Explainer Articles
In-depth explanations of AI concepts, architectures, and principles. Educational content that breaks down complex topics into understandable insights.
- Home /
- Explainer Articles
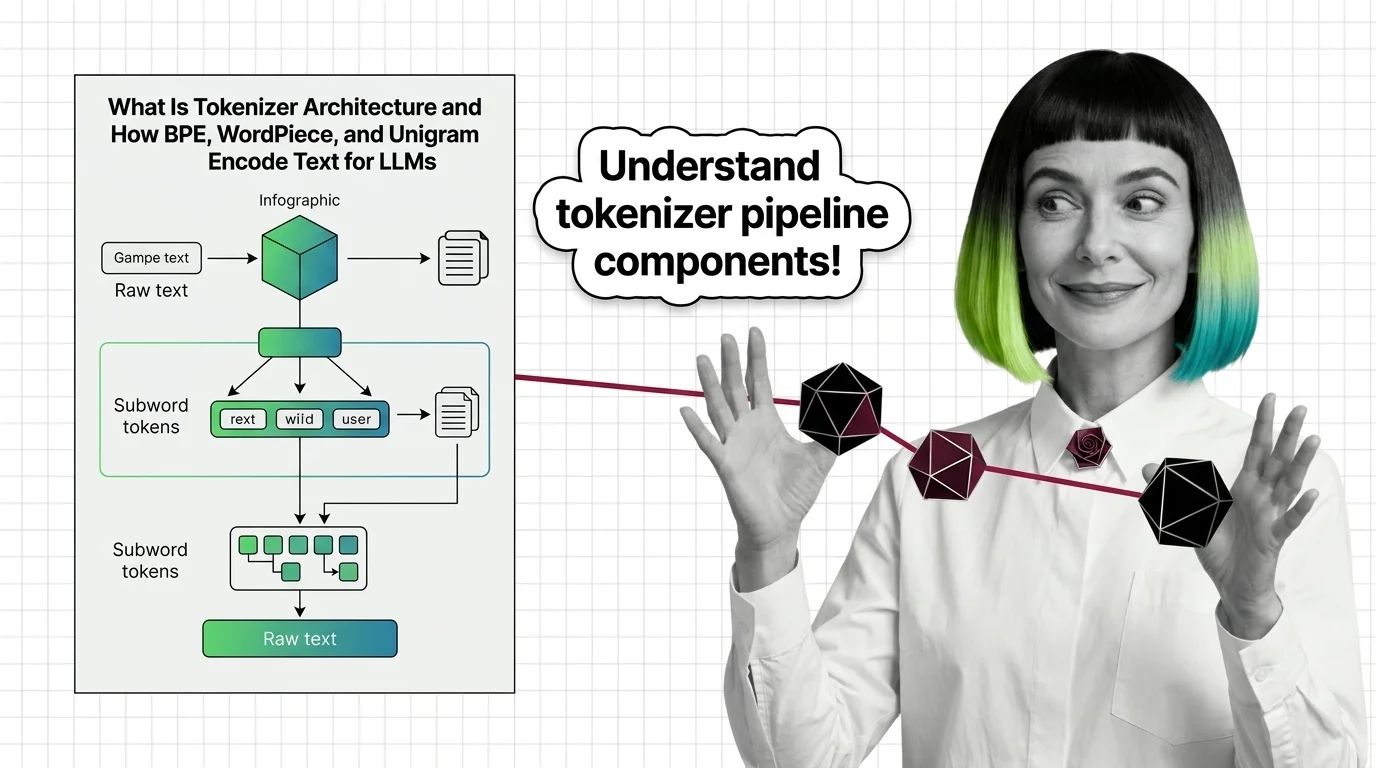
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …
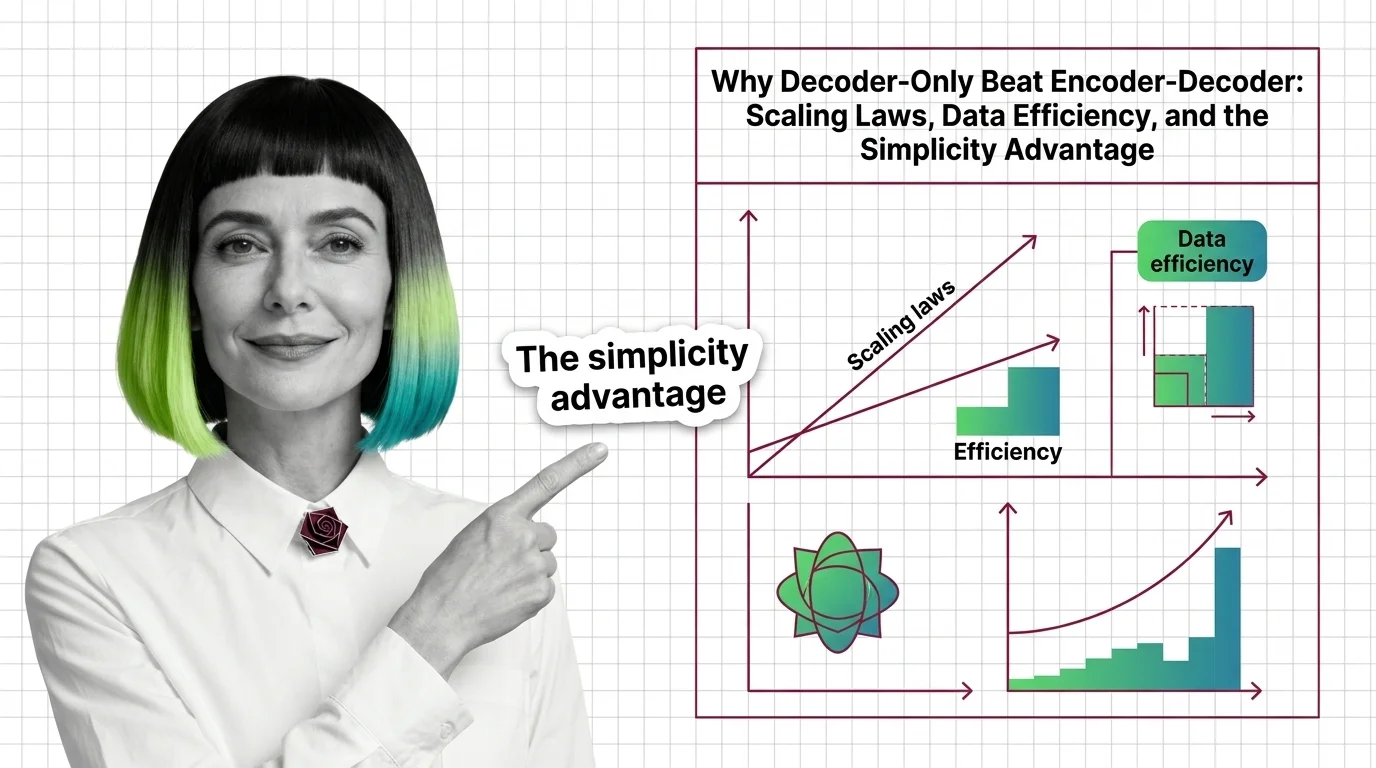
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
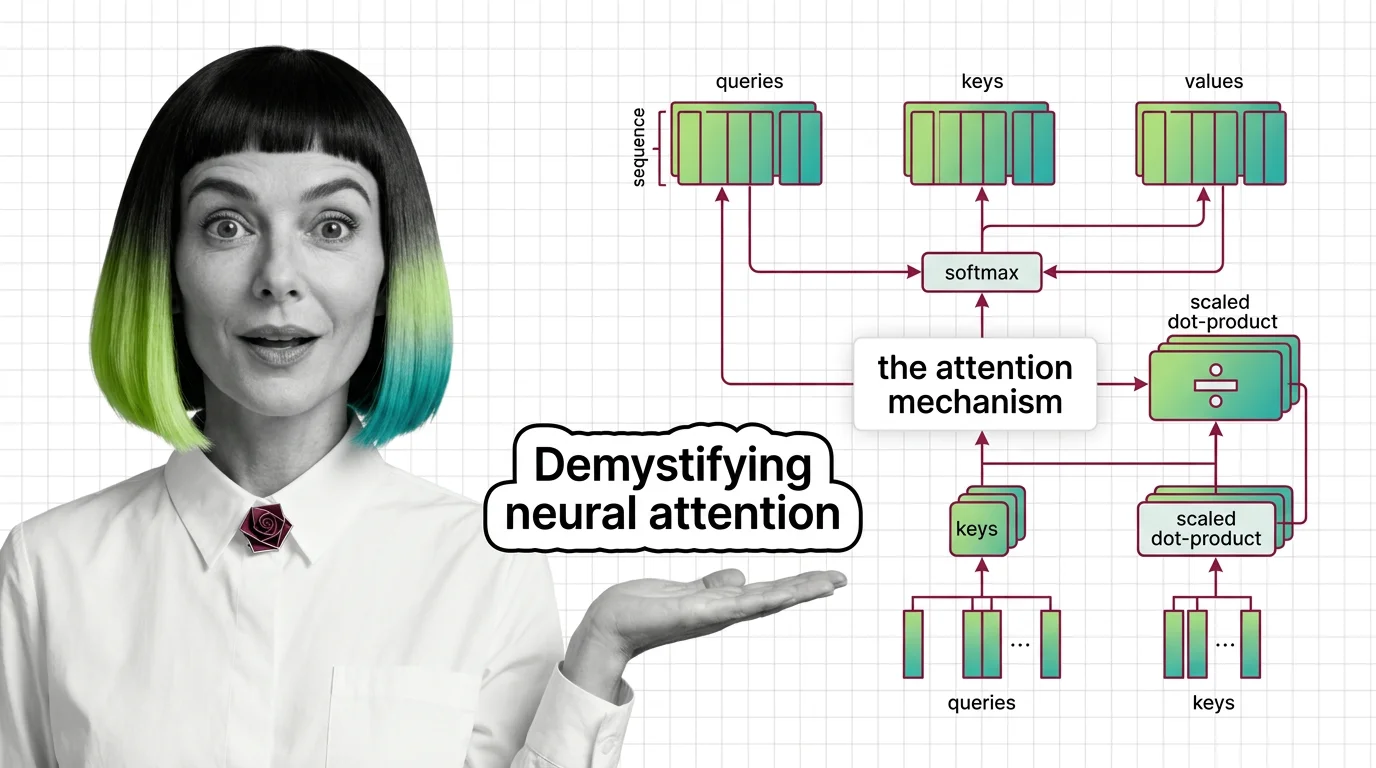
Attention Mechanism: Scaled Dot-Product, Self vs Cross
Transformers use weighted averaging, not human-like focus: scaled dot-product, self-attention vs cross-attention, and …
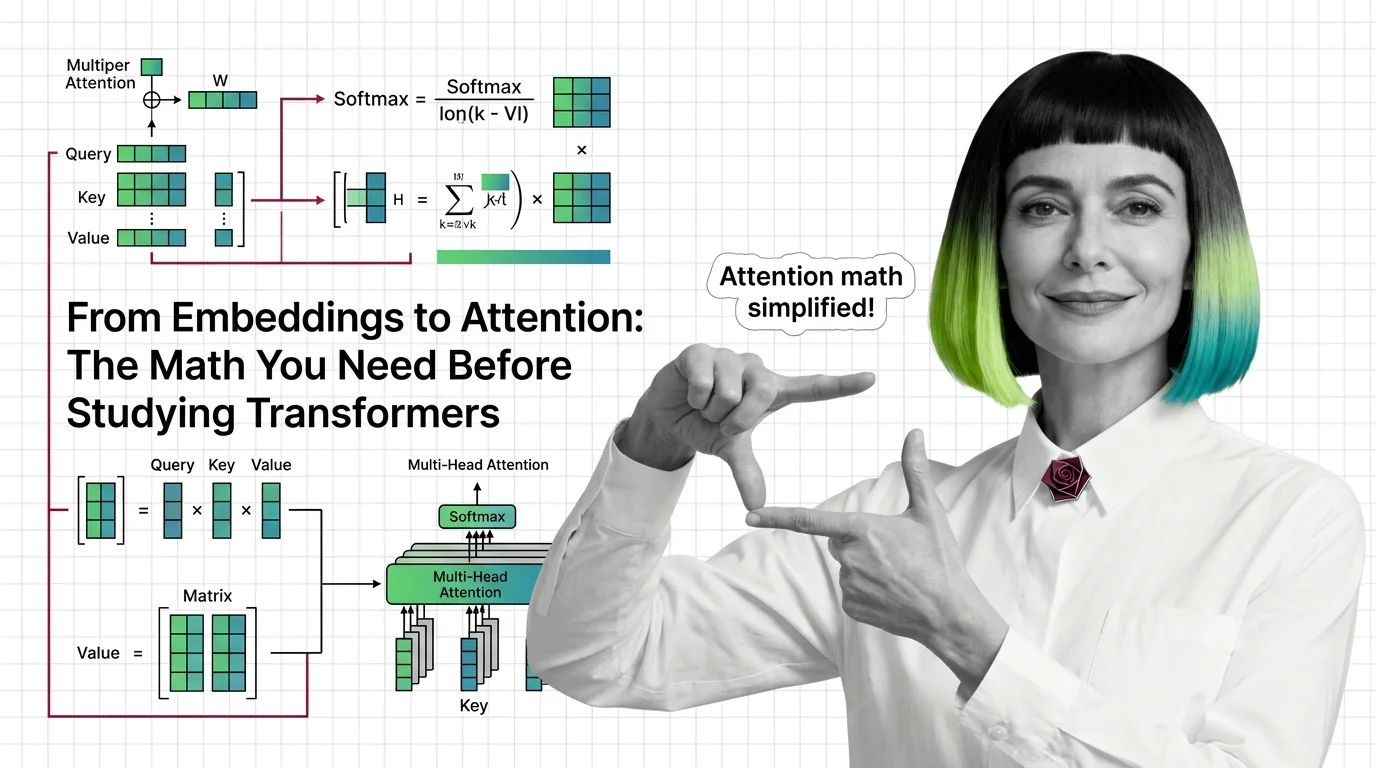
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
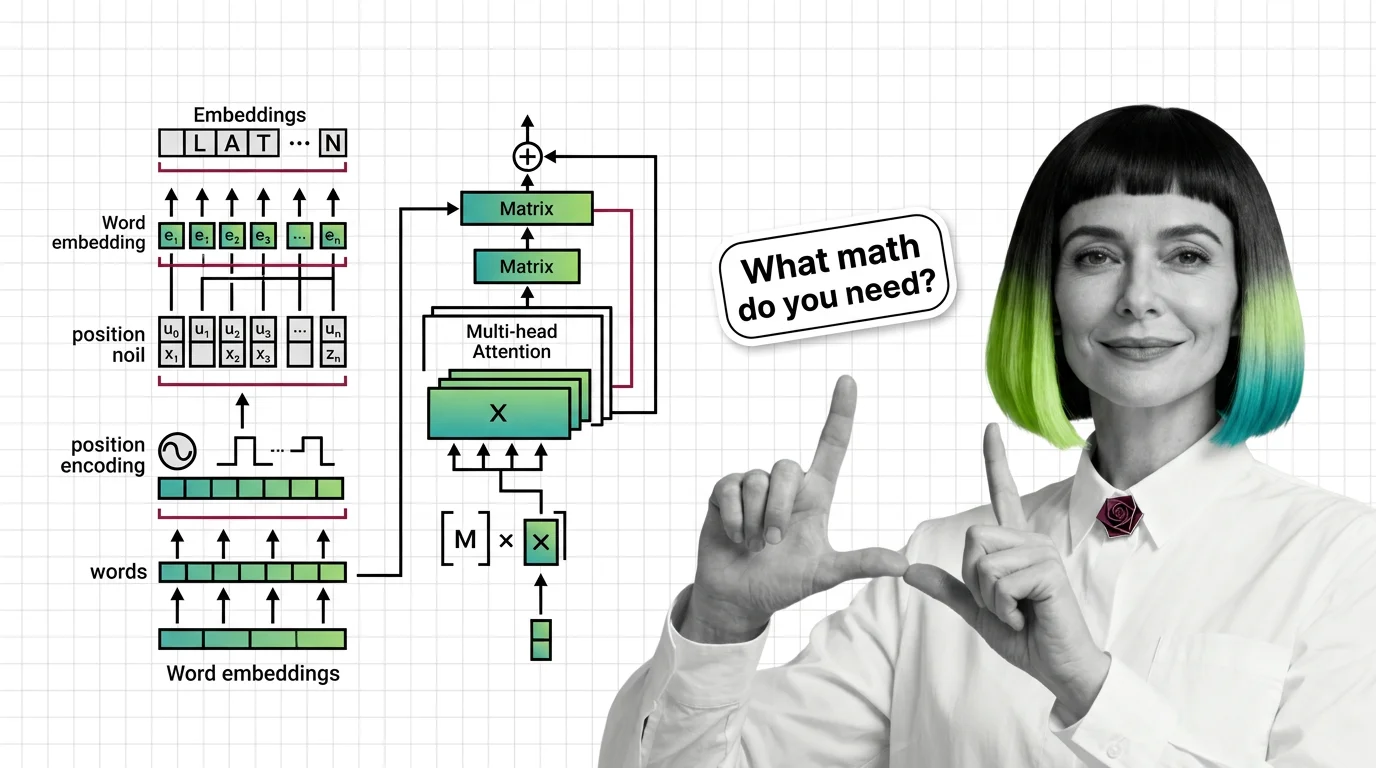
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
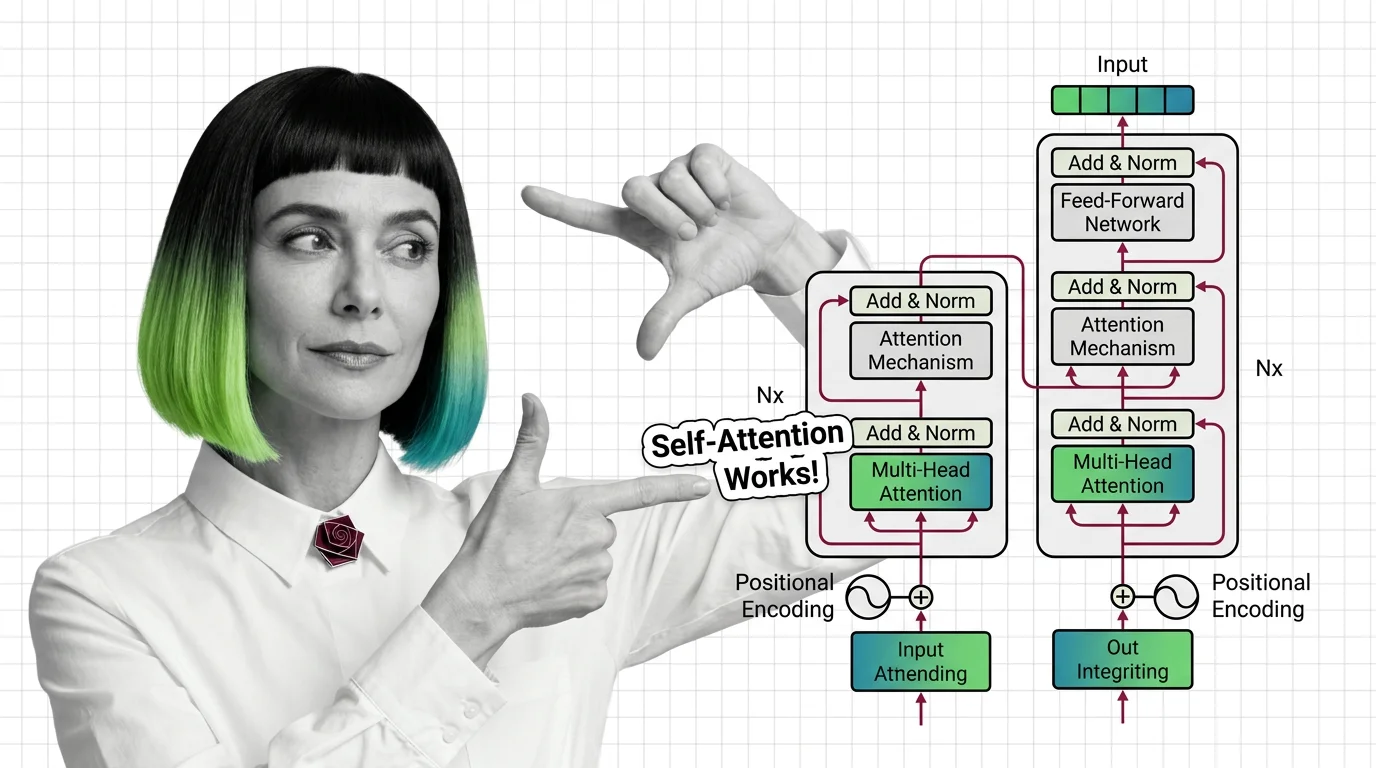
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
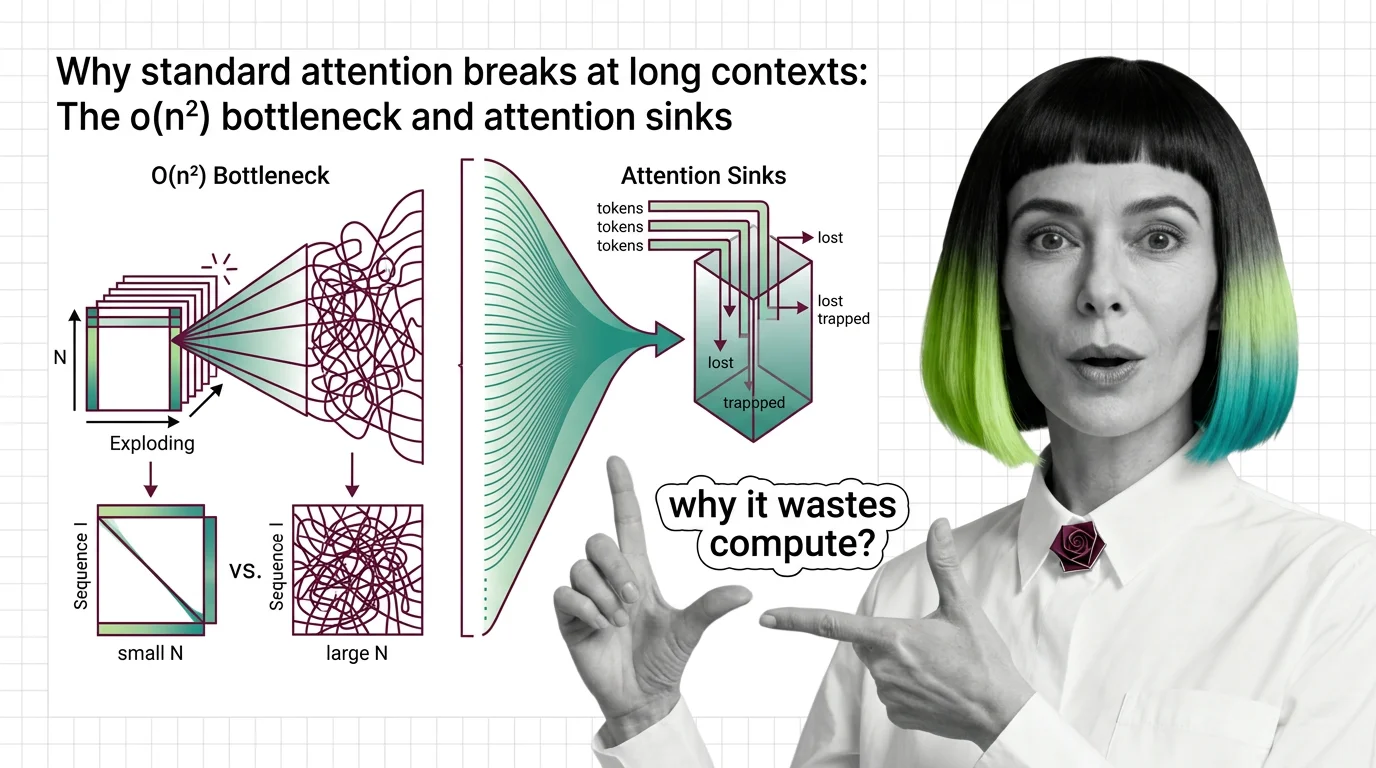
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
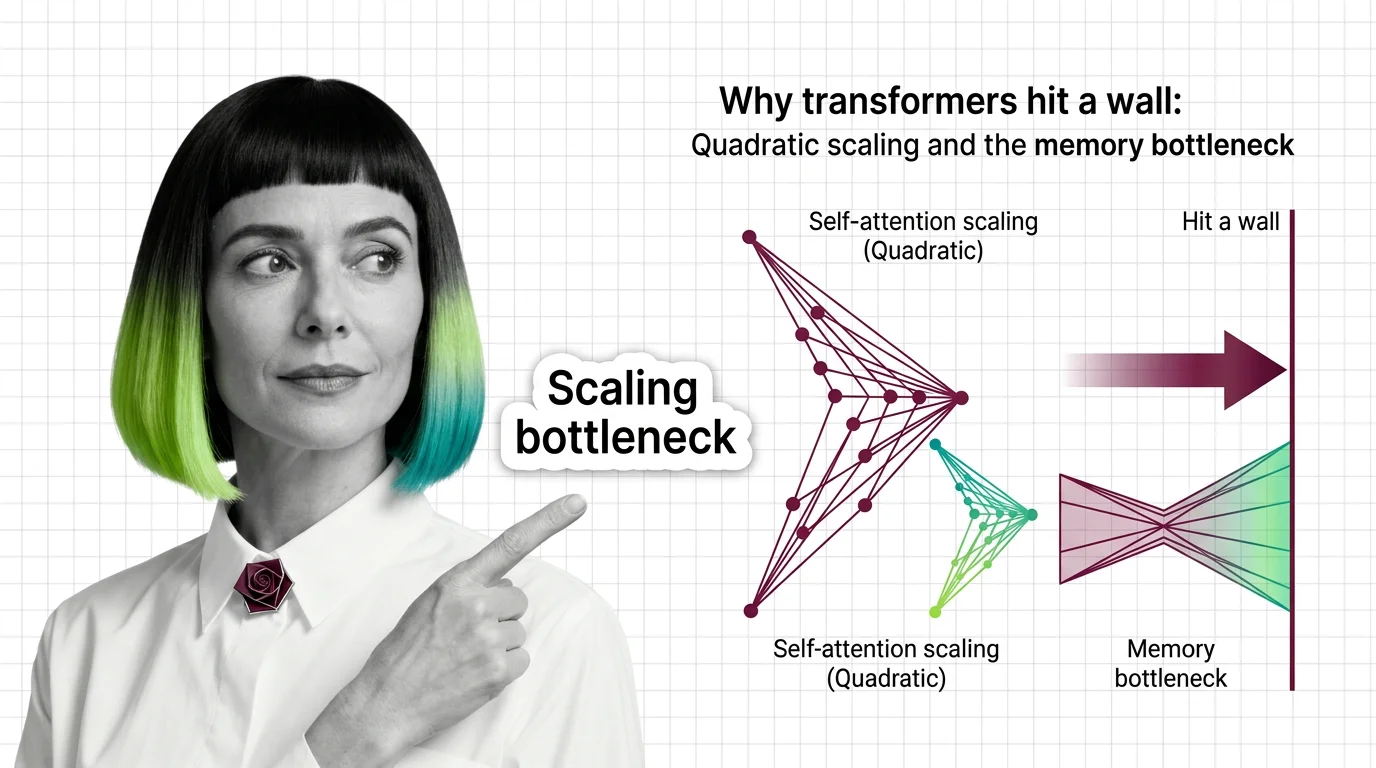
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …