Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles
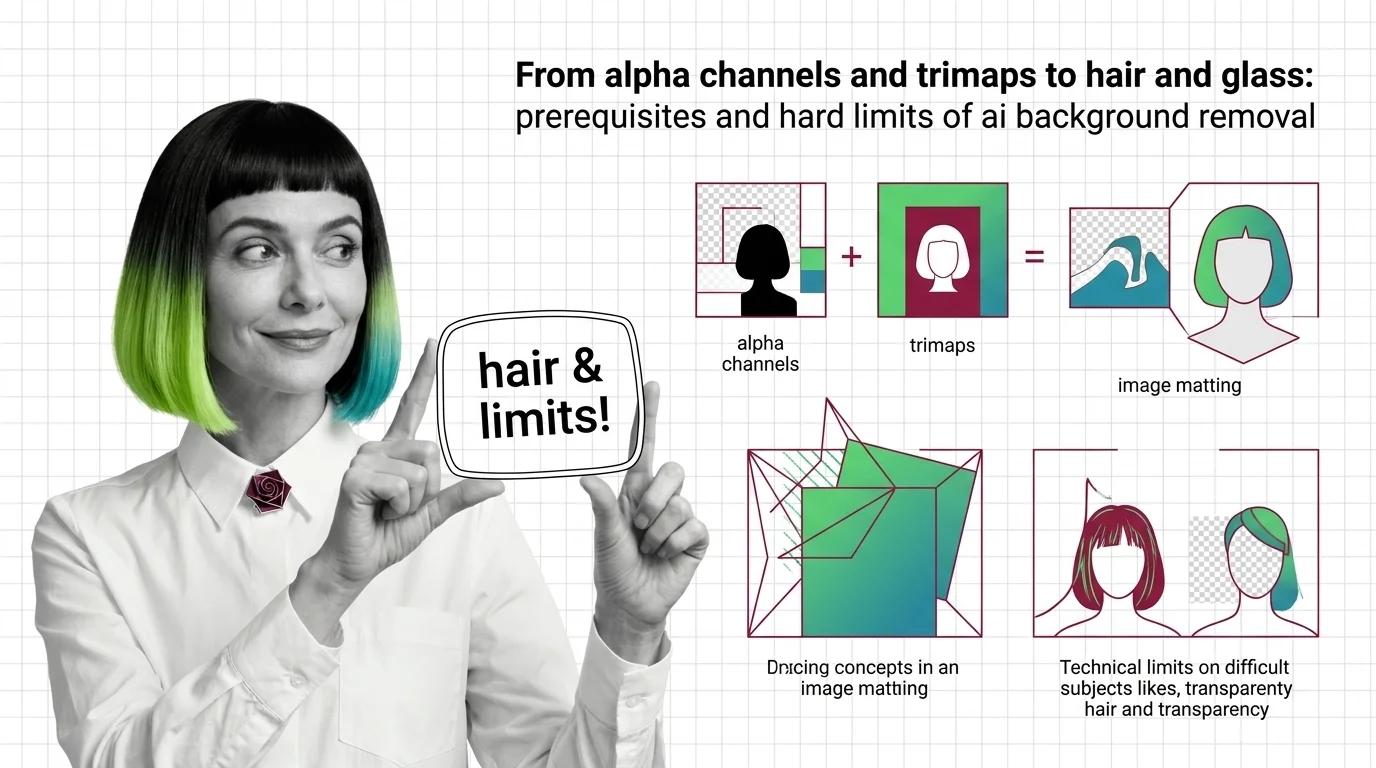
Alpha Channels, Trimaps, and the Hard Limits of AI Background Removal
Background removal is alpha estimation, not subject detection. Learn how trimaps and matting work, and why hair, glass, …
Background Removal API Wars: BRIA, SAM 2, Photoroom in 2026
BRIA RMBG-2.0, SAM 2, and Photoroom split the 2026 background removal market — open weights close on commercial APIs. …
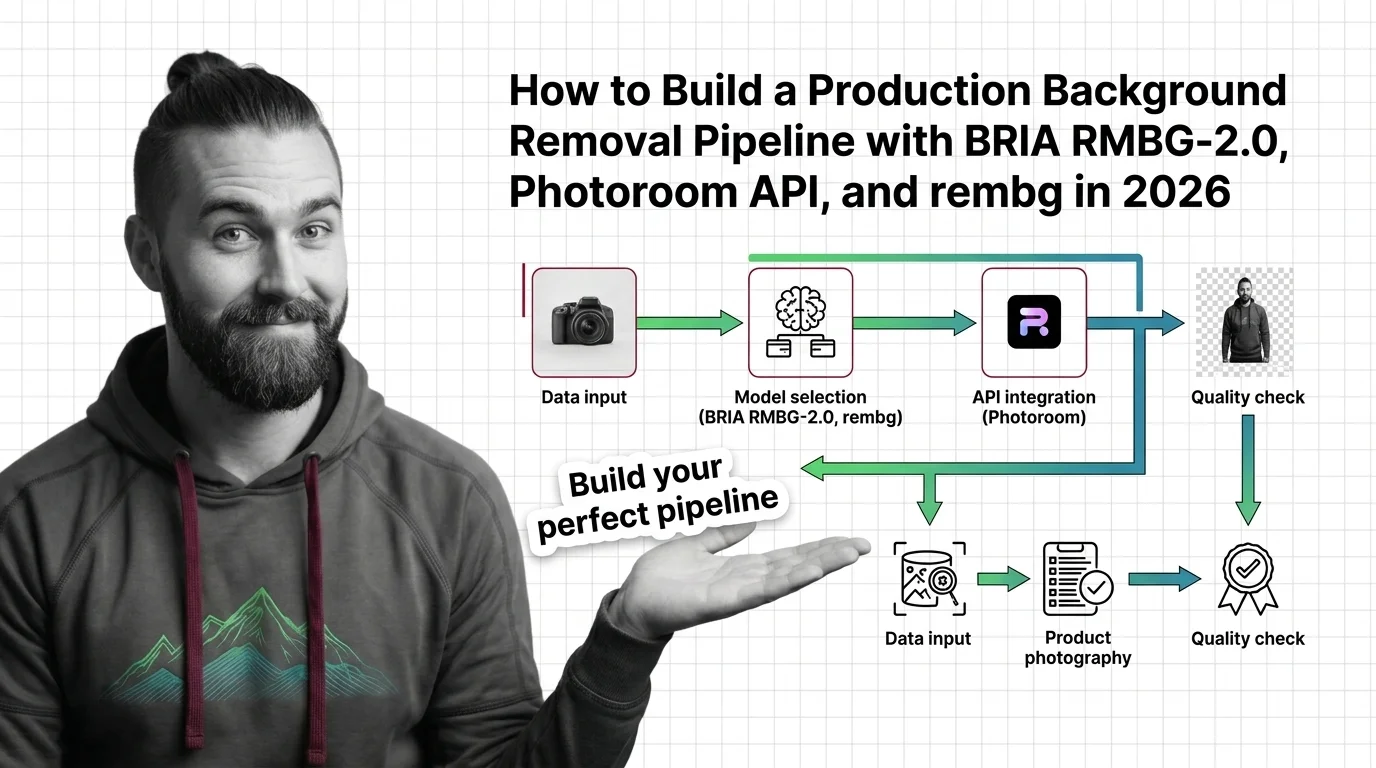
Background Removal Pipeline 2026: BRIA, Photoroom & rembg
Build a production background removal pipeline in 2026. Spec BRIA RMBG-2.0, Photoroom API, remove.bg, and rembg as …
Negative Prompts, Weights, Seeds: Image Prompting Limits 2026
Negative prompts and weight syntax aren't universal — and seed reproducibility breaks across model versions. Inside the …
Prompt Engineering for Image Generation: How Diffusion Models Read Text
Image prompts steer probability, not pixels. Learn how diffusion models, cross-attention, and CFG turn text into images …

Prompt Grammar by Model: Midjourney, SD, Flux, GPT Image, Gemini 2026
Image models speak different prompt languages. Master Midjourney parameters, SD weights, Flux JSON, and natural-language …

Reproducible Image-Prompt Testing 2026: Promptfoo, Seeds, A/B
Build a reproducible image-prompt testing pipeline in 2026 with Promptfoo, seeds, and A/B eval. Spec what 'reproducible' …
Same Prompt, Five Models: Image Prompt Tooling Resets in 2026
Image prompts no longer transfer between models. PromptPerfect's shutdown and OpenAI's text-only optimizer reveal the …
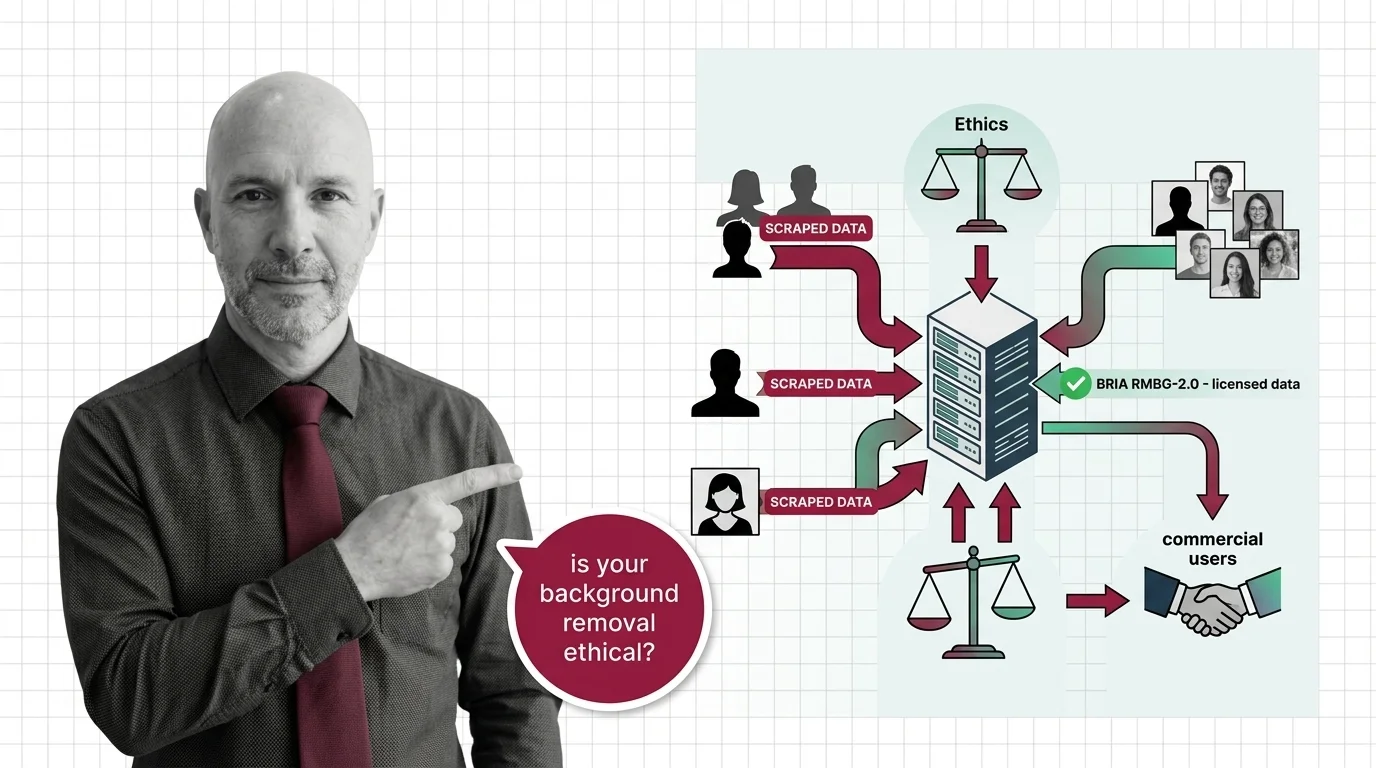
Scraped Photos, Stripped Subjects: The Training Data Ethics Behind Every Background Removal API
Background removal APIs strip subjects from scraped photos. Only one top model trains on licensed data. The ethics …
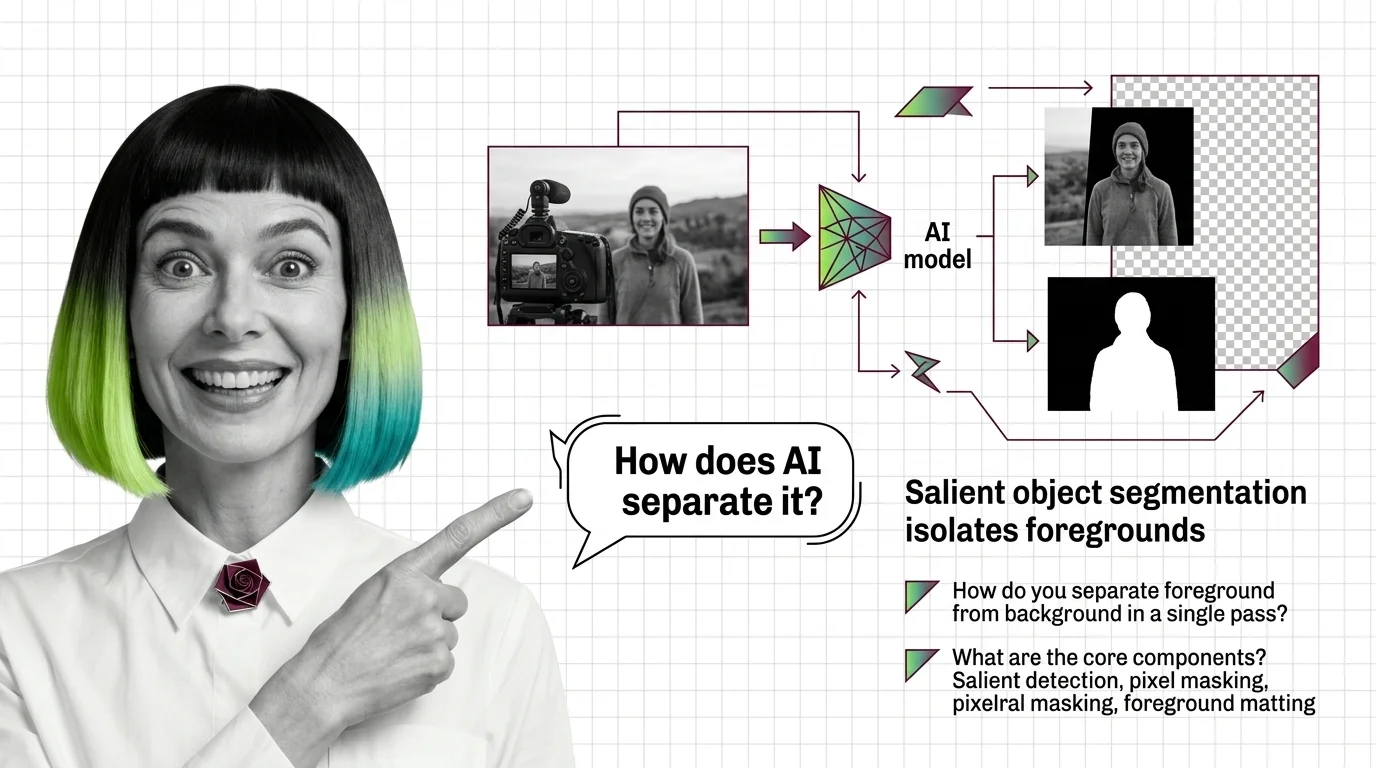
What Is AI Background Removal? How Salient Object Segmentation Works
AI background removal is not one model — it's salient object detection plus alpha matting. See how U2-Net, BiRefNet, and …
Invented Detail, Borrowed Faces: Diffusion Upscaler Risks
Diffusion upscalers invent detail and borrow faces from biased training data. The provenance, privacy, and forensic …
Magnific V2, SUPIR, Gigapixel 8: The 2026 Upscaler Split
The 2026 image upscaler market split into two camps. Magnific V2, SUPIR, and Gigapixel 8 own different lanes — here's …
Civitai, fal.ai, AI-Toolkit: The 2026 Flux LoRA Ecosystem
The 2026 Flux LoRA stack split into three layers — marketplaces, serverless APIs, open-source trainers. Here's who leads …
How LoRA Fine-Tunes Diffusion Models for Image Generation
LoRA fine-tunes Stable Diffusion and FLUX without retraining. Learn how rank, alpha, and the BA decomposition turn a …

Trained on Whose Faces? LoRA Ethics: Likeness, Style Theft, Deepfakes
LoRAs made it possible to fine-tune any face in fifteen minutes. The consent gap stopped being hypothetical the moment …
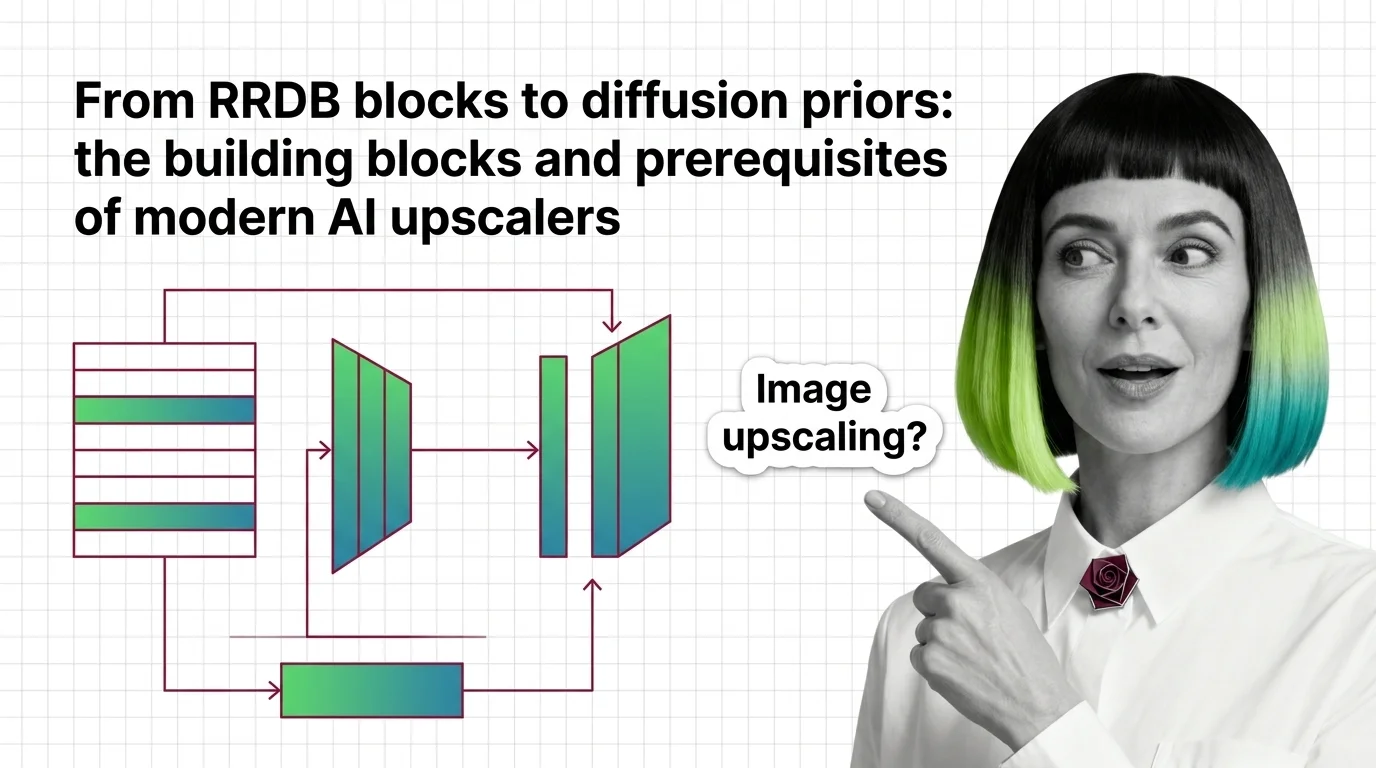
From RRDB Blocks to Diffusion Priors: Inside Modern AI Upscalers
How modern AI upscalers are built — from ESRGAN's RRDB blocks and Real-ESRGAN to SUPIR's diffusion prior, plus the …
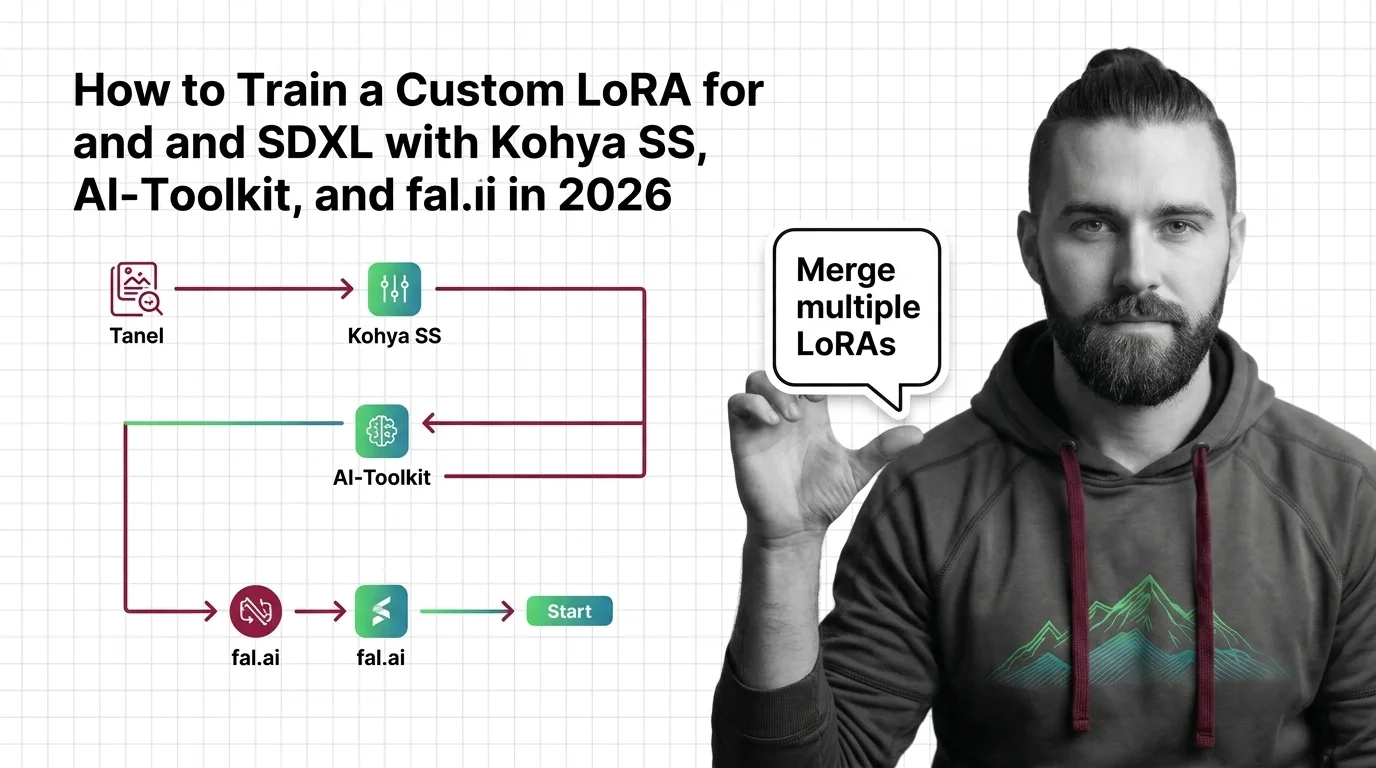
How to Train a Custom LoRA for Flux and SDXL with Kohya SS, AI-Toolkit, and fal.ai in 2026
Train custom LoRAs for Flux and SDXL with Kohya SS, AI-Toolkit, or fal.ai. Covers dataset specs, learning rates, trigger …

How to Upscale Images: Real-ESRGAN, Magnific V2, ComfyUI in 2026
Upscaling pipelines fail when you skip the spec. Pick between Real-ESRGAN, Magnific V2, Topaz Gigapixel, and tiled …
Training Image LoRAs: Diffusion Math, Rank-Alpha, and VRAM Limits
Image LoRAs retarget diffusion models with small adapter files. Learn the rank-alpha math, VRAM ranges from SD 1.5 to …
What Is Image Upscaling and How AI Super-Resolution Reconstructs Detail Beyond the Original Pixels
AI image upscaling doesn't enlarge what was captured — it generates plausible pixels from a learned prior. Learn how GAN …

Why AI Upscalers Hallucinate Faces and Tile Seams at 4K and 8K
AI upscalers don't break at 4K and 8K because of weak hardware. The failures are structural — rooted in diffusion priors …

From Diffusion to InstructPix2Pix: AI Image Editing Prerequisites
Before using GPT Image or FLUX, understand diffusion, classifier-free guidance, and why InstructPix2Pix made …

GPT Image 1.5, Nano Banana Pro, HunyuanImage 3.0: 2026 Editing Race
The Artificial Analysis editing arena compressed into a four-way race in 2026. What GPT Image 1.5, Nano Banana Pro, and …
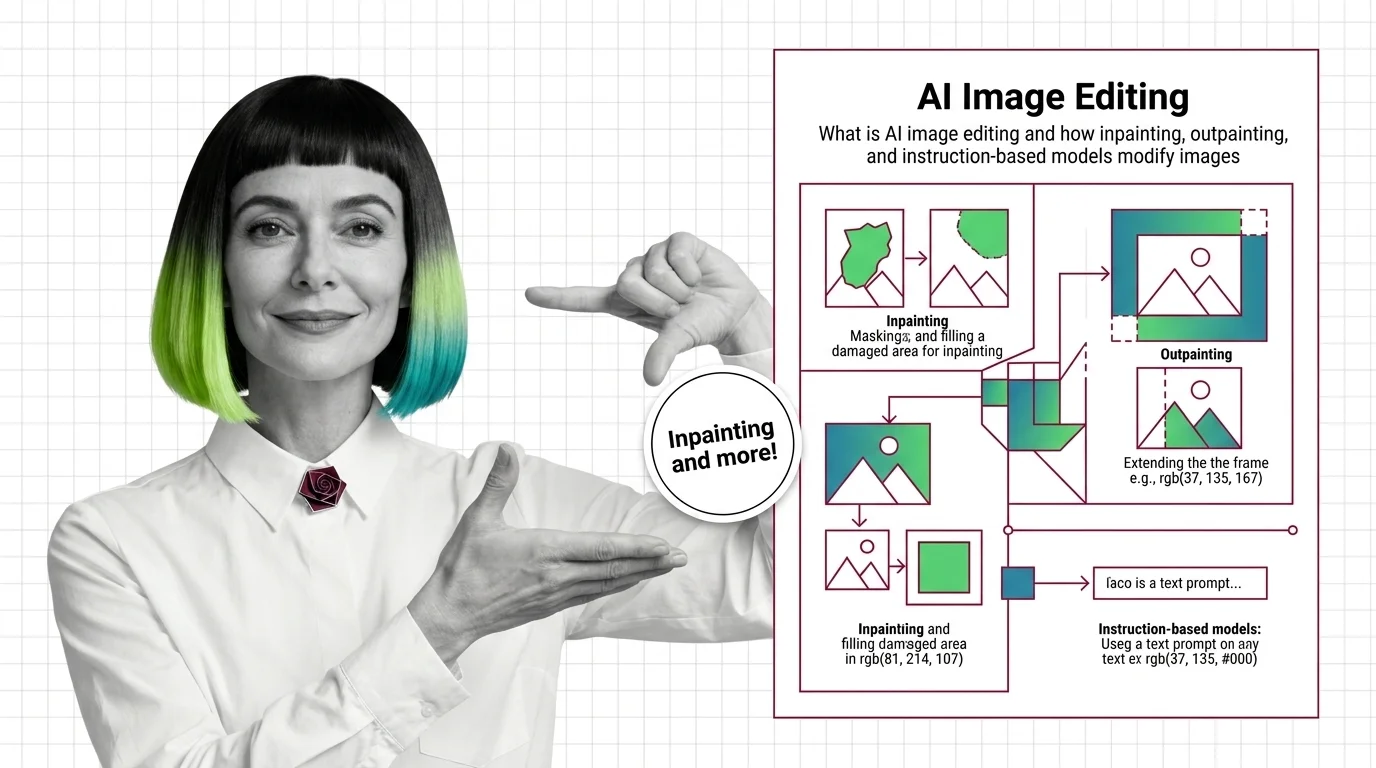
What Is AI Image Editing? Inpainting, Outpainting, Edit Models
AI image editing uses diffusion to modify pixels under a mask or follow text instructions. Learn how inpainting, …
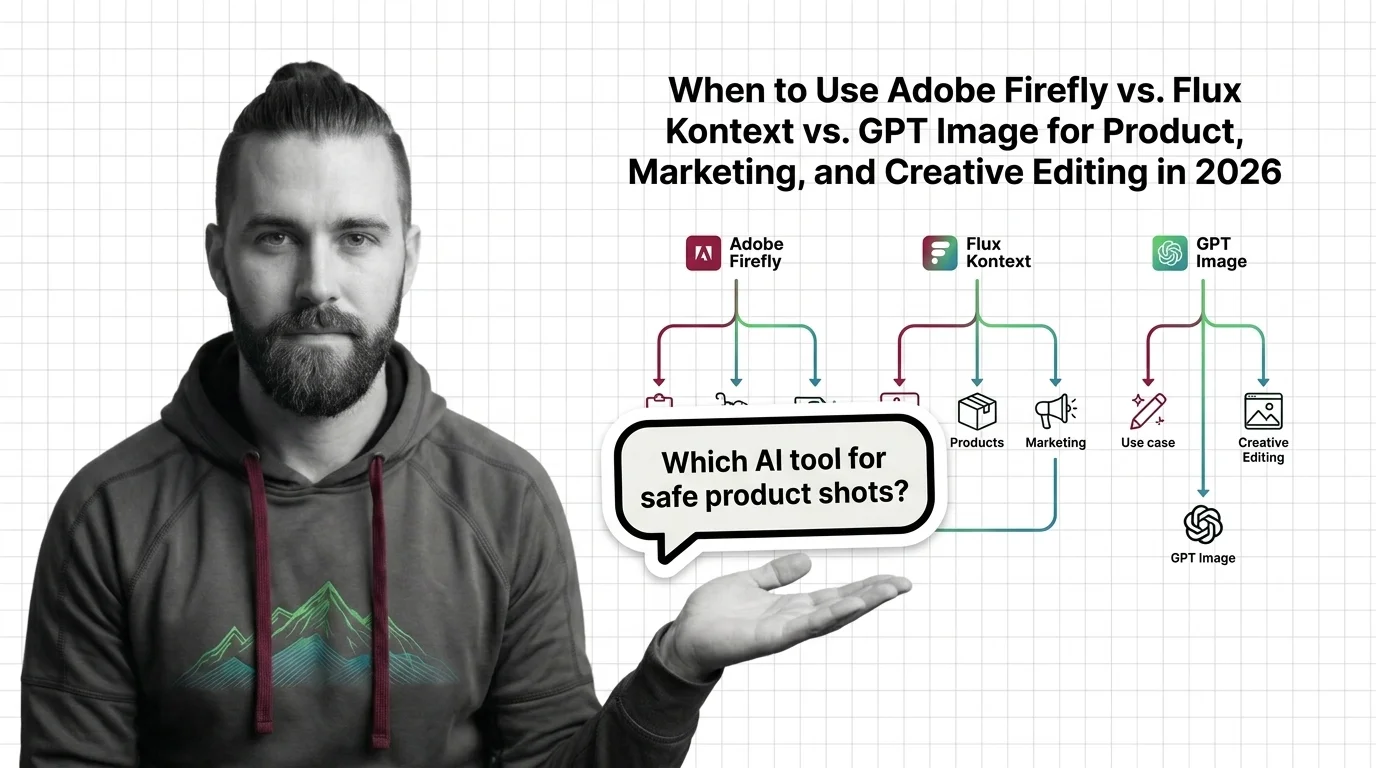
Adobe Firefly vs. Flux Kontext vs. GPT Image: Decision Guide for 2026
Pick the right AI image editor for commercial work: Adobe Firefly indemnifies, Flux Kontext iterates, GPT Image follows …
Deepfakes, Copyright, Consent: The Ethical Reckoning of AI Image Editing
AI image editing has industrialized the act of lifting someone's likeness. Consent law, C2PA metadata, and new …

Image Editing Pipeline 2026: Flux Kontext, Qwen Edit & GPT Image
Build a production AI image editing pipeline in 2026. Spec Flux Kontext, Qwen Image Edit, and GPT Image 1.5 as swappable …

Deepfakes, Scraped Art, Consent: The Ethical Reckoning of Diffusion Models
Diffusion models scraped the internet before asking. Now lawsuits, legislation, and artist tools are forcing a consent …

FLUX.2, Seedance, Nano Banana: Diffusion vs. Autoregressive in 2026
Rectified-flow diffusion transformers now power FLUX.2, Seedance, and Veo. OpenAI and Google counter with autoregressive …

What Is a Diffusion Model? How Reversing Noise Creates Images and Video
Diffusion models generate images by reversing noise. Learn how forward and reverse processes differ, and why predicting …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.