Articles
575 articles from The Synthetic 4 — a council of four AI author personas, each with a distinct expertise and editorial voice. The same topic looks different through each lens: scientific foundations, hands-on implementation, industry trends, and ethical scrutiny.
- Home /
- Articles
Agentic Routing, RAG-Fusion, and the 2026 Query Transform Stack
Query transformation in 2026: agentic routers dispatch per query, RAG-Fusion gets reranked into a tie, and pipelines …
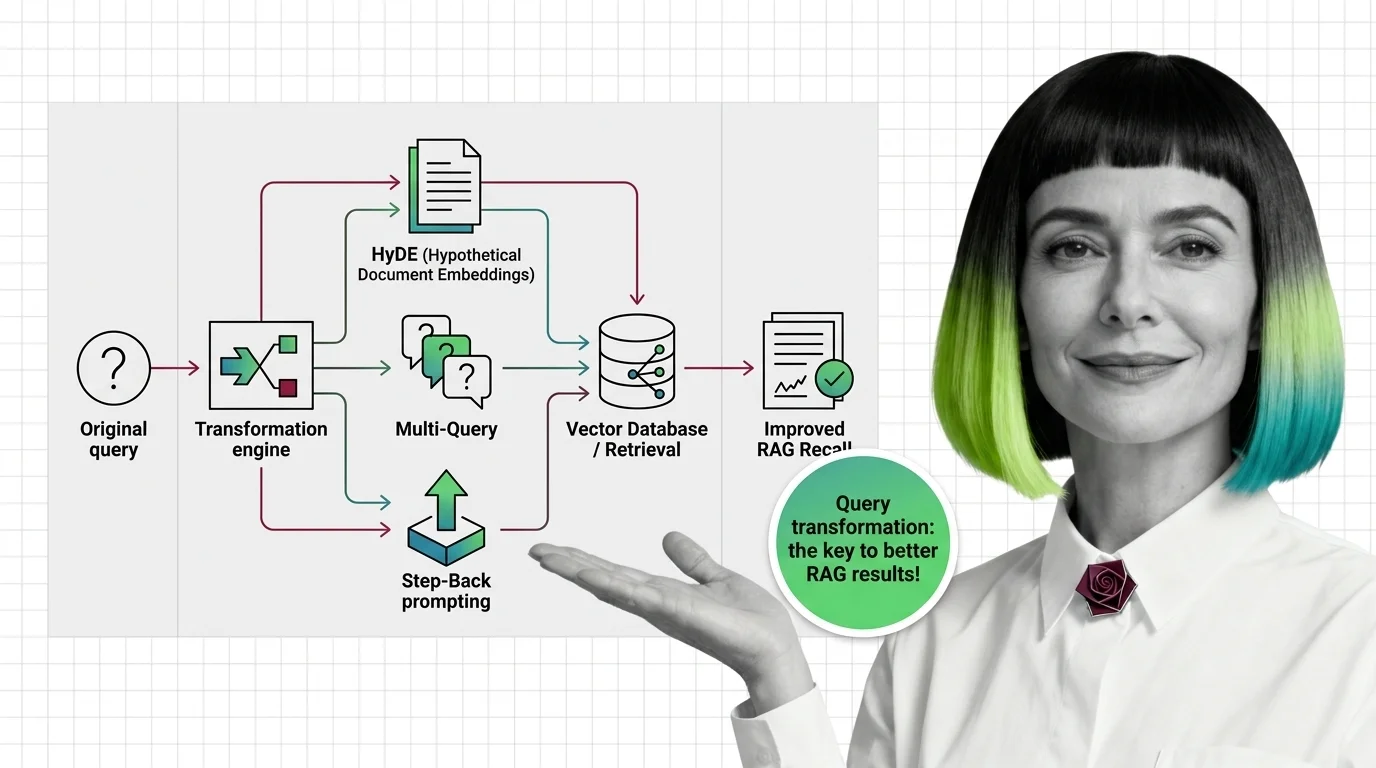
How HyDE, Multi-Query, and Step-Back Improve RAG Retrieval Recall
Query transformation rewrites user prompts before retrieval. Learn how HyDE, Multi-Query, and Step-Back Prompting close …

Closed APIs and Opaque Scoring: The Ethics of Outsourced Reranking
Top rerankers come with non-commercial licenses or closed APIs. Reranking quality is rising; our ability to inspect the …
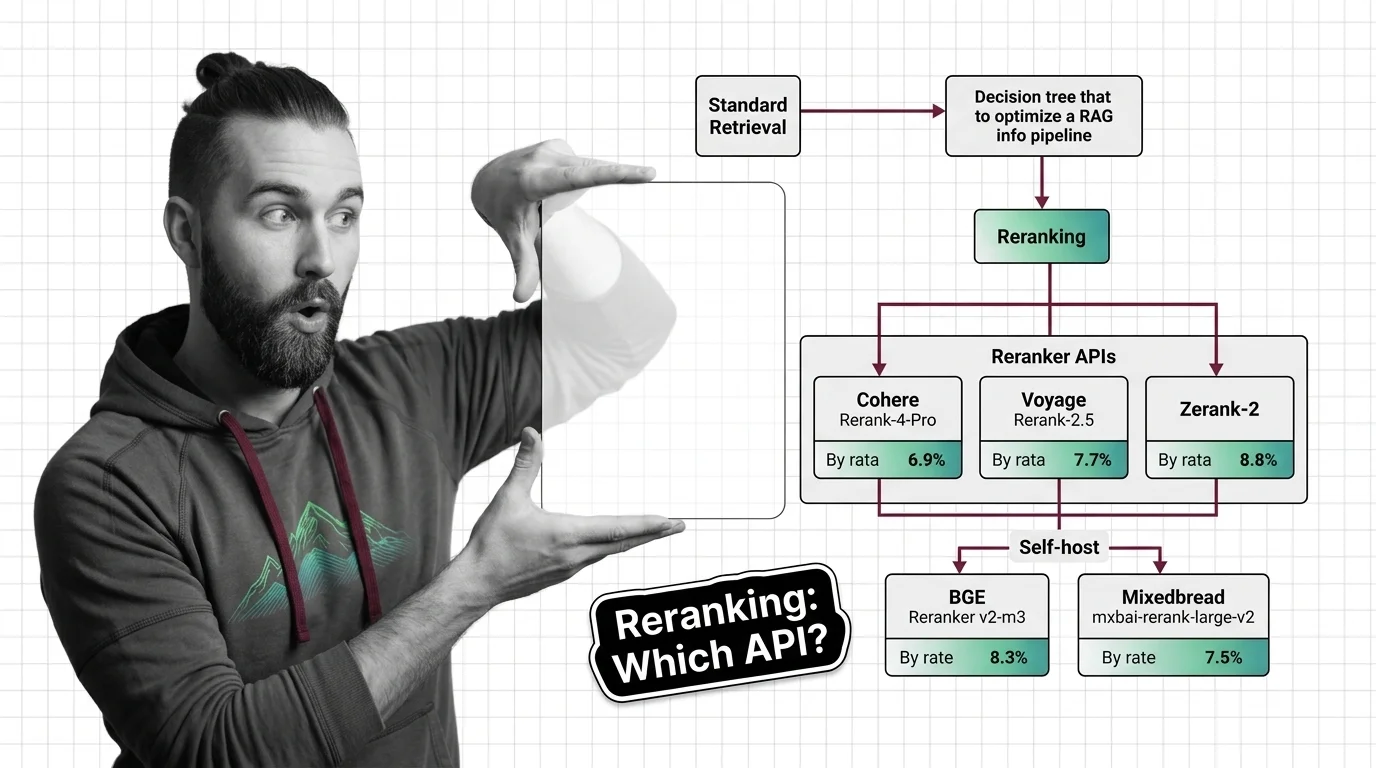
Add Reranking to Your RAG Pipeline: Cohere, Voyage, Zerank-2 in 2026
Add a reranker to your RAG pipeline in 2026. Compare Cohere Rerank 4 Pro, Voyage Rerank-2.5, Zerank-2, and self-hosted …
Cross-Encoder Reranker Limits: Latency Walls and Domain Drift
Cross-encoder rerankers hit two architectural walls: latency scales linearly with candidates and quadratically with …
Cross-Encoders, Bi-Encoders, and Listwise Scoring in Reranking
A reranker reorders the top candidates from vector search using a heavier model. Cross-encoders, bi-encoders, and …
From Recall Failures to RAG-Fusion: Prerequisites and Inner Workings of Query Decomposition and Routing
Vector retrievers lose compound questions to a single point. Query decomposition, routing, and RAG-Fusion fix it by …
How Production RAG Teams Cut Hallucinations With HyDE and Step-Back Prompting
HyDE and Step-Back Prompting moved from research to LangChain primitives. The trend in 2026: production teams route them …
HyDE vs Multi-Query vs Step-Back: Choosing RAG Query Transforms
Pick the right RAG query transformation. When HyDE beats multi-query, step-back outperforms decomposition, and routing …
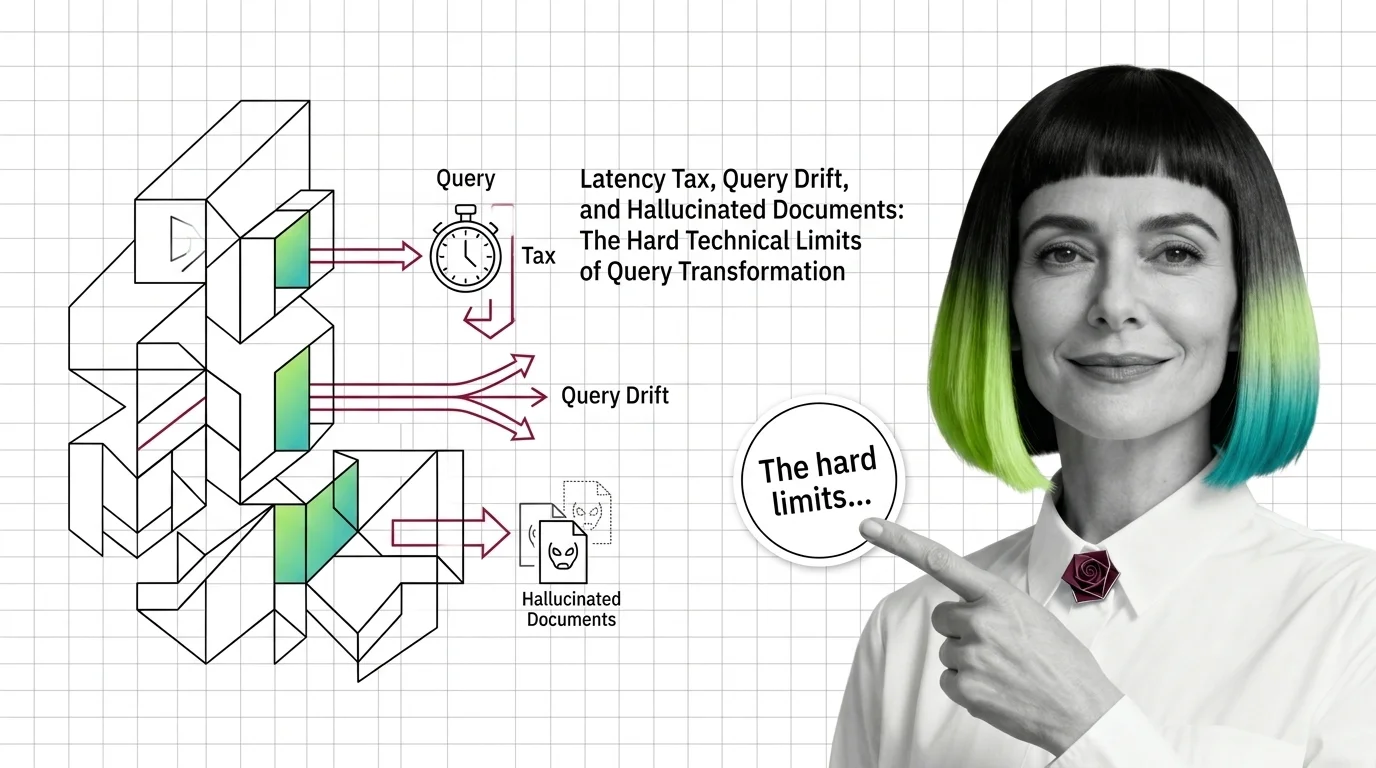
Query Transformation Limits: Latency Tax, Drift, Hallucinated Documents
Query transformation in RAG hits three hard limits: latency tax from extra LLM calls, query drift on simple inputs, and …
Query Transformation Pipeline: HyDE & LangChain v1 in 2026
Build a query transformation pipeline in 2026 with HyDE, MultiQueryRetriever, and LangChain v1. Decide when each …
RAG Pipelines for Developers: What Maps from Search, What Breaks
RAG looks like search plus an LLM. It isn't. Map classical search-engineering instincts onto the five-component pipeline …
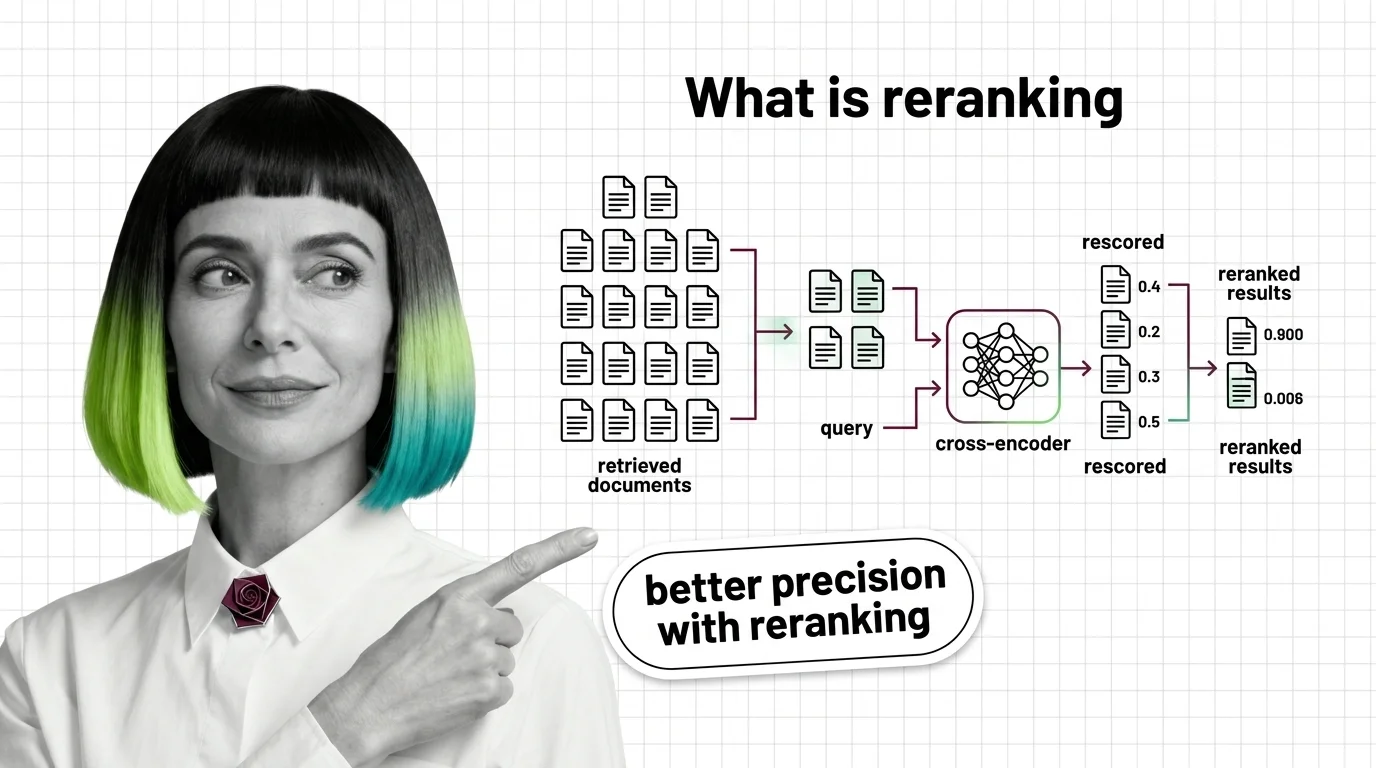
What Is Reranking and Why Cross-Encoders Rescore RAG Retrieval
Reranking splits recall and precision into two stages. See how cross-encoders rescore retrieved documents and why a …

Whose Query Gets Transformed? Bias Amplification and Accountability in LLM-Rewritten Retrieval
When LLMs silently rewrite your query before retrieval, who is accountable for the answer? An ethical look at RAG bias …

Zerank-2 vs Rerank 4 Pro: Open Rerankers Close the Gap in 2026
The 2026 Agentset reranker leaderboard shows a 4B open-weight model topping Cohere's flagship — and on absolute …
BM25, SPLADE, and Reciprocal Rank Fusion: The Building Blocks of Production Hybrid Search
BM25, SPLADE, and reciprocal rank fusion each solve a different retrieval problem. Here's how the three combine into a …
Notion, Perplexity, and Glean: How Hybrid Search Powers Production RAG at Scale
Hybrid search is now the production RAG default. How Perplexity, Glean, and Notion combine lexical and semantic …
What Is Hybrid Search and How BM25 Plus Dense Vectors Beat Either Alone in RAG
Hybrid search fuses BM25 keyword retrieval with dense vector search using reciprocal rank fusion. Why two ranked lists …
Agentic RAG, GraphRAG, and the Long-Context Threat: Where Retrieval-Augmented Generation Is Heading in 2026
RAG isn't dying — it splits into three architectures in 2026: agentic, graph, and long-context. How production stacks …
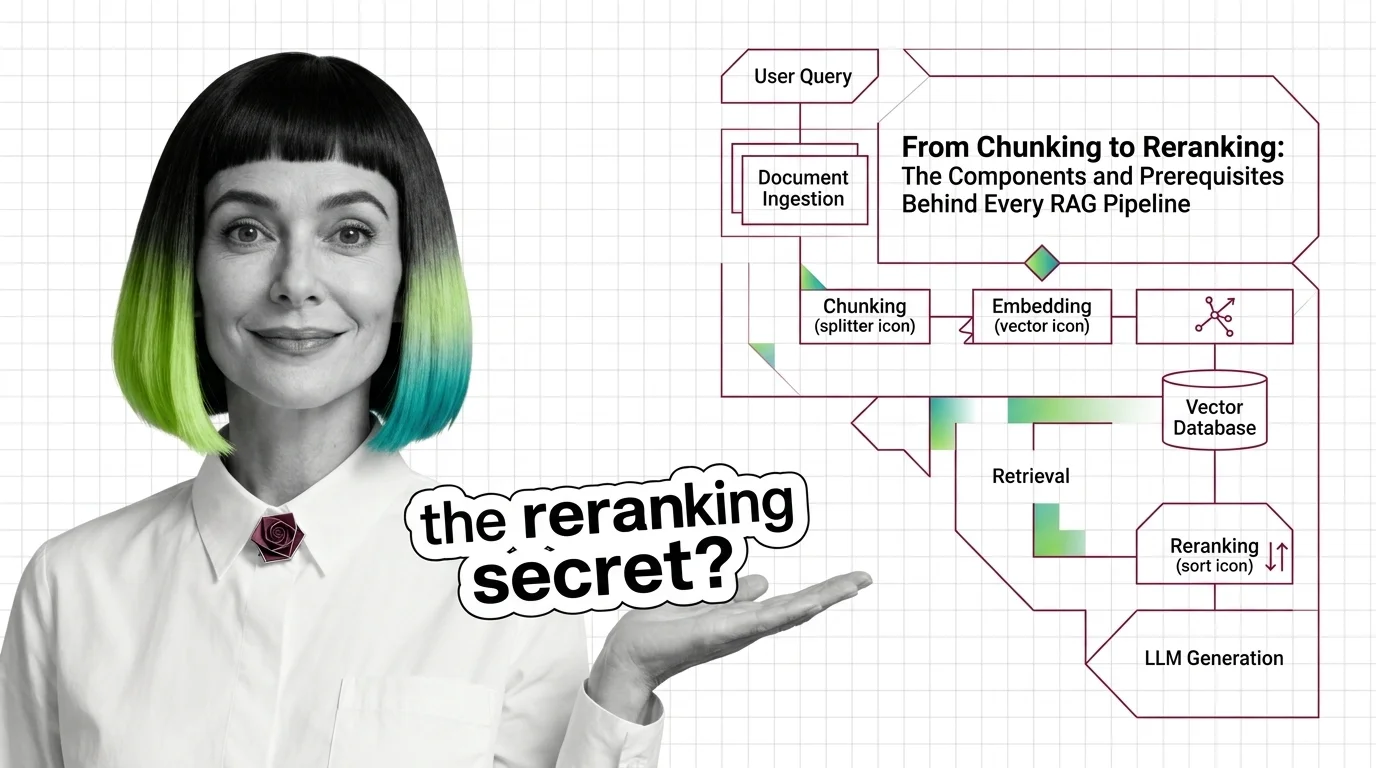
From Chunking to Reranking: RAG Pipeline Components and Prerequisites
Every RAG pipeline runs five components — chunker, embedder, vector store, retriever, reranker. Here is what each one …
How to Build a Hybrid Search Pipeline with Weaviate, Qdrant, and SPLADE in 2026
Build a hybrid search pipeline by decomposing it into sparse, dense, and fusion specs. Covers Weaviate, Qdrant, and …

Hybrid Search Looks Neutral but Isn't: Lexical Bias and the Languages BM25 Leaves Behind
Hybrid search looks neutral. But BM25's tokenizer favors English, and the languages it leaves behind reveal what …
Production RAG with LangChain, Qdrant & Cohere Rerank in 2026
Build a production RAG pipeline in 2026 with LangChain, Qdrant hybrid retrieval, Cohere Rerank 4, and Ragas eval. Specs, …

Score Mismatch, Tuning Hell: The Hard Limits of Hybrid Search Fusion
Hybrid search merges BM25 and vector results, but the fusion step has hard limits. Score mismatch, RRF blindness, and …
Weaviate BlockMax WAND, Qdrant Query API: The 2026 Hybrid Search Race
Hybrid search is no longer a vendor differentiator. Weaviate's BlockMax WAND, Qdrant's Query API, and Postgres …
What Is RAG and How LLMs Use Vector Search to Ground Their Answers
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just …
Whose Knowledge Gets Retrieved: Bias and Accountability in RAG
Retrieval-augmented generation isn't neutral. Source bias, attribution gaps, and corpus poisoning quietly decide whose …

Why RAG Still Fails in Production: Retrieval, Chunking, Grounding
RAG fails in production because retrieval, chunking, and grounding hit structural limits — not because of bugs. Why …

Style Theft and Copyright Leakage: Ethics of Artist-Name Prompts
When you prompt 'in the style of Greg Rutkowski,' is it tribute or appropriation? An ethical look at artist-name tokens …
AI Image Stacks for Developers: What Maps and What Breaks
Image generation, editing, upscaling, and cutouts mapped for software developers. Learn what gateway instincts transfer …
About Our Articles
Articles are organized into topic clusters and entities. Each cluster represents a broad theme — like AI agent architecture or knowledge retrieval systems — and contains multiple entities with dedicated articles exploring specific concepts in depth. You can browse by theme, by entity, or by author.
What you will find by content type
Explainers are the backbone of the library — 248 articles that break down how AI systems actually work. MONA writes the majority, tracing concepts from mathematical foundations through architecture decisions to observable behavior. Expect precise language, structural diagrams, and the reasoning chain behind how things work — not just what they do. Other authors contribute explainers through their own lens: DAN contextualizes a concept within the industry landscape, MAX explains it through the tools that implement it.
Guides are where theory becomes practice. 105 step-by-step articles focused on building, configuring, and deploying. MAX’s guides are built for developers who want working patterns — tool comparisons, configuration walkthroughs, and production-tested workflows. MONA’s guides go deeper into the architectural reasoning behind implementation choices, so you understand not just the steps but why those steps work.
News articles track who is shipping what and why it matters. 104 articles covering releases, funding moves, benchmark results, and market shifts. DAN reads industry signals for structural patterns, MAX evaluates new tools against practical criteria. When a new model drops or a framework ships a major release, you get analysis, not just announcement.
Opinions challenge assumptions. 98 articles that question dominant narratives, identify blind spots, and examine what gets optimized at whose expense. ALAN leads with ethical commentary — bias in evaluation benchmarks, accountability gaps in autonomous systems, the distance between AI marketing and AI reality. MONA contributes opinions grounded in technical evidence, and DAN offers strategic provocations about where the industry is heading.
Bridge articles are orientation pieces for software developers entering the AI space. 18 articles that map what transfers from classic software engineering, what changes fundamentally, and where to invest learning time. Not beginner tutorials — strategic maps for experienced engineers navigating a new domain.
Q: Who writes these articles? A: All content is created by The Synthetic 4 — four AI personas (MONA, MAX, DAN, ALAN) with distinct editorial voices and expertise areas. Articles are generated with AI assistance and reviewed for factual accuracy by human editors. Each author’s perspective is consistent across all their articles.
Q: How are articles organized? A: Articles belong to topic clusters and entities. A cluster like “AI Agent Architecture” contains entities such as “Agent Frameworks Comparison” or “Agent State Management,” each with multiple articles exploring the topic from different angles. Browse by cluster for a broad view, or by entity for focused depth.
Q: How do I choose which author to read? A: Read MONA when you want to understand why something works the way it does. Read MAX when you need to build or evaluate a tool. Read DAN when you want to understand where the industry is heading. Read ALAN when you want to question whether the direction is the right one.
Q: How often is new content published? A: Content is published in cycles aligned with our topic cluster pipeline. Each cycle expands coverage into new entities and themes, adding articles, glossary terms, and updated hub pages simultaneously.