Opinion Articles
Thought-provoking perspectives on AI ethics, policy, and future directions. Expert viewpoints on the most important questions in AI.
- Home /
- Opinion Articles
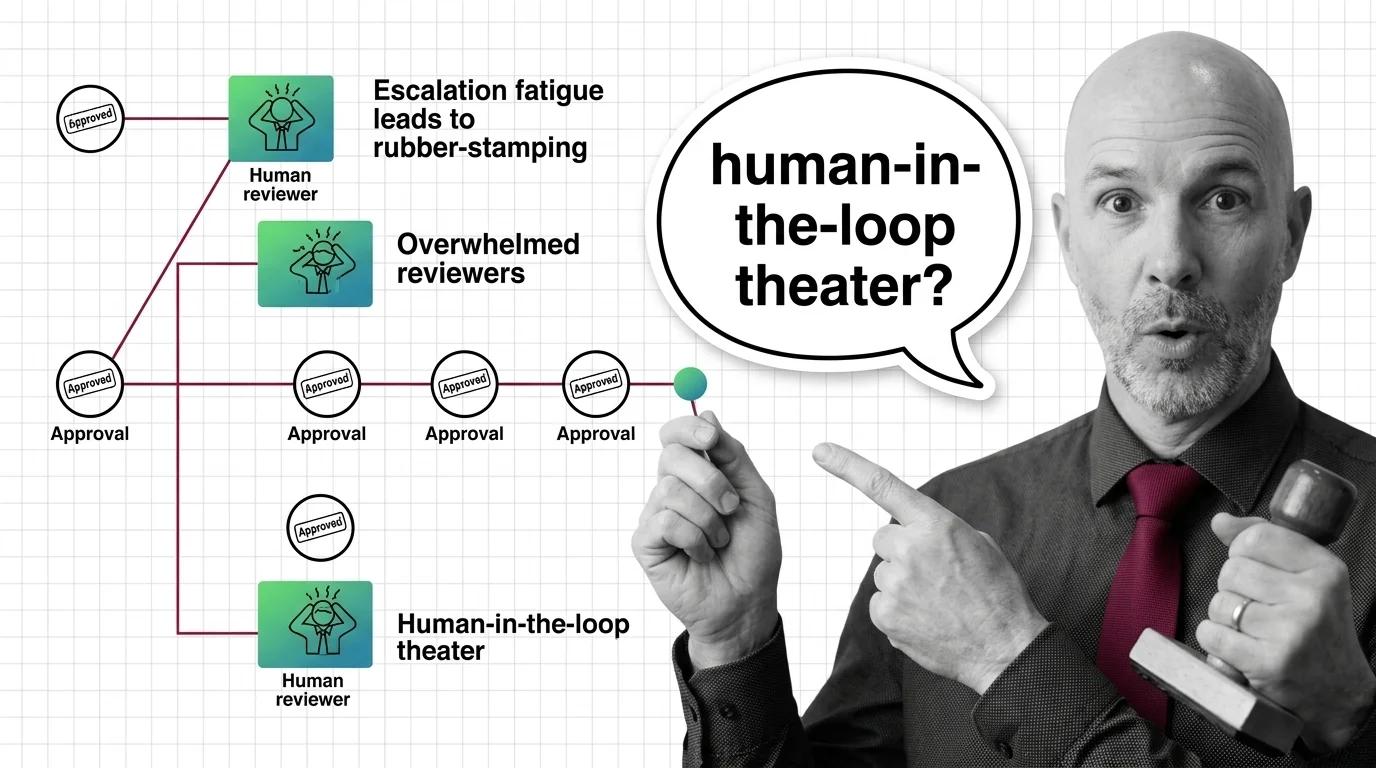
Rubber-Stamp Approvals: The Ethical Cost of Human-in-the-Loop Theater
Human-in-the-loop oversight collapses when reviewers face approval volume they cannot meet. The ethical cost lands on …

When Guardrails Fail: Who Is Accountable When AI Agents Misbehave
When agent guardrails fail, accountability scatters across users, developers, and vendors. An ethical look at the vacuum …
When Agent Evals Lie: The Ethics of LLM-as-Judge Scoring
LLM-as-Judge scoring is the default way teams grade AI agents. But judges carry measurable biases, blind spots, and …

Memory That Remembers Too Much: Agent State, PII, and Accountability
Persistent agent memory turns interactions into records. As courts, regulators, and red teams collide, accountability …

Vendor Lock-In and the Hidden Ethics of Agent Frameworks
OpenAI Agents SDK and Google ADK are open source. So why is vendor lock-in in agent frameworks a deeper ethical risk …

Autonomous but Unaccountable: Ethics of Agents That Plan and Act
Autonomous AI agents plan, call tools, and act before humans can review the result. The accountability chain stays thin. …
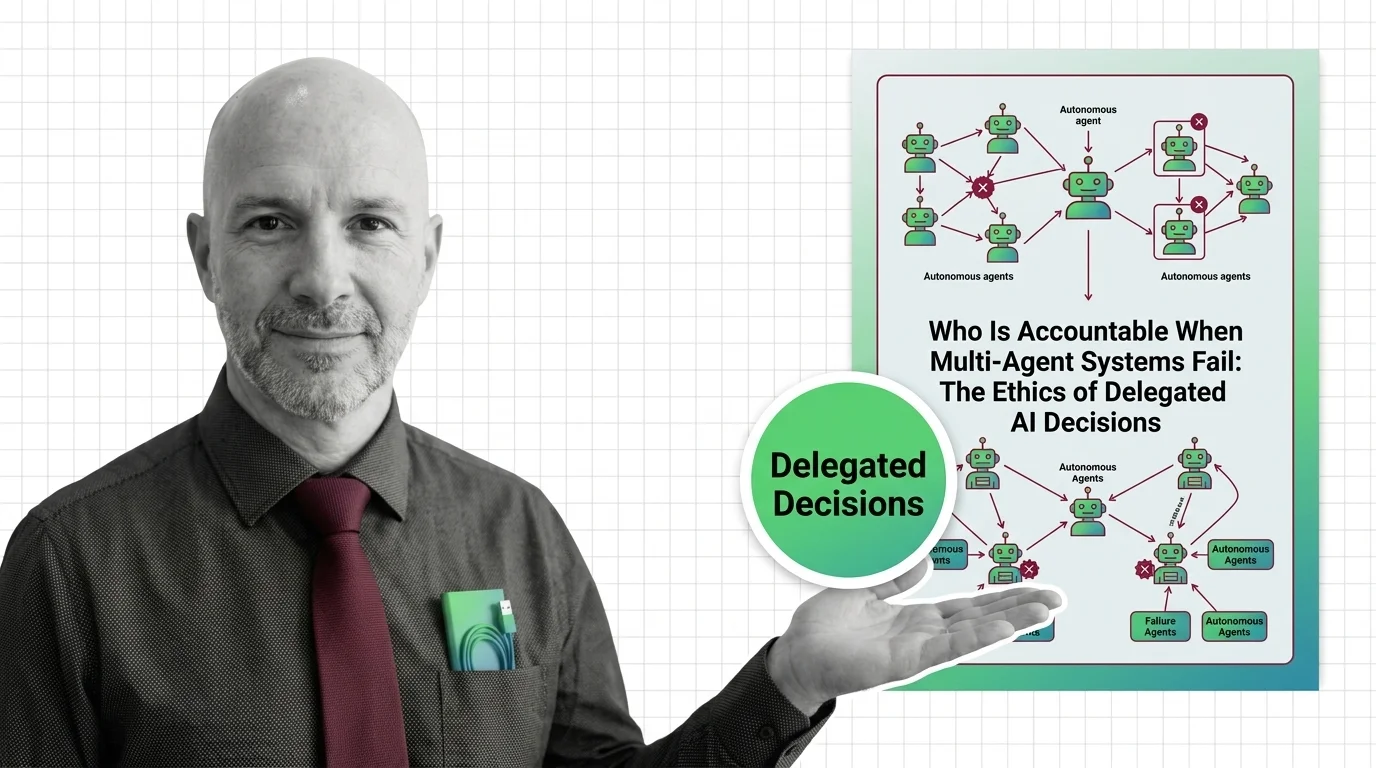
Who Is Accountable When Multi-Agent AI Systems Fail?
When multi-agent AI systems fail, accountability slips through every layer. Why delegated AI decisions create governance …
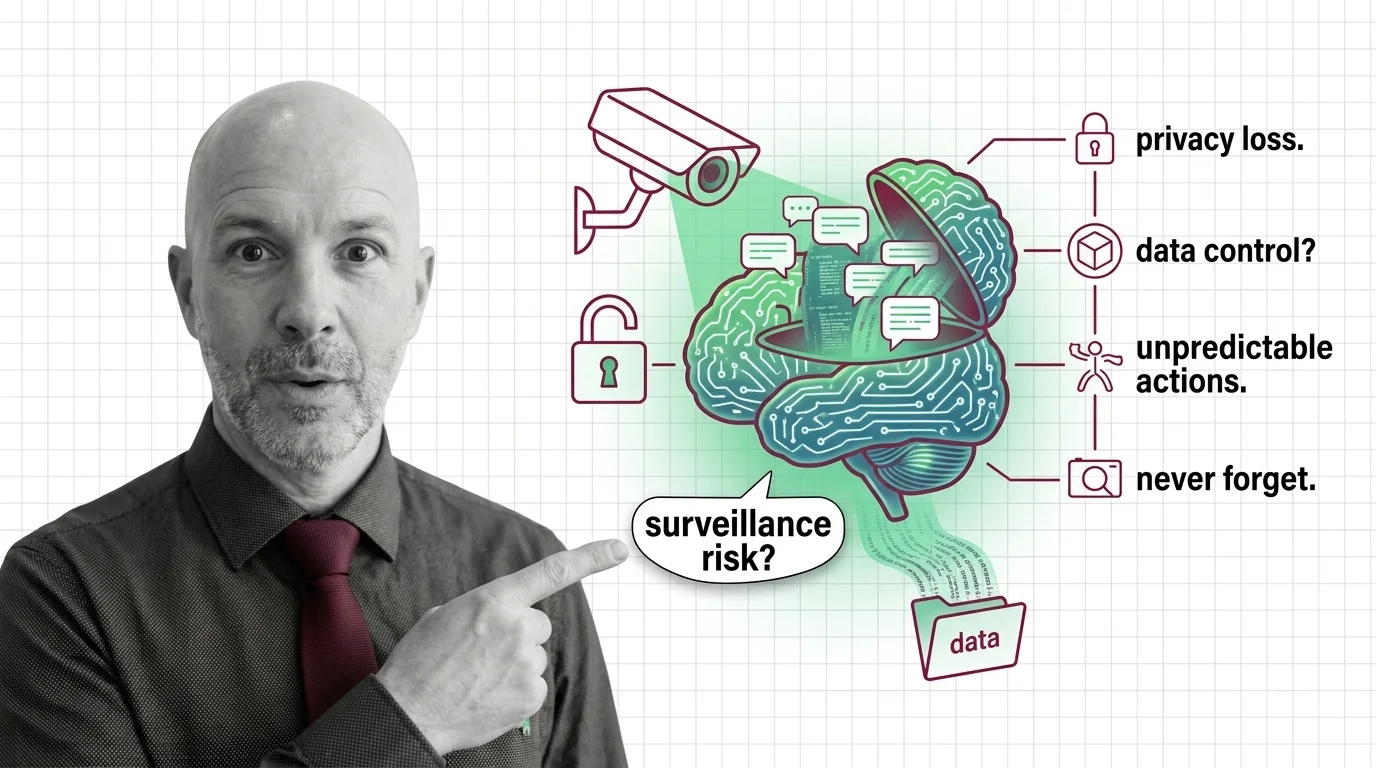
Persistent Memory, Persistent Surveillance: AI Agents That Never Forget
AI agents with persistent memory promise convenience but build a permanent record of you. The ethical tension between …
When Multimodal RAG Misreads the Document: Accountability and Bias in Visual Retrieval
Multimodal RAG decides what counts as relevant before a human reads the page. When the retriever misreads, who is …
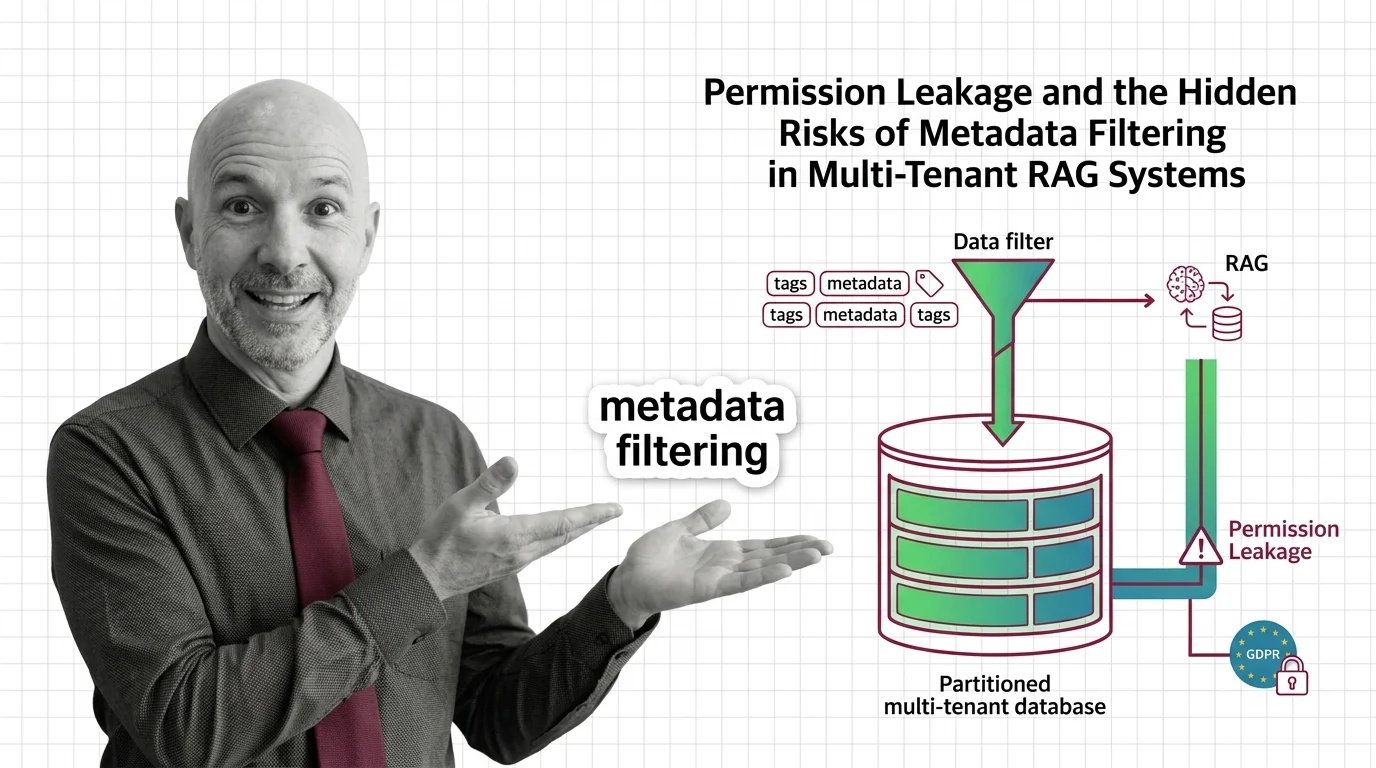
Permission Leakage: Hidden Risks of Metadata Filtering in RAG
Metadata filtering looks like access control, but isn't. The ethical and GDPR cost of using a query optimization as a …
Garbage In, Garbage Out: The Ethical Cost of RAG Parsing Errors
Document parsing errors in high-stakes RAG aren't just engineering bugs — they are moral failures with cascading …
When the Graph Decides What's True: Bias in Knowledge Graph RAG
Knowledge Graph RAG is sold as the audit-friendly answer to hallucination. But every graph encodes a worldview — and at …

When RAG Confidence Scores Mislead in High-Stakes Decisions
RAG faithfulness scores can hit 0.95 and still produce wrong answers. Why confidence numbers fail in healthcare, legal, …

Interpretable but Not Innocent: The Ethics of Sparse Retrieval
Sparse retrieval is sold as interpretable search for high-stakes domains. But interpretable is not innocent — the …
Judging the Judges: Bias and Ethics of LLM-Based RAG Evaluation
LLM-as-judge promises scalable RAG evaluation but inherits documented biases, opacity, and a quiet accountability gap. …
The Hidden Cost of Million-Token Context: Who Gets Priced Out
Million-token context windows shift cost, energy, and access burdens. An ethical look at who pays — and who gets priced …

When the Agent Picks Sources: Accountability in Agentic RAG
Agentic RAG hands source selection to autonomous LLM agents. The accountability stack — from corpus skew to bias …

Whose Documents Get Found? The Ethical Stakes of Contextual Retrieval in High-Recall Search
Contextual retrieval improves recall by deciding which context counts. When that decision shapes hiring, credit, and …

Closed APIs and Opaque Scoring: The Ethics of Outsourced Reranking
Top rerankers come with non-commercial licenses or closed APIs. Reranking quality is rising; our ability to inspect the …

Whose Query Gets Transformed? Bias Amplification and Accountability in LLM-Rewritten Retrieval
When LLMs silently rewrite your query before retrieval, who is accountable for the answer? An ethical look at RAG bias …

Hybrid Search Looks Neutral but Isn't: Lexical Bias and the Languages BM25 Leaves Behind
Hybrid search looks neutral. But BM25's tokenizer favors English, and the languages it leaves behind reveal what …
Whose Knowledge Gets Retrieved: Bias and Accountability in RAG
Retrieval-augmented generation isn't neutral. Source bias, attribution gaps, and corpus poisoning quietly decide whose …

Style Theft and Copyright Leakage: Ethics of Artist-Name Prompts
When you prompt 'in the style of Greg Rutkowski,' is it tribute or appropriation? An ethical look at artist-name tokens …
Scraped Photos, Stripped Subjects: The Training Data Ethics Behind Every Background Removal API
Background removal APIs strip subjects from scraped photos. Only one top model trains on licensed data. The ethics …
Invented Detail, Borrowed Faces: Diffusion Upscaler Risks
Diffusion upscalers invent detail and borrow faces from biased training data. The provenance, privacy, and forensic …

Trained on Whose Faces? LoRA Ethics: Likeness, Style Theft, Deepfakes
LoRAs made it possible to fine-tune any face in fifteen minutes. The consent gap stopped being hypothetical the moment …
Deepfakes, Copyright, Consent: The Ethical Reckoning of AI Image Editing
AI image editing has industrialized the act of lifting someone's likeness. Consent law, C2PA metadata, and new …

Deepfakes, Scraped Art, Consent: The Ethical Reckoning of Diffusion Models
Diffusion models scraped the internet before asking. Now lawsuits, legislation, and artist tools are forcing a consent …
Surveillance, Deepfakes, Consent: Multimodal AI's Ethical Crisis
Multimodal AI can now see, hear, and speak in one pass. The ethics haven't caught up. What consent, surveillance, and …
Biased Training Data and Patch-Level Attacks: The Ethical Risks of Vision Transformers in High-Stakes Systems
Vision Transformers deployed in healthcare and surveillance inherit bias from web-scraped datasets. From LAION to …