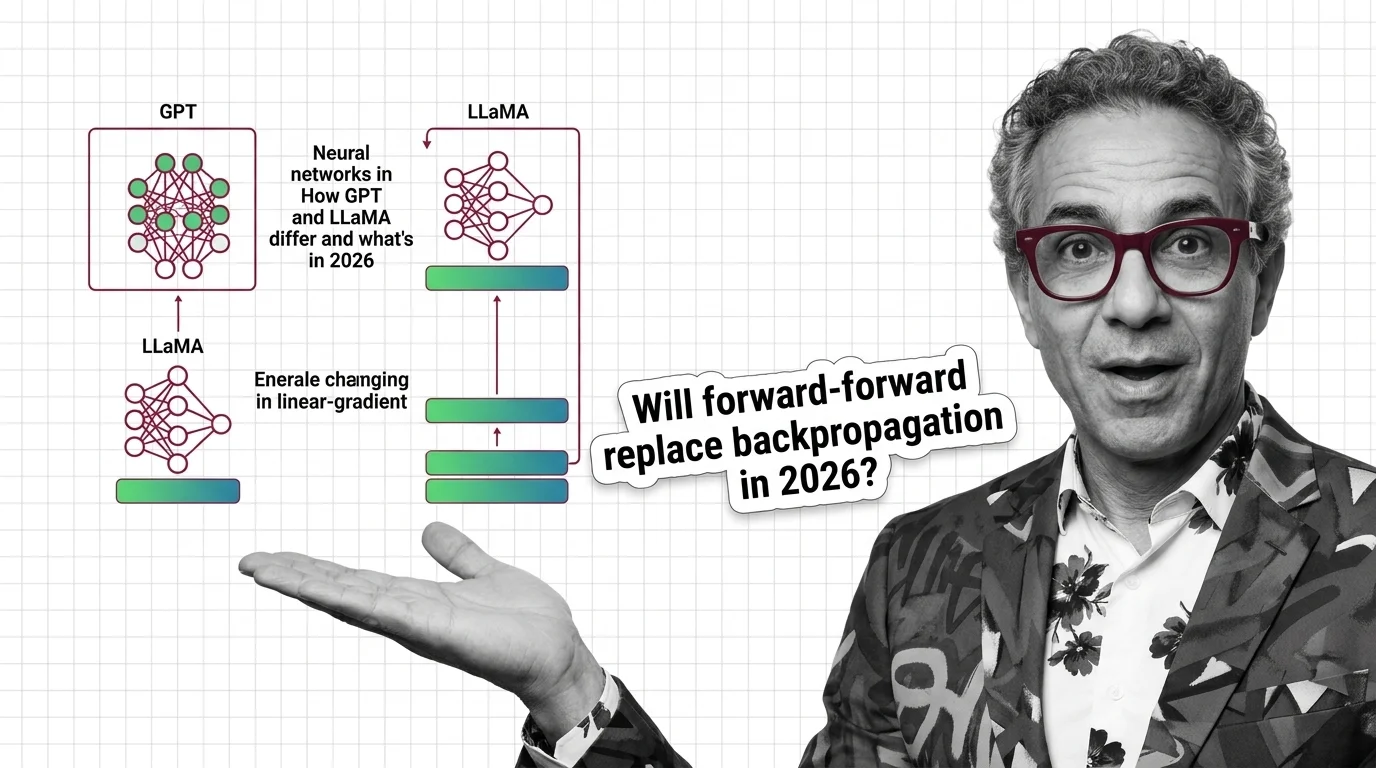
Neural Networks in Action: How GPT and LLaMA Differ and What's Changing in 2026
GPT-5, LLaMA 4, and Gemini 3 all bet on routing and MoE — but their approaches diverge. What the architecture split …

Trained on Bias, Deployed on Faces: The Ethical Cost of CNN-Powered Surveillance Systems
CNN-powered facial recognition hits 98% on benchmarks but fails along racial and gender lines. The ethical cost of …

What Is a Convolutional Neural Network and How Learnable Filters Extract Visual Features
Convolutional neural networks detect visual features through learnable filters, not pixel matching. Understand the …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.