Explainer Articles
In-depth explanations of AI concepts, architectures, and principles. Educational content that breaks down complex topics into understandable insights.
- Home /
- Explainer Articles
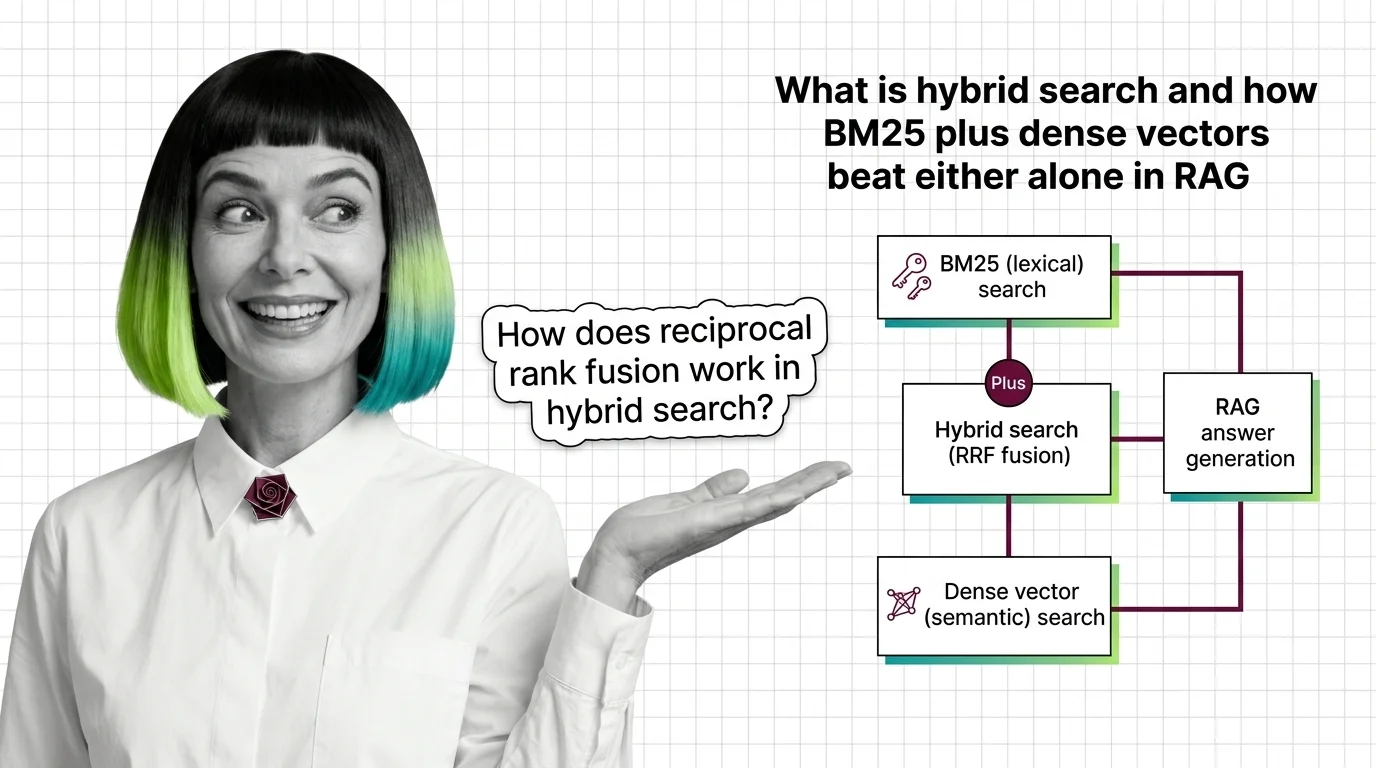
What Is Hybrid Search and How BM25 Plus Dense Vectors Beat Either Alone in RAG
Hybrid search fuses BM25 keyword retrieval with dense vector search using reciprocal rank fusion. Why two ranked lists …
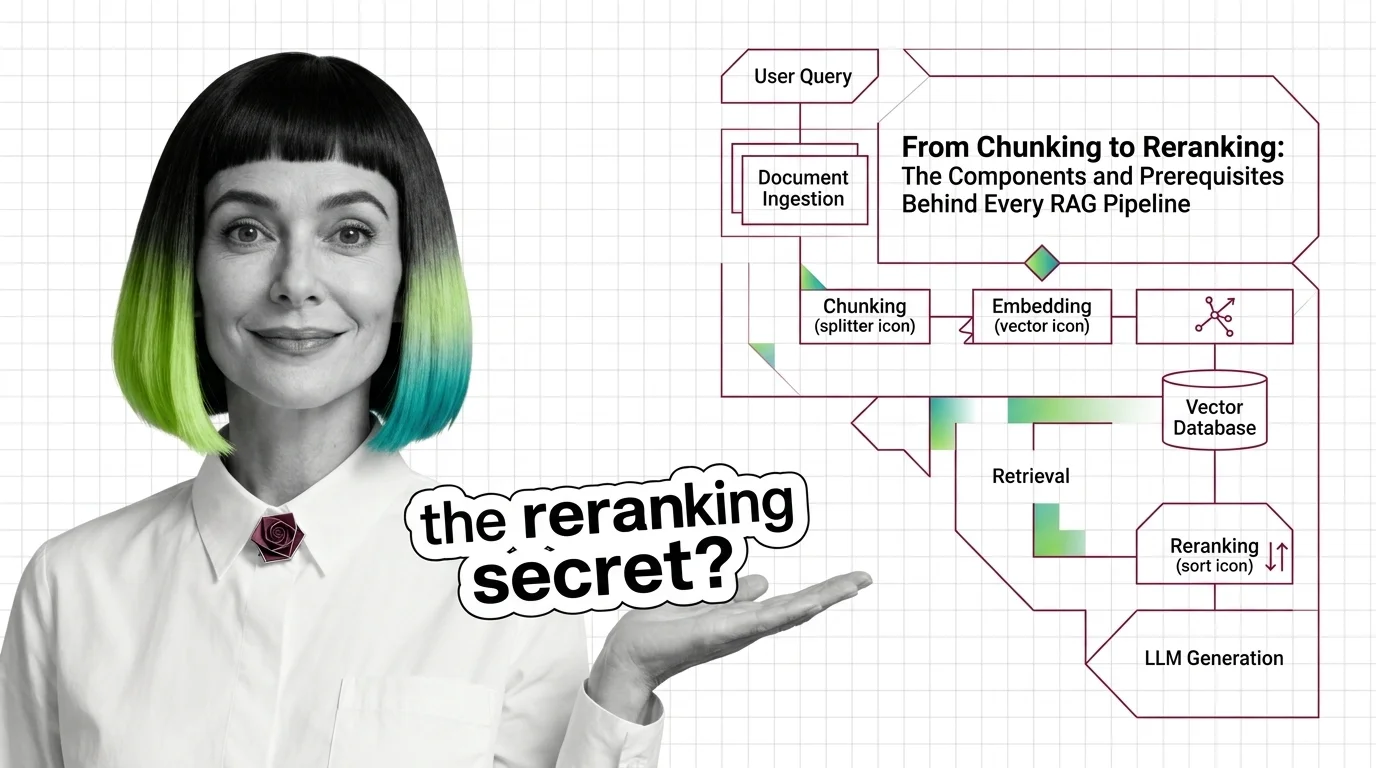
From Chunking to Reranking: RAG Pipeline Components and Prerequisites
Every RAG pipeline runs five components — chunker, embedder, vector store, retriever, reranker. Here is what each one …

Score Mismatch, Tuning Hell: The Hard Limits of Hybrid Search Fusion
Hybrid search merges BM25 and vector results, but the fusion step has hard limits. Score mismatch, RRF blindness, and …
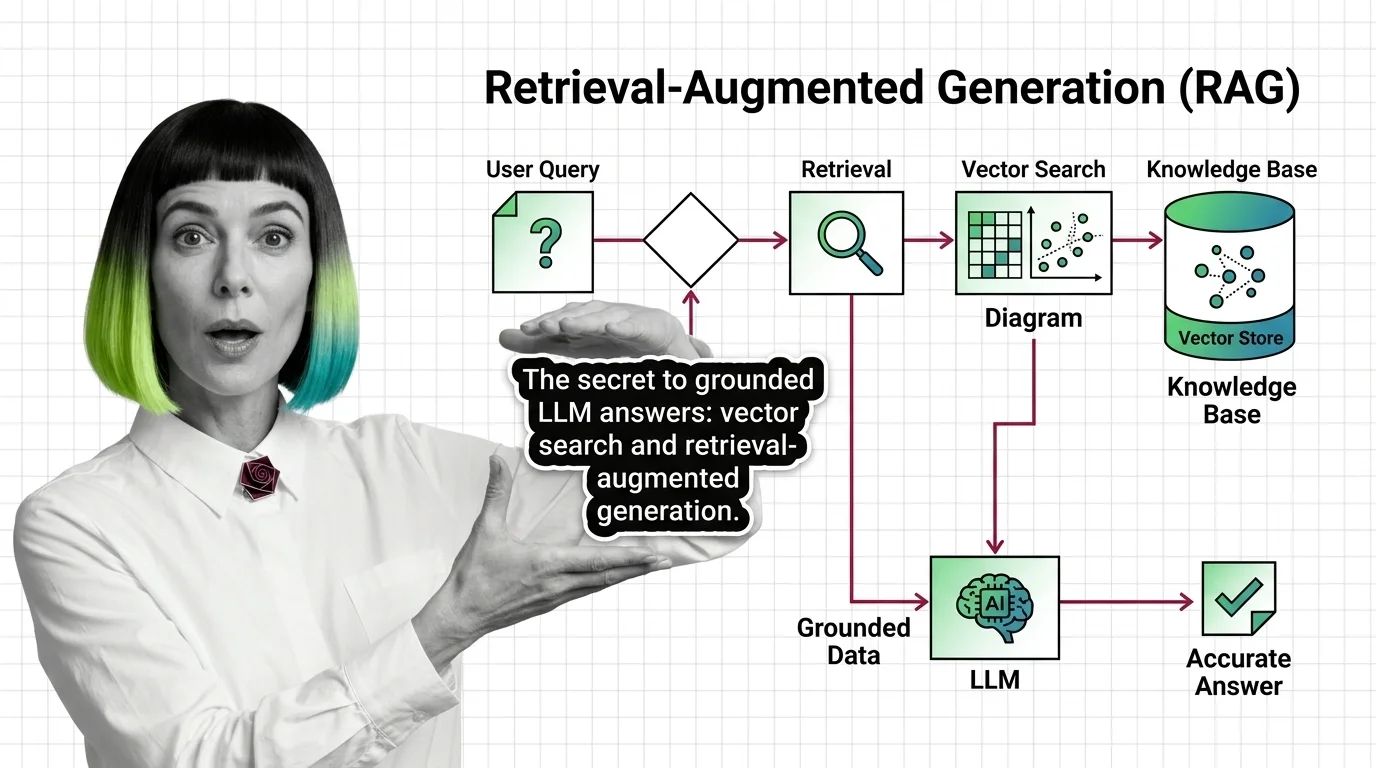
What Is RAG and How LLMs Use Vector Search to Ground Their Answers
Retrieval-augmented generation pairs an LLM with a vector index so answers are grounded in real documents — not just …

Why RAG Still Fails in Production: Retrieval, Chunking, Grounding
RAG fails in production because retrieval, chunking, and grounding hit structural limits — not because of bugs. Why …
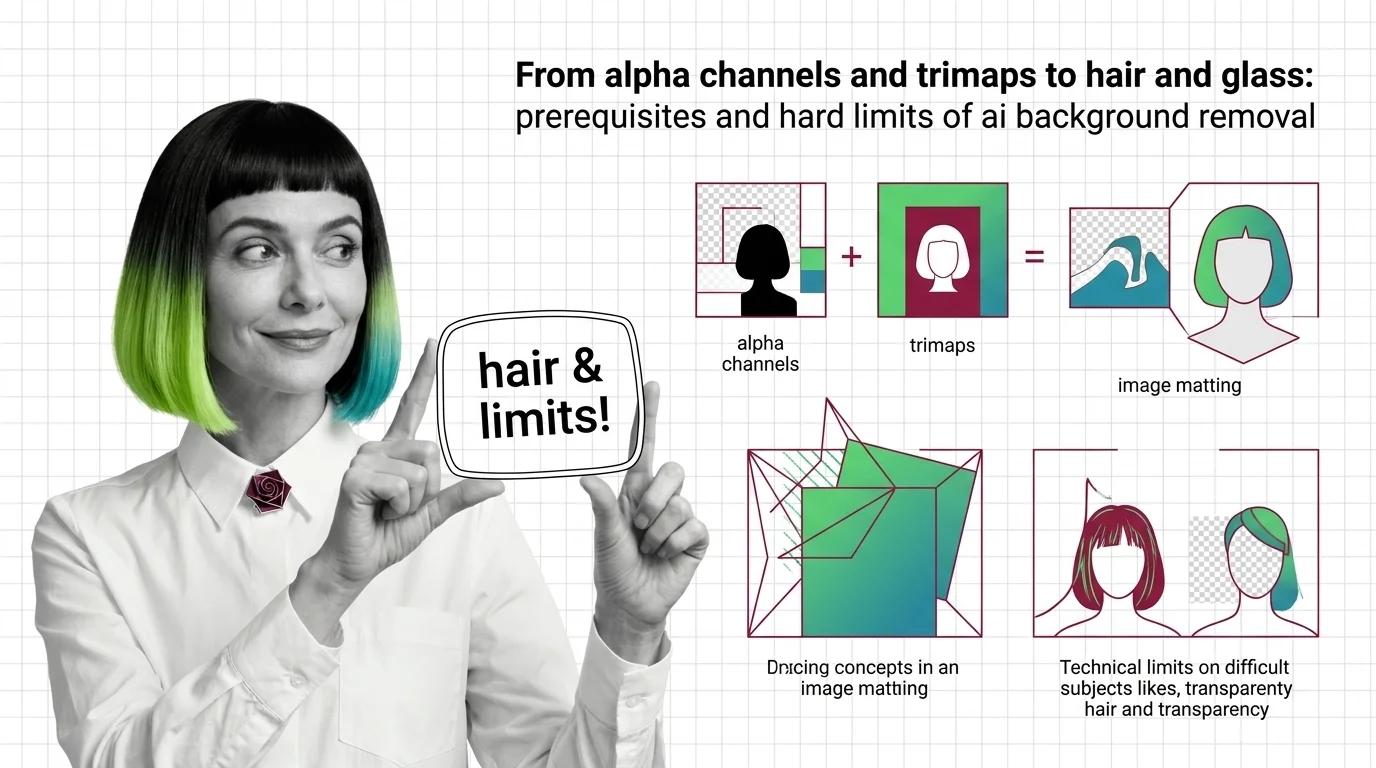
Alpha Channels, Trimaps, and the Hard Limits of AI Background Removal
Background removal is alpha estimation, not subject detection. Learn how trimaps and matting work, and why hair, glass, …
Negative Prompts, Weights, Seeds: Image Prompting Limits 2026
Negative prompts and weight syntax aren't universal — and seed reproducibility breaks across model versions. Inside the …
Prompt Engineering for Image Generation: How Diffusion Models Read Text
Image prompts steer probability, not pixels. Learn how diffusion models, cross-attention, and CFG turn text into images …
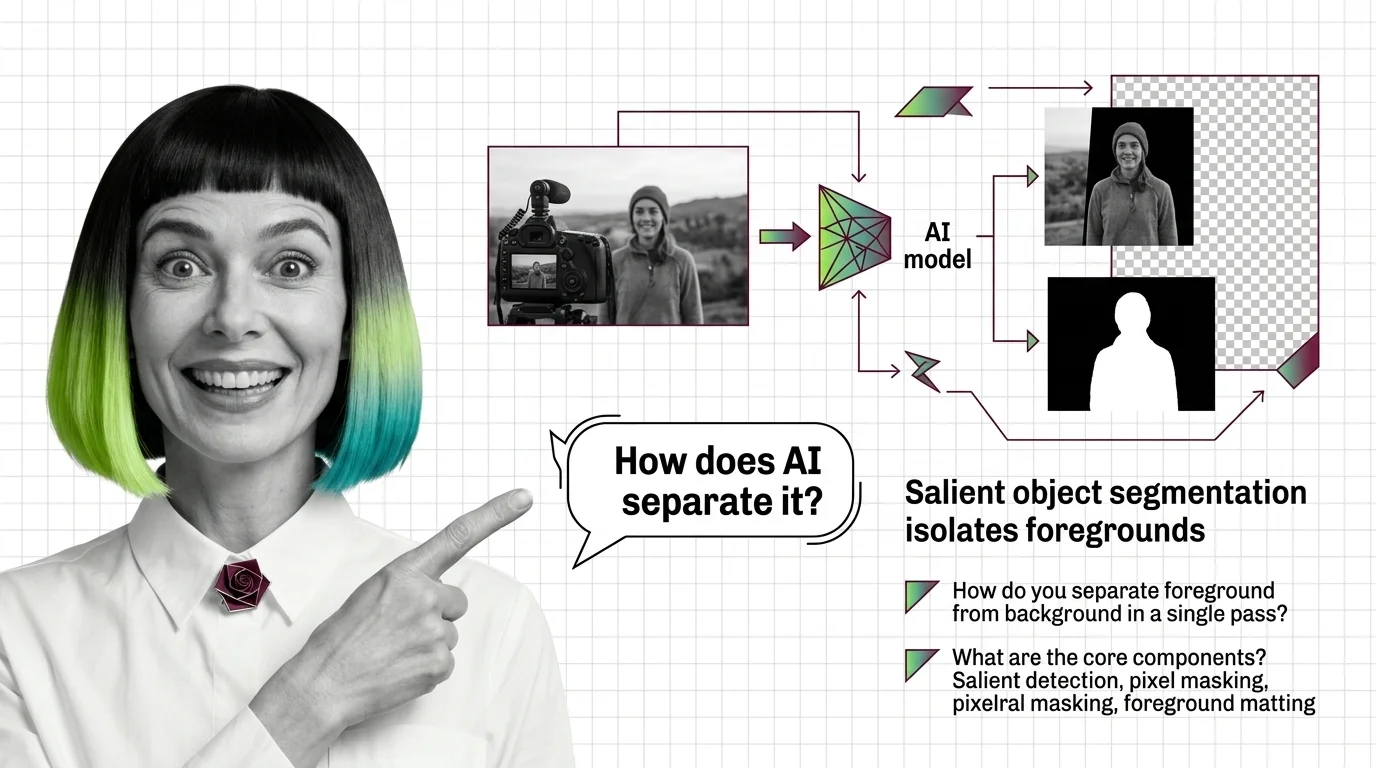
What Is AI Background Removal? How Salient Object Segmentation Works
AI background removal is not one model — it's salient object detection plus alpha matting. See how U2-Net, BiRefNet, and …
How LoRA Fine-Tunes Diffusion Models for Image Generation
LoRA fine-tunes Stable Diffusion and FLUX without retraining. Learn how rank, alpha, and the BA decomposition turn a …
From RRDB Blocks to Diffusion Priors: Inside Modern AI Upscalers
How modern AI upscalers are built — from ESRGAN's RRDB blocks and Real-ESRGAN to SUPIR's diffusion prior, plus the …
Training Image LoRAs: Diffusion Math, Rank-Alpha, and VRAM Limits
Image LoRAs retarget diffusion models with small adapter files. Learn the rank-alpha math, VRAM ranges from SD 1.5 to …
What Is Image Upscaling and How AI Super-Resolution Reconstructs Detail Beyond the Original Pixels
AI image upscaling doesn't enlarge what was captured — it generates plausible pixels from a learned prior. Learn how GAN …

Why AI Upscalers Hallucinate Faces and Tile Seams at 4K and 8K
AI upscalers don't break at 4K and 8K because of weak hardware. The failures are structural — rooted in diffusion priors …

From Diffusion to InstructPix2Pix: AI Image Editing Prerequisites
Before using GPT Image or FLUX, understand diffusion, classifier-free guidance, and why InstructPix2Pix made …
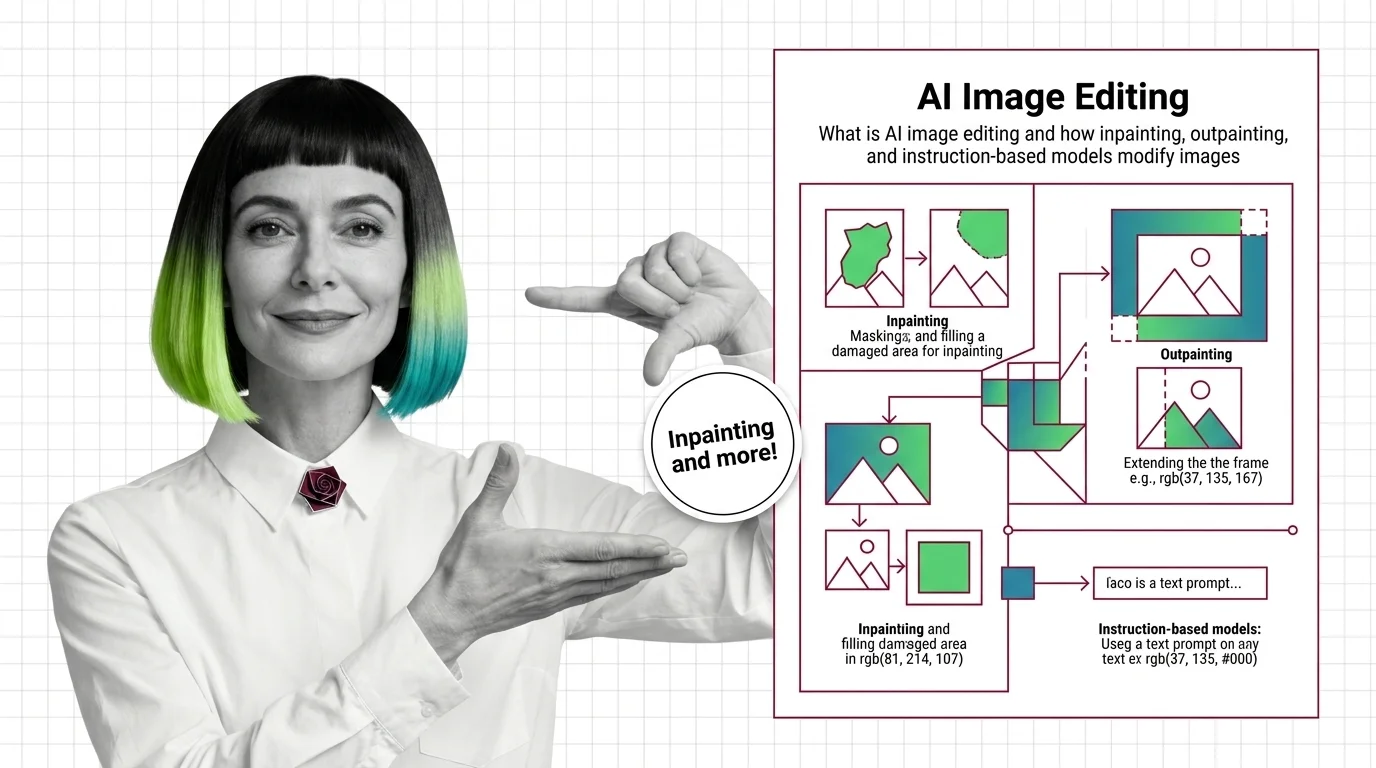
What Is AI Image Editing? Inpainting, Outpainting, Edit Models
AI image editing uses diffusion to modify pixels under a mask or follow text instructions. Learn how inpainting, …

What Is a Diffusion Model? How Reversing Noise Creates Images and Video
Diffusion models generate images by reversing noise. Learn how forward and reverse processes differ, and why predicting …

Diffusion Models in 2026: Slow Sampling and Hard Engineering Limits
Why diffusion models still need many sampling steps, why FLUX and SD 3.5 stumble on text and hands, and where the 2026 …
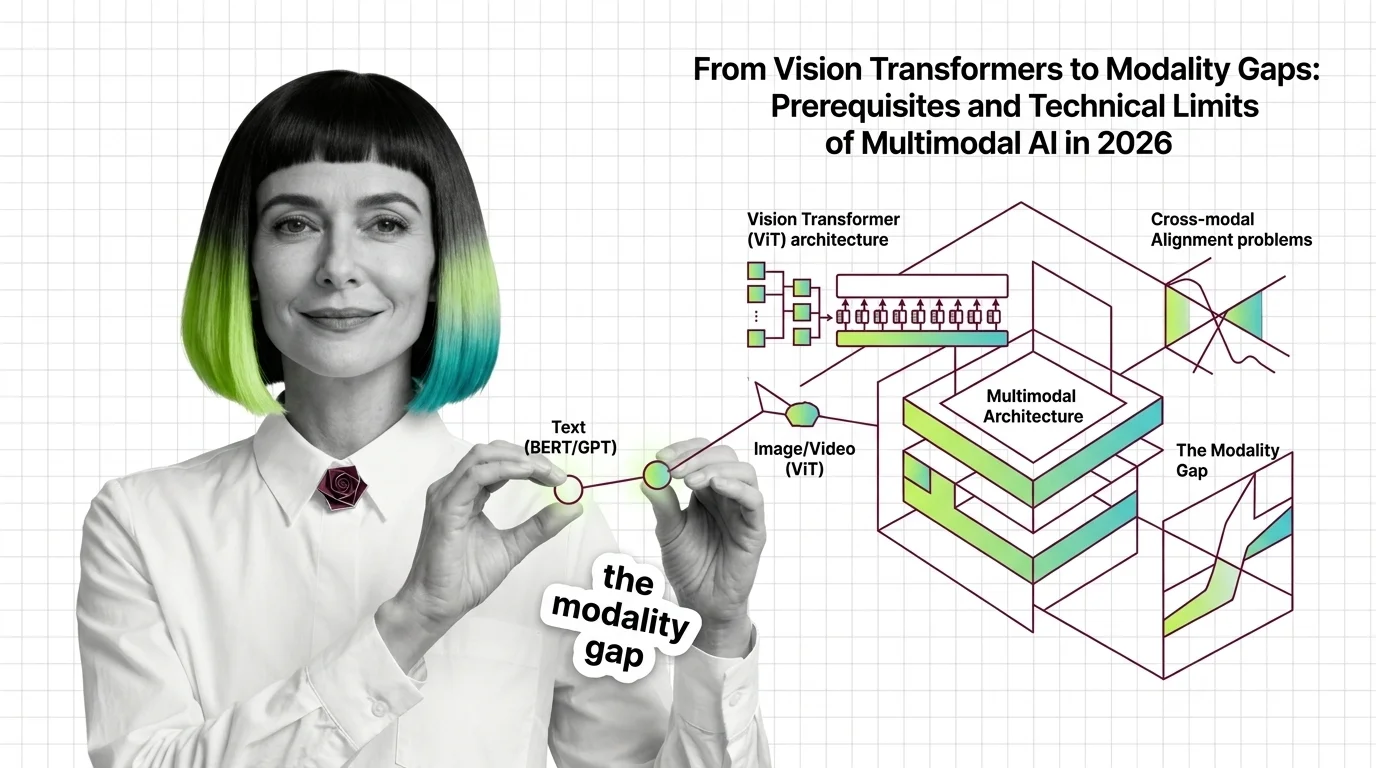
From Vision Transformers to Modality Gaps: Prerequisites and Technical Limits of Multimodal AI in 2026
Before multimodal AI works, vision transformers, modality gaps, and grounding decay define its limits. The mechanics of …
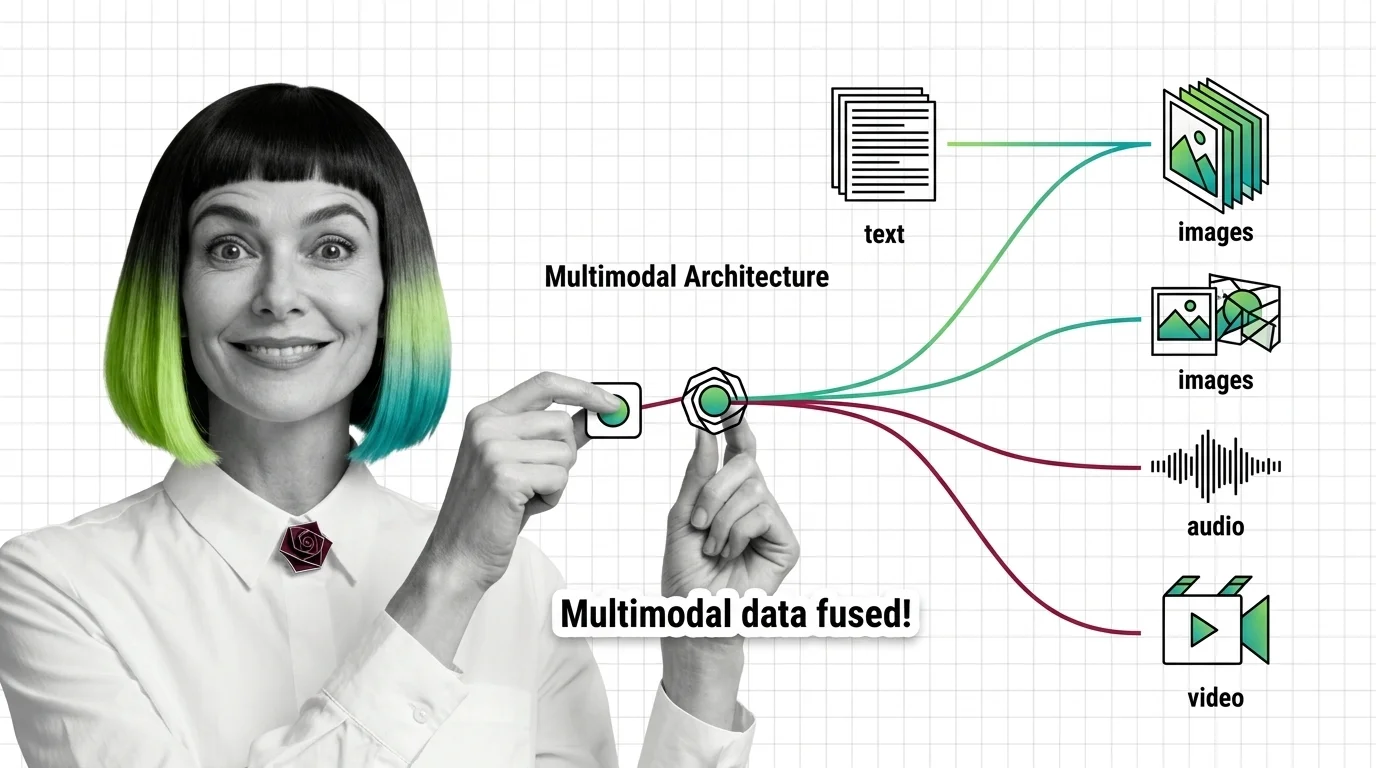
Multimodal Architecture: How Models Fuse Text, Images, Audio & Video
Multimodal models like GPT-5 and Gemini 3.1 Pro don't see images — they translate them into token space. Here's the …
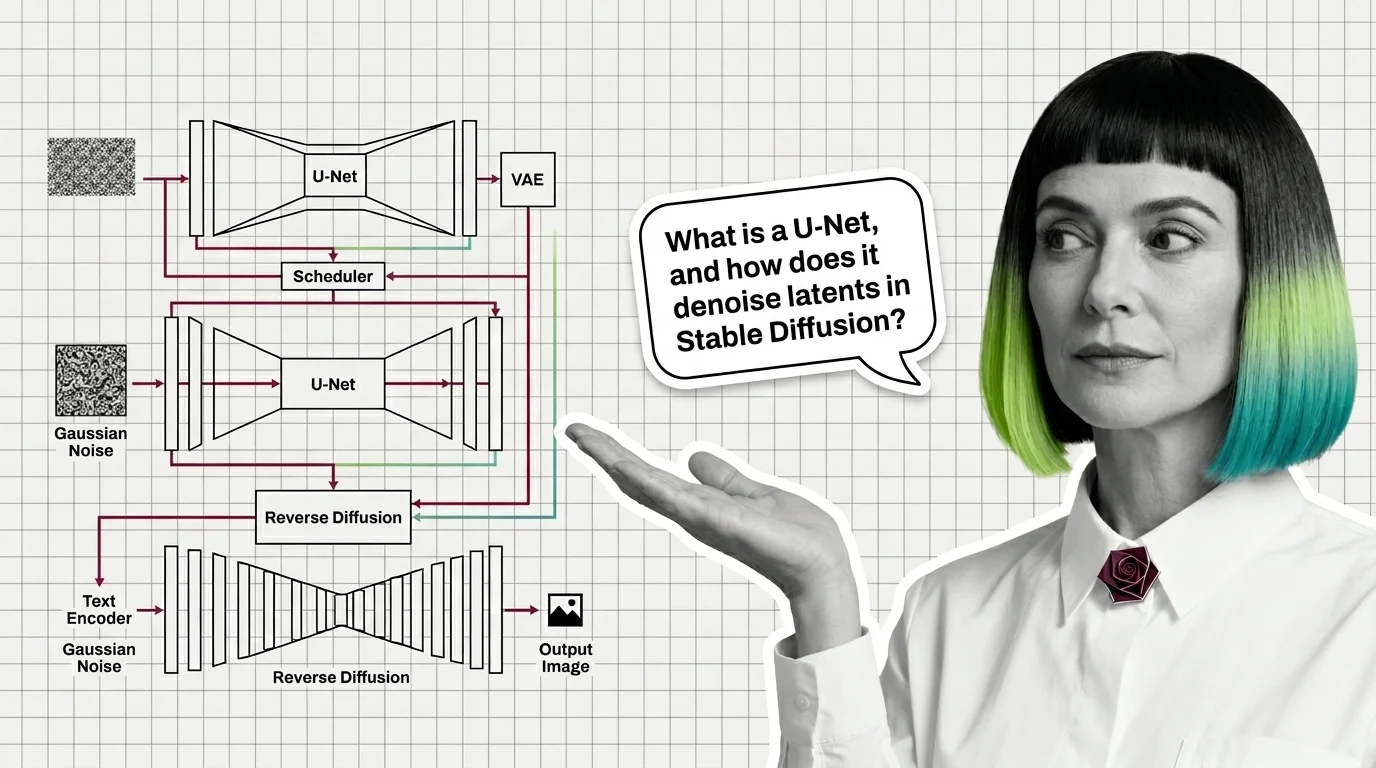
U-Net, VAE, Schedulers, and Text Encoders: The Anatomy of a Modern Diffusion Model
A modern diffusion model is not one network but four: a VAE for compression, a U-Net or DiT denoiser, a text encoder, …
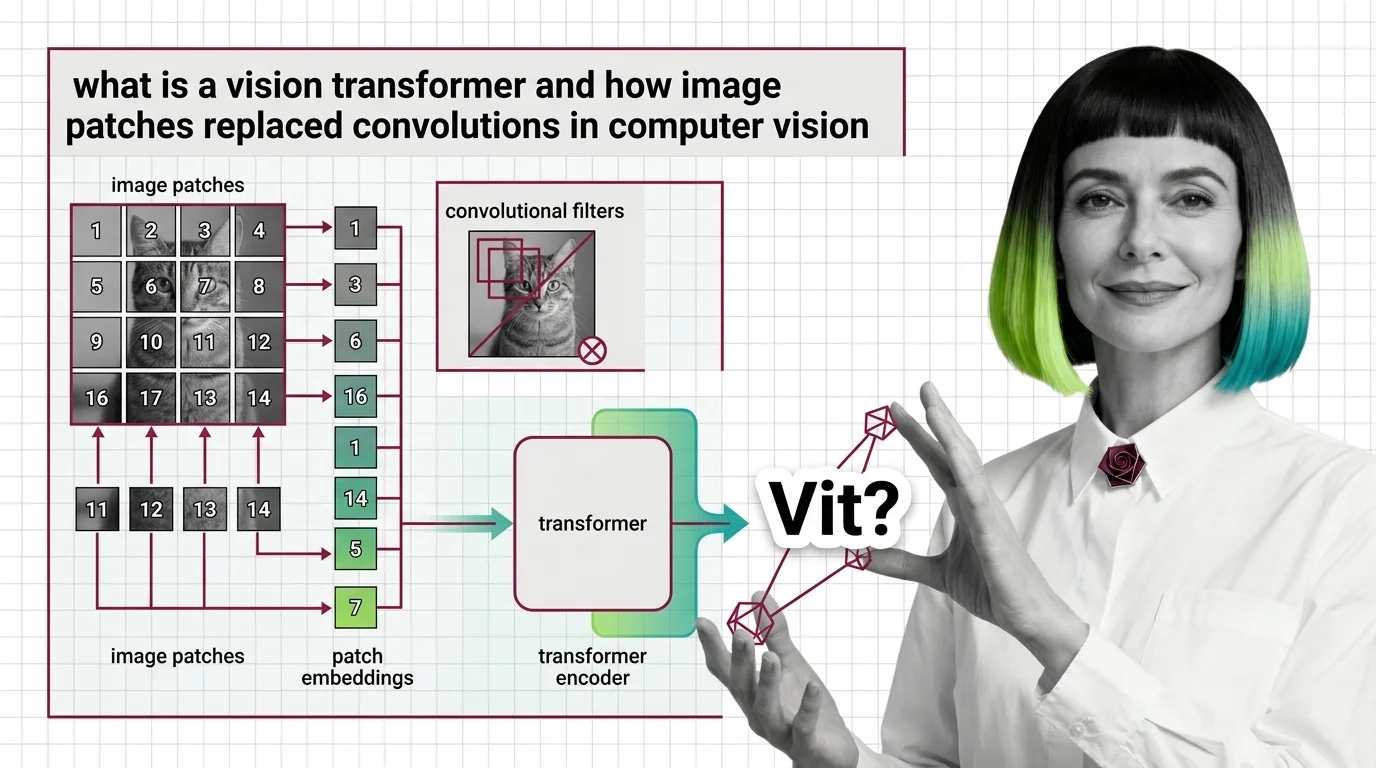
What Is a Vision Transformer and How Image Patches Replaced Convolutions in Computer Vision
Vision Transformers treat images as token sequences, not pixel grids. Learn how 16x16 patches, self-attention, and …
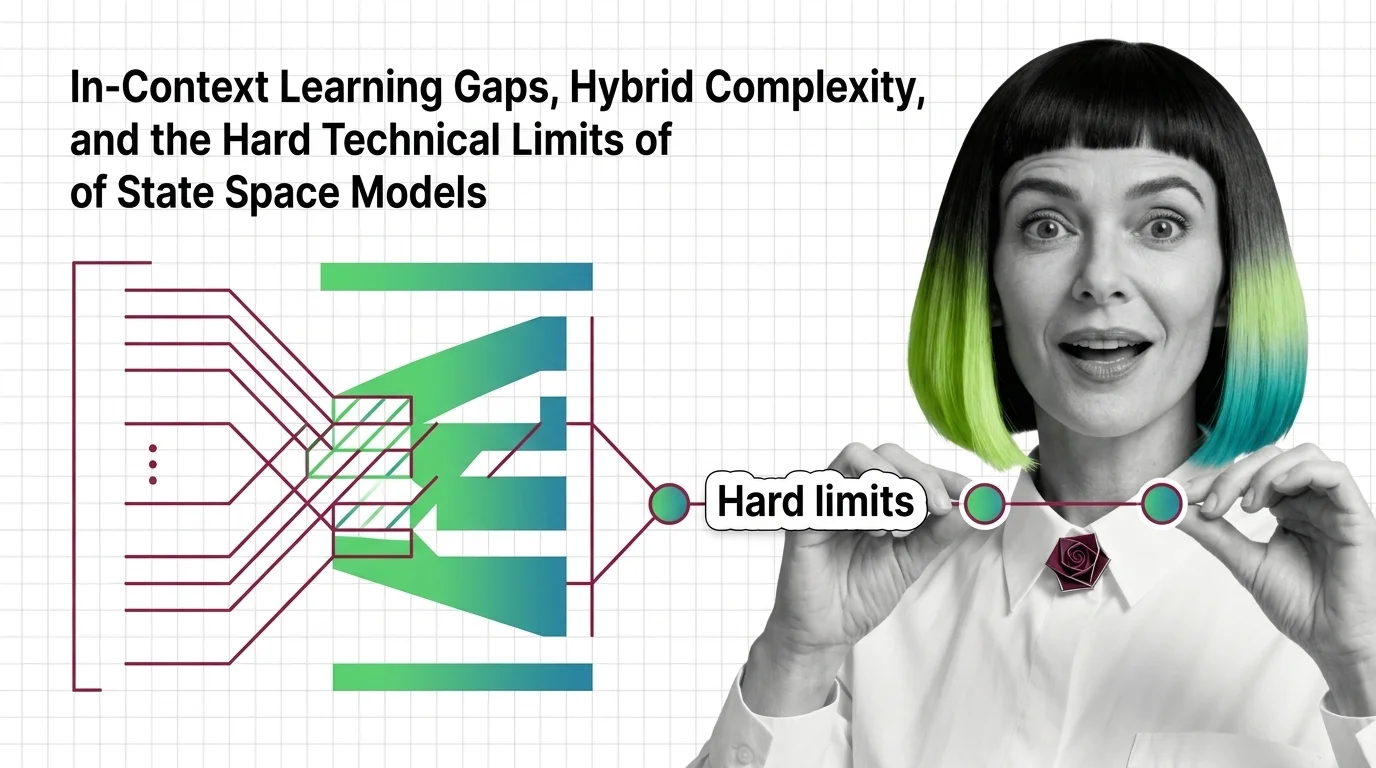
In-Context Learning Gaps, Hybrid Complexity, and the Hard Technical Limits of State Space Models
State space models trade recall for speed. Learn why pure Mamba breaks on in-context tasks and how hybrid SSM-attention …
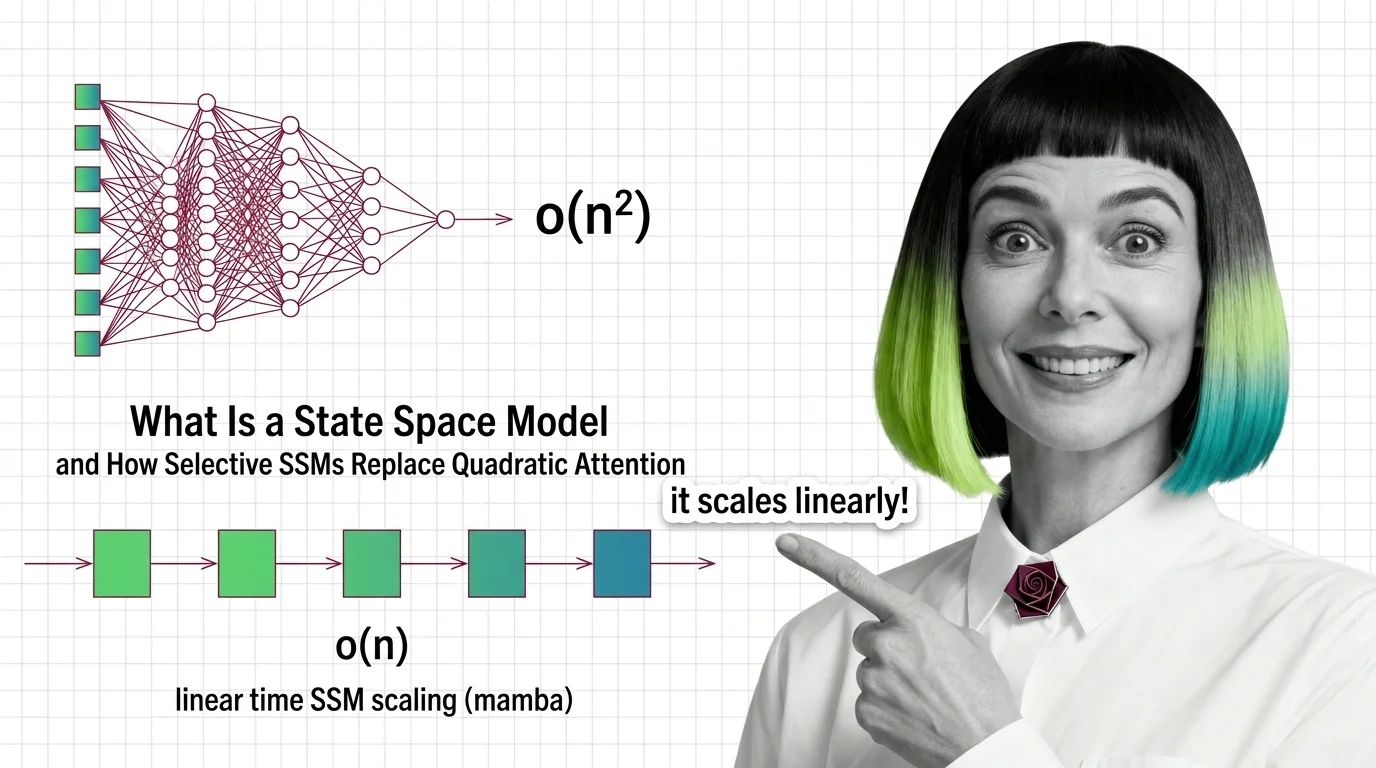
What Is a State Space Model and How Selective SSMs Replace Quadratic Attention
State space models trade quadratic attention for linear recurrence. See how Mamba's selection works and why long-context …
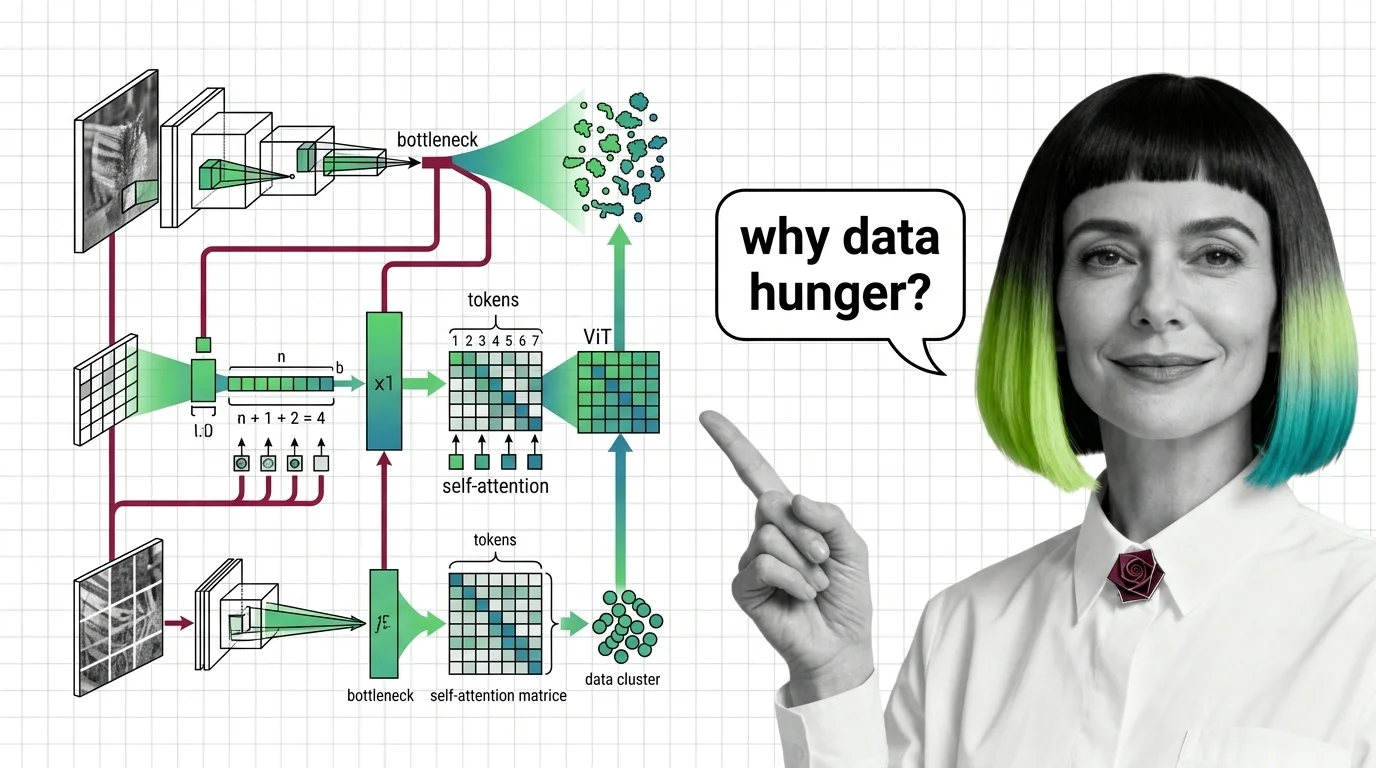
From CNN Intuition to Data Hunger: Prerequisites and Hard Limits of Vision Transformers
Vision Transformers drop CNN priors for learned attention — a trade that changes everything. Learn the prerequisites, …
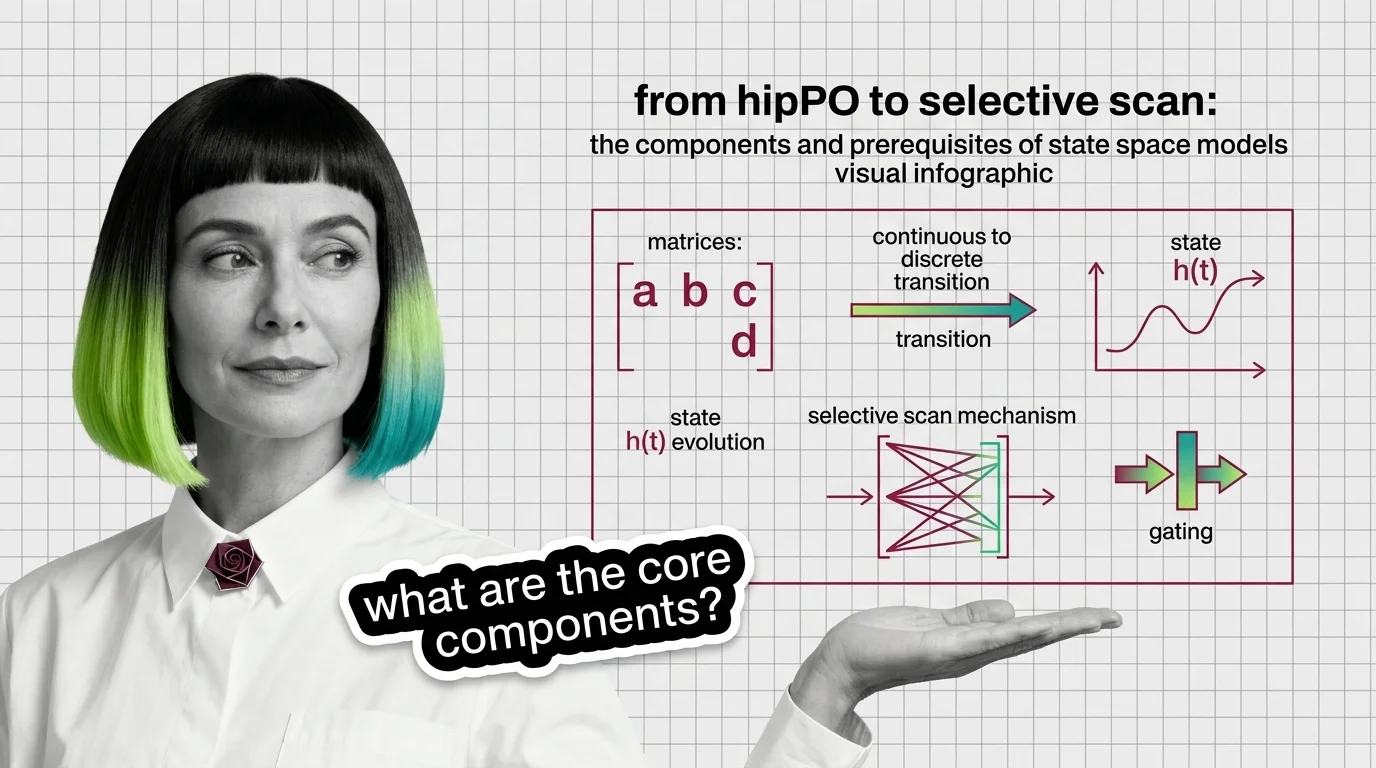
From HiPPO to Selective Scan: The Components and Prerequisites of State Space Models
State space models rebuilt recurrence on new math. Trace the components — HiPPO, S4, selective scan, gating — and the …
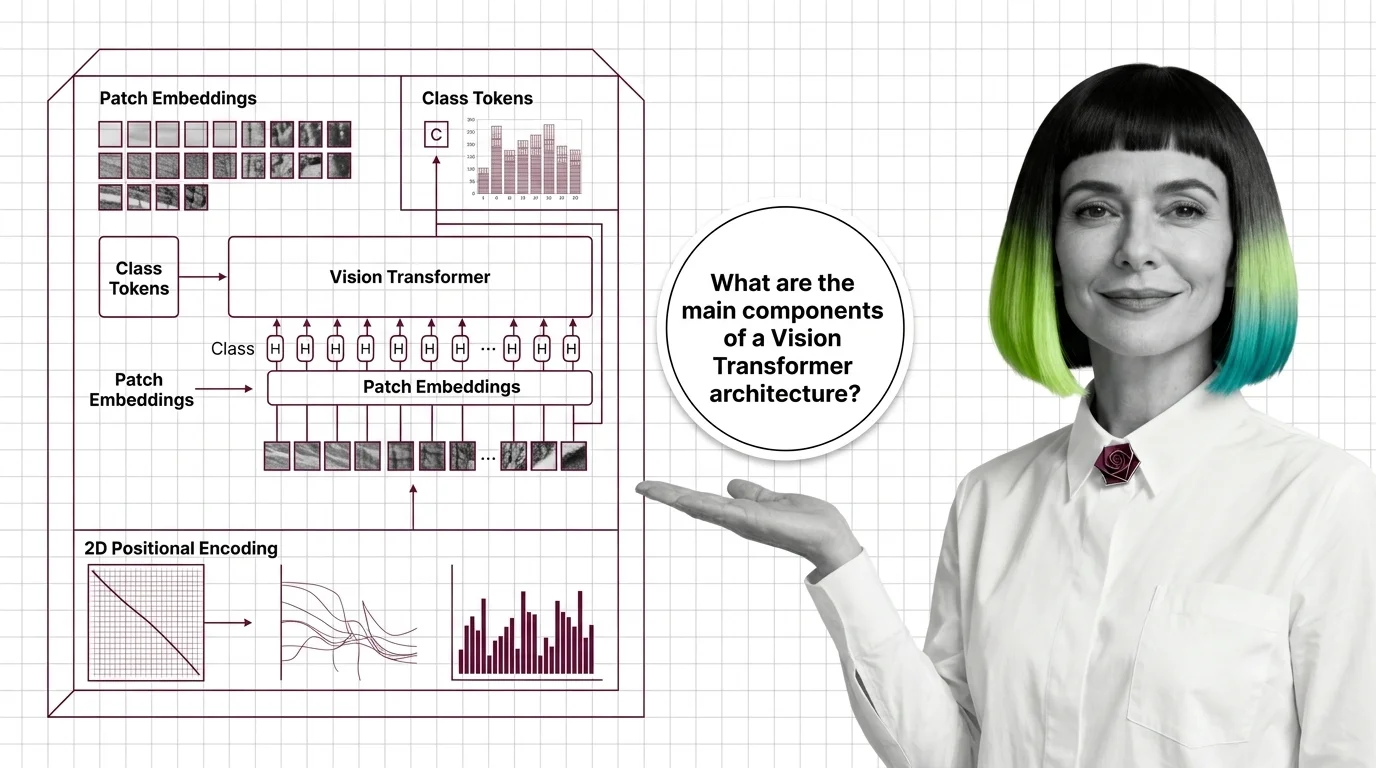
Patch Embeddings, Class Tokens, and 2D Positional Encoding: Inside the Vision Transformer
How Vision Transformers turn images into token sequences — inside patch embeddings, the CLS token, and the shift from 1D …

Routing Collapse, Load Balancing Failures, and the Hard Engineering Limits of Mixture of Experts
MoE models promise scale at fractional compute cost. Understand routing collapse, memory tradeoffs, and communication …
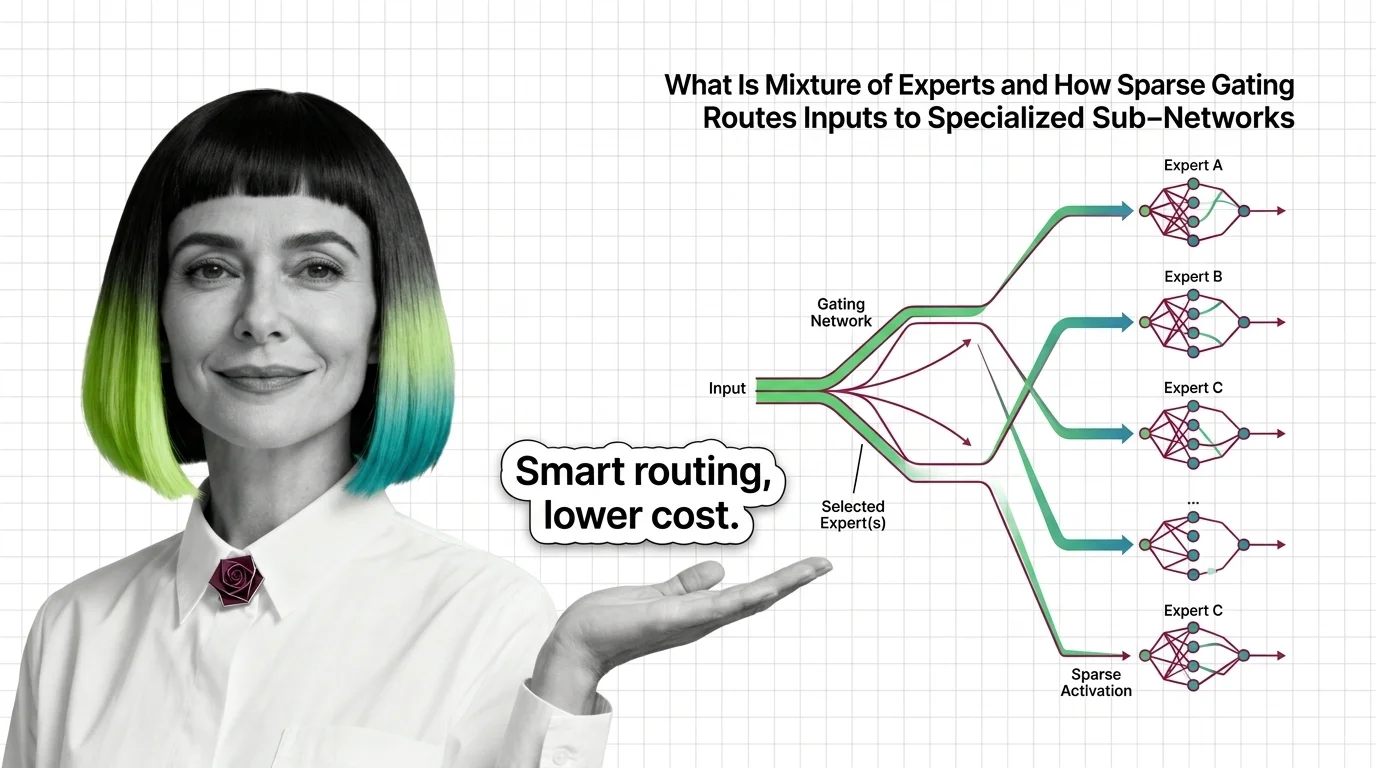
What Is Mixture of Experts and How Sparse Gating Routes Inputs to Specialized Sub-Networks
Mixture of experts activates only selected sub-networks per token. Learn how sparse gating makes trillion-parameter …
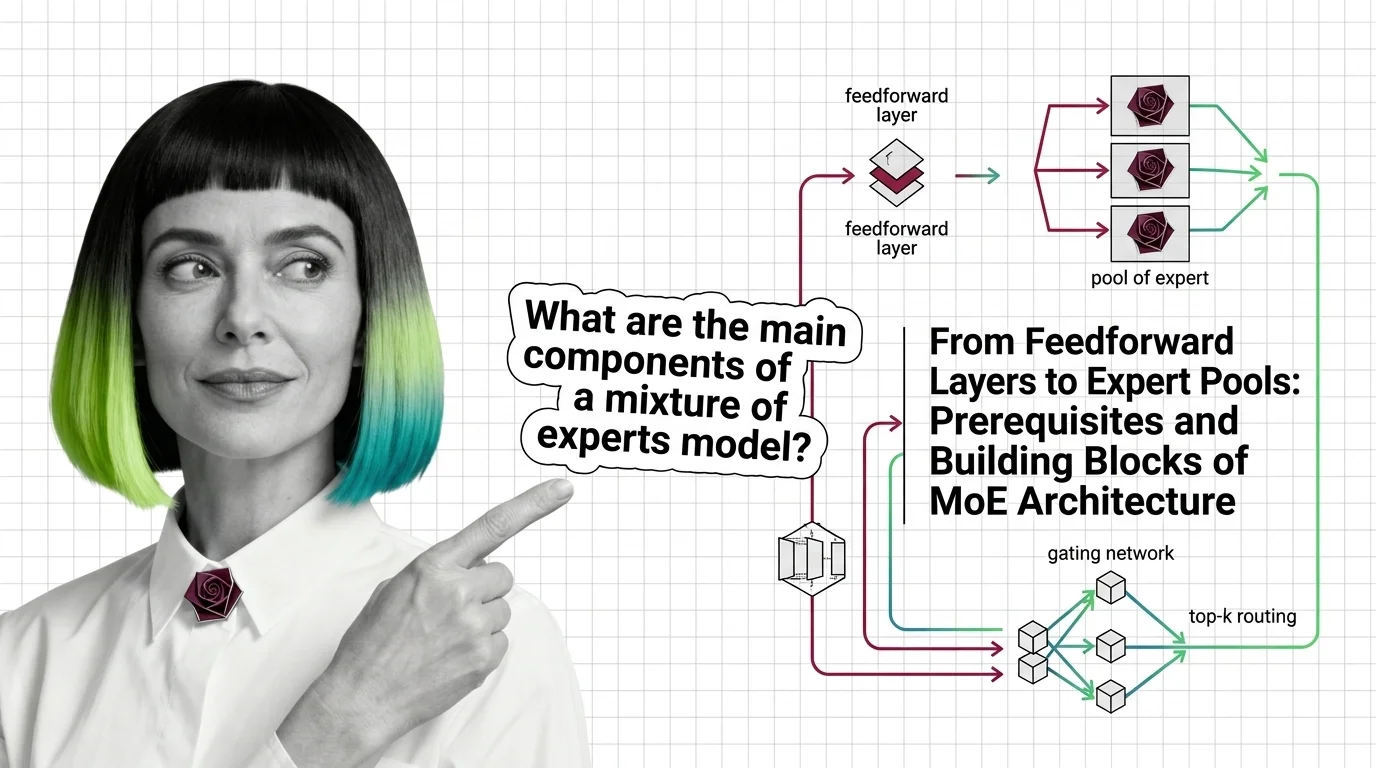
From Feedforward Layers to Expert Pools: Prerequisites and Building Blocks of MoE Architecture
Mixture of experts replaces one feedforward layer with many expert networks and a router. Learn how MoE gating and …