Explainer Articles
In-depth explanations of AI concepts, architectures, and principles. Educational content that breaks down complex topics into understandable insights.
- Home /
- Explainer Articles
What Are Retrieval-Augmented Agents and How They Combine Agentic Reasoning with Dynamic Retrieval
What Are Retrieval-Augmented Agents and How They Combine Agentic Reasoning with Dynamic Retrieval …

Cold Starts, Flaky Tests, and Context Blowup: The Technical Limits of Code Execution Agents in 2026
Cold Starts, Flaky Tests, and Context Blowup: The Technical Limits of Code Execution Agents in 2026 …

What Are Code Execution Agents and How Sandboxed Interpreters Let LLMs Run Their Own Code
What Are Code Execution Agents and How Sandboxed Interpreters Let LLMs Run Their Own Code ELI5
What Is Workflow Orchestration for AI and How DAGs, State Machines, and Conditional Branching Structure LLM Pipelines
What Is Workflow Orchestration for AI and How DAGs, State Machines, and Conditional Branching …
DAGs vs. State Machines, Retry Logic, and the Hard Technical Limits of AI Workflow Orchestration
DAGs vs. State Machines, Retry Logic, and the Hard Technical Limits of AI Workflow Orchestration …

Agent Error Handling: How Agents Recover From Tool and LLM Failures
Agent error handling turns brittle LLM loops into resilient systems. Learn how guardrails, retries, and checkpoints …
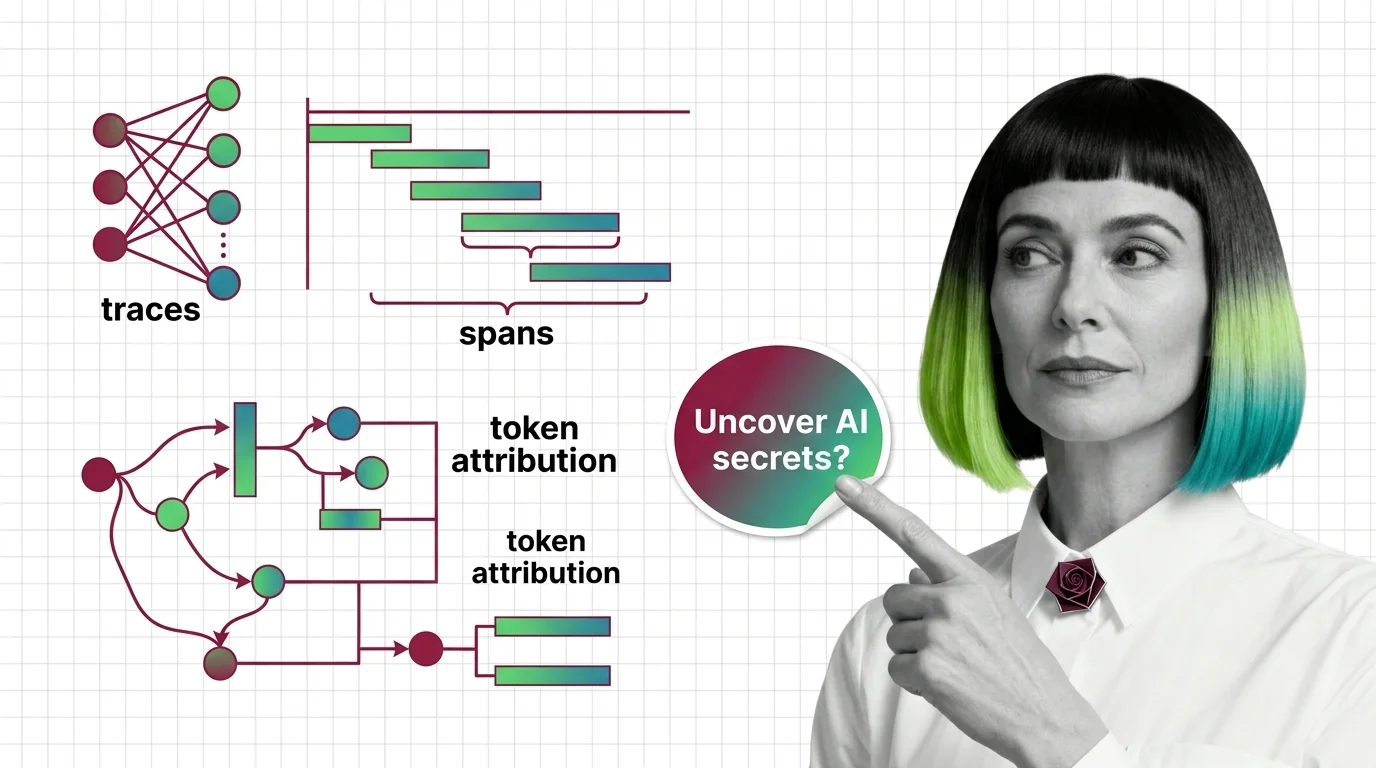
What Is Agent Observability? Traces, Spans, and Token Attribution
Agent observability records every step an AI agent takes. Learn how traces, spans, and token attribution reveal what …
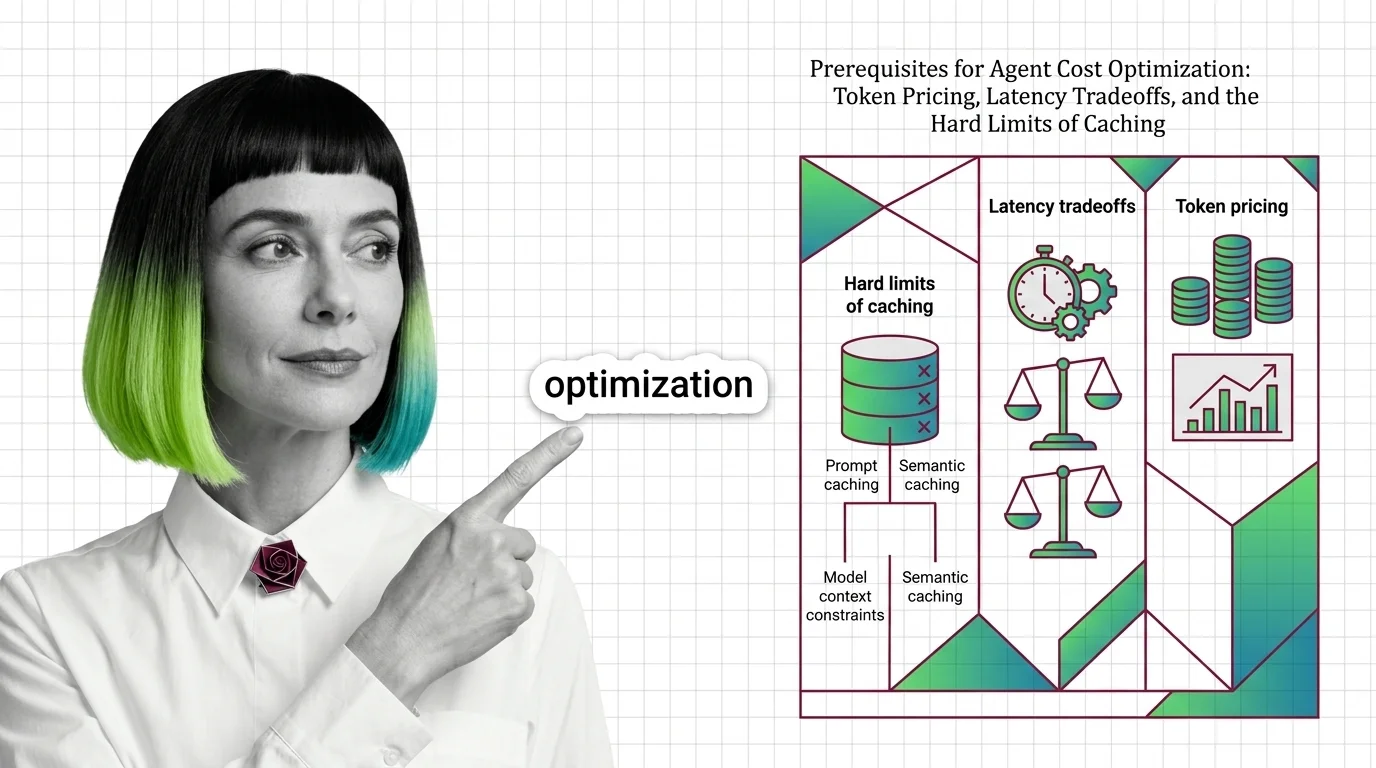
Agent Cost Optimization Prerequisites: Pricing, Latency, Caching Limits
Before optimizing agent costs, understand token pricing asymmetry, prefill vs decode latency, and why prompt and …
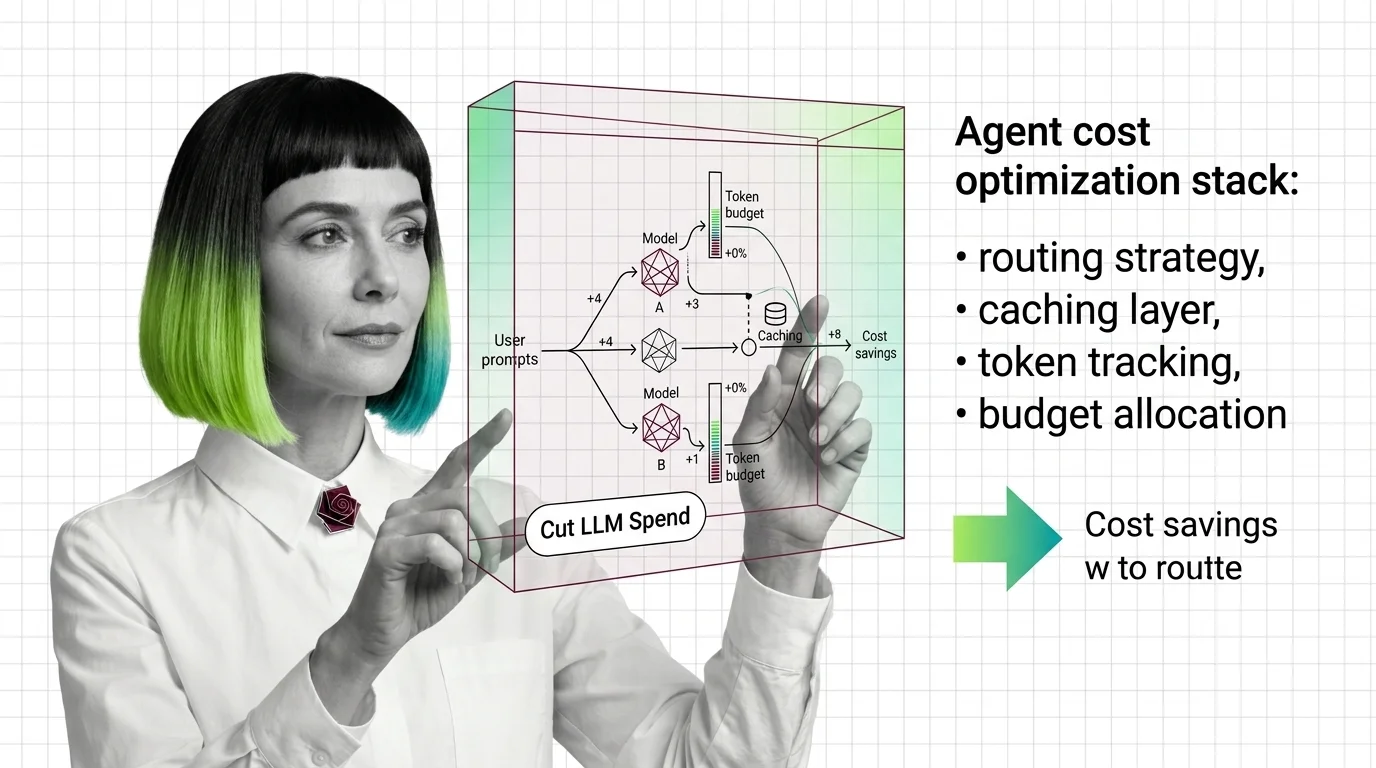
Agent Cost Optimization: Routing, Caching, and Token Budgets for LLMs
Agent cost optimization routes requests to the right model, caches reusable computation, and caps runaway loops before …

OpenTelemetry GenAI: Prerequisites and Limits of Agent Tracing
OpenTelemetry GenAI semconv is still in Development. What you need to know about tracing prerequisites and hard limits …
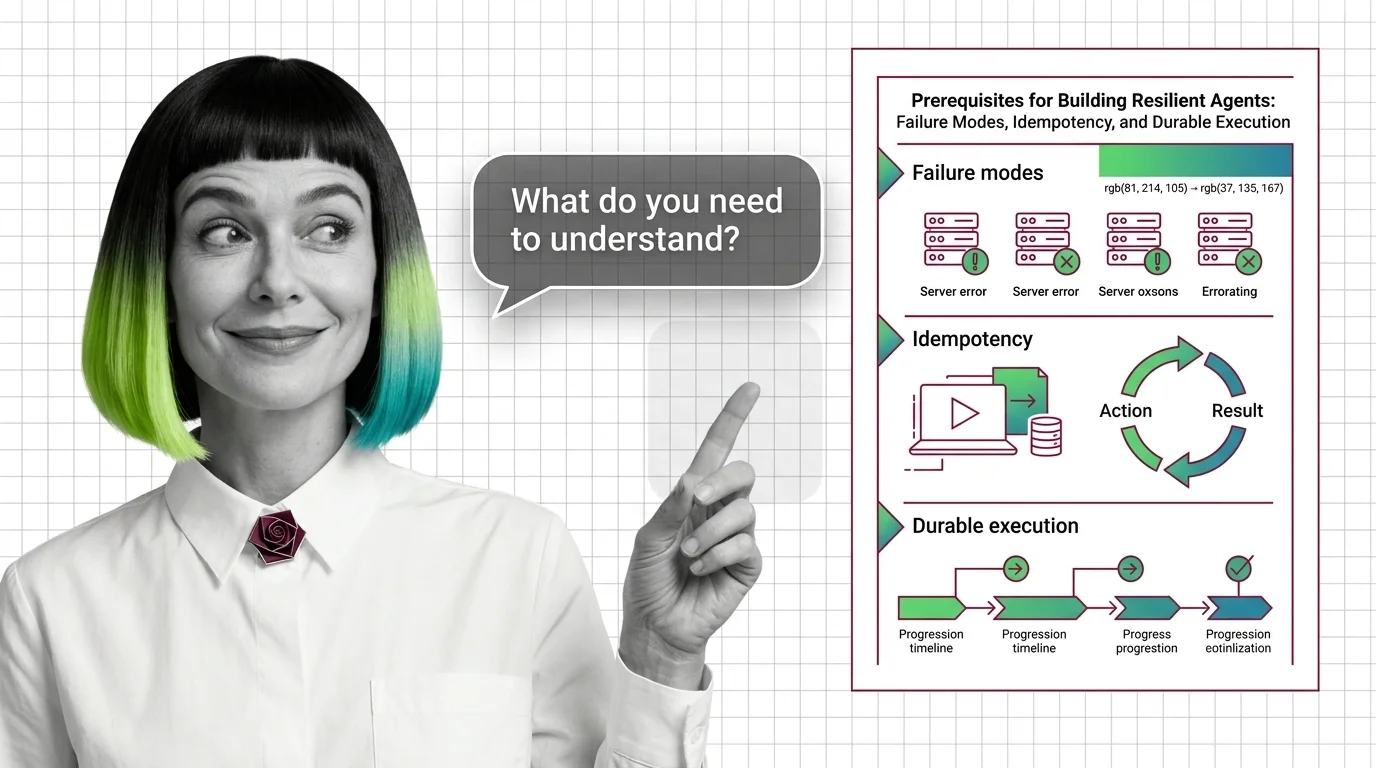
Resilient AI Agents: Failure Modes, Idempotency, Durable Execution
Reliable AI agents need three foundations: a failure-mode taxonomy, idempotent action boundaries, and durable execution …

What Are Agent Guardrails? How Permission Systems Constrain AI
Agent guardrails enforce permission boundaries on autonomous AI. Learn how Claude SDK, NeMo, and Llama Guard constrain …

Human-in-the-Loop for AI Agents: How Approval Gates Work
Human-in-the-loop for AI agents pauses autonomous workflows at risky steps and routes them to a human gate. Here's how …
Prerequisites and Technical Limits of HITL for AI Agents
HITL for agents is easy to start and hard to scale. Learn the prerequisites — durable state, idempotency, escalation — …
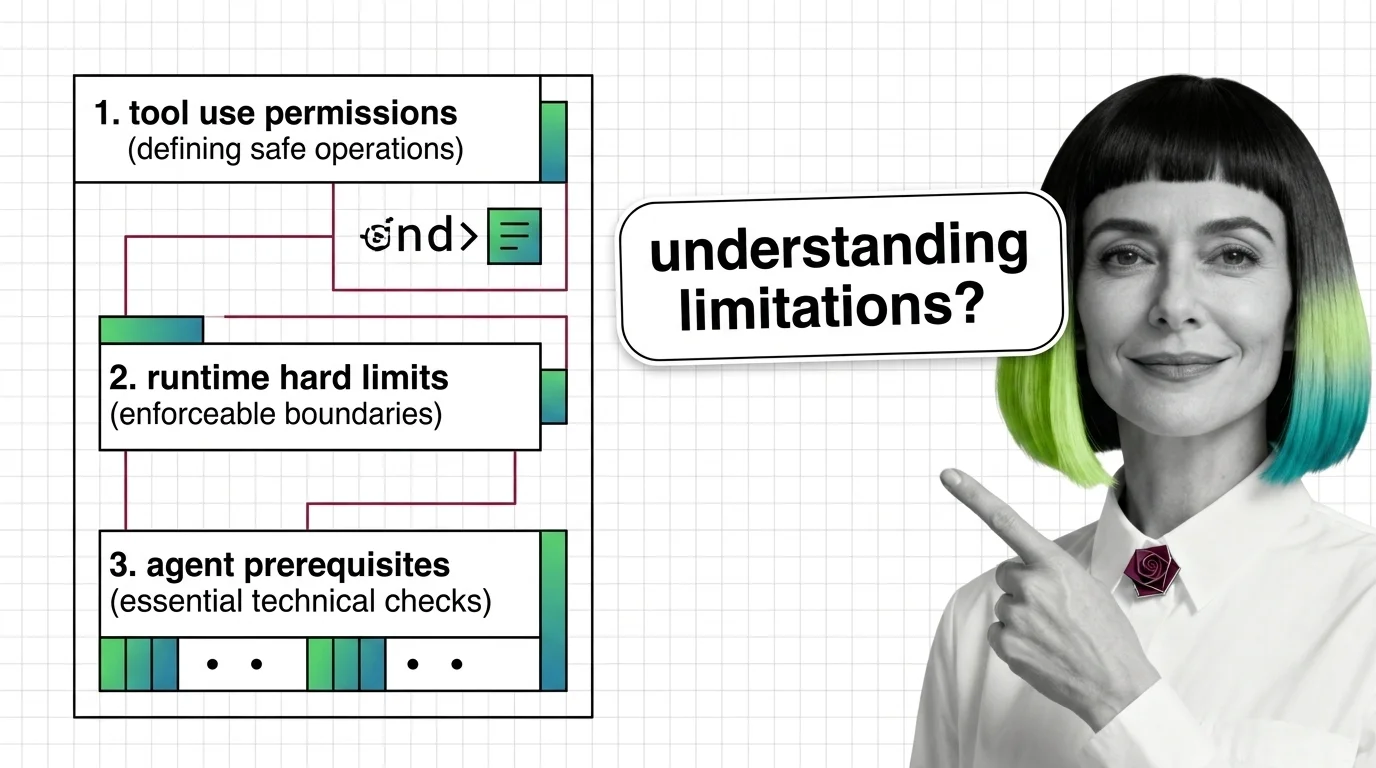
Prerequisites for Agent Guardrails: Tool Use and Runtime Limits
Agent guardrails are runtime classifiers wrapped around tool-use loops — useful, partial, and demonstrably evadable. …

Agent State Management: How Checkpointing Persists Memory Across Turns
Agent state management decides whether your agent remembers. See how LangGraph checkpointers, threads, and reducers …
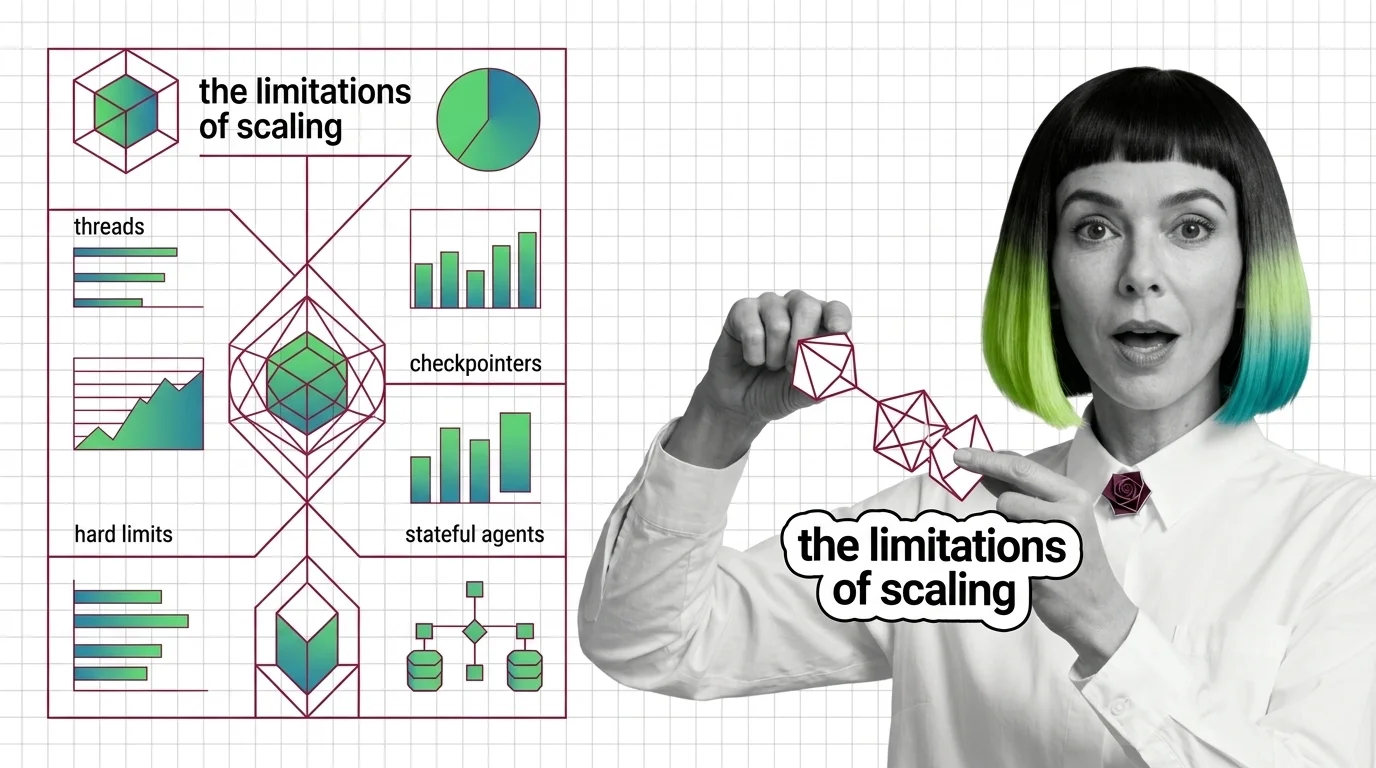
Agent State Management: Threads, Checkpointers, Hard Limits
Agent state is not memory — it is plumbing that replays snapshots between steps. Mona explains threads, checkpointers, …
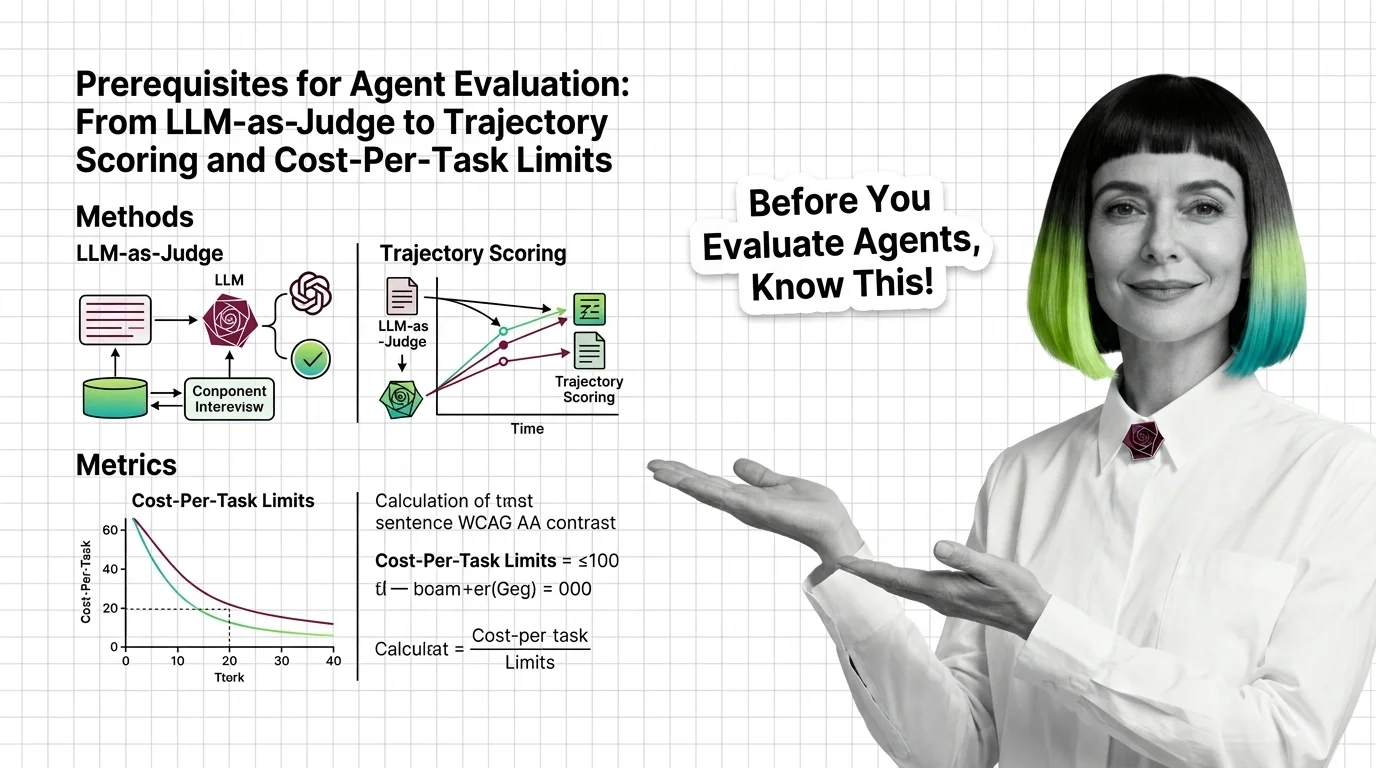
Agent Evaluation Prerequisites: LLM-as-Judge to Cost-Per-Task
Agent evaluation needs three signals: outcome, trajectory, cost. Learn why LLM-as-judge has known biases and where major …

Agent Evaluation: How Trajectory Analysis Measures AI Agents
Agent evaluation grades the path, not just the final answer. Learn how trajectory analysis exposes silent reasoning …
From Chain-of-Thought to Tool Use: Prerequisites and Technical Limits of Agent Planning
Agent planning rests on three primitives — chain-of-thought, tool use, and the ReAct loop. Learn the prerequisites and …

Multi-Agent Systems: Prerequisites and Hard Technical Limits
Before multi-agent systems, master tool use, the ReAct loop, and memory. Then face the limits: context blow-up, error …
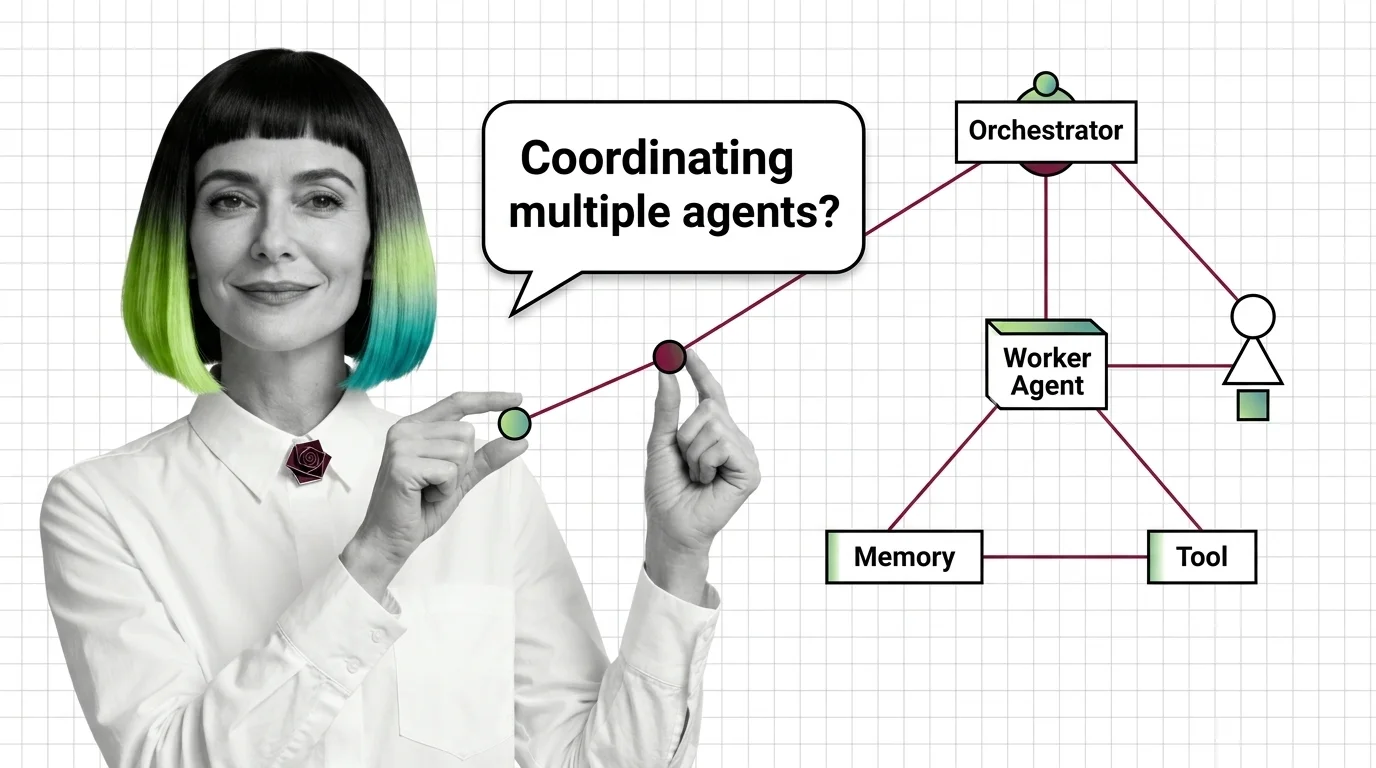
Multi-Agent Systems: Supervisor, Debate, and Swarm Patterns
Multi-agent systems coordinate specialized AI agents through supervisor, debate, or swarm patterns. Here is how each …
Agent Memory Systems: How LLMs Get Persistent Recall Across Sessions
Agent memory systems give LLMs persistent recall across sessions. Inside the architectures: temporal graphs, …

Agent Frameworks: How LangGraph, CrewAI, and AutoGen Orchestrate LLMs
Agent frameworks orchestrate LLM calls, tools, and memory — but each one bets on a different abstraction. Learn what …
Agent Memory Architectures: Prerequisites and Hard Limits
Agent memory isn't a bigger context window. Learn the prerequisites for designing agent memory systems and the hard …
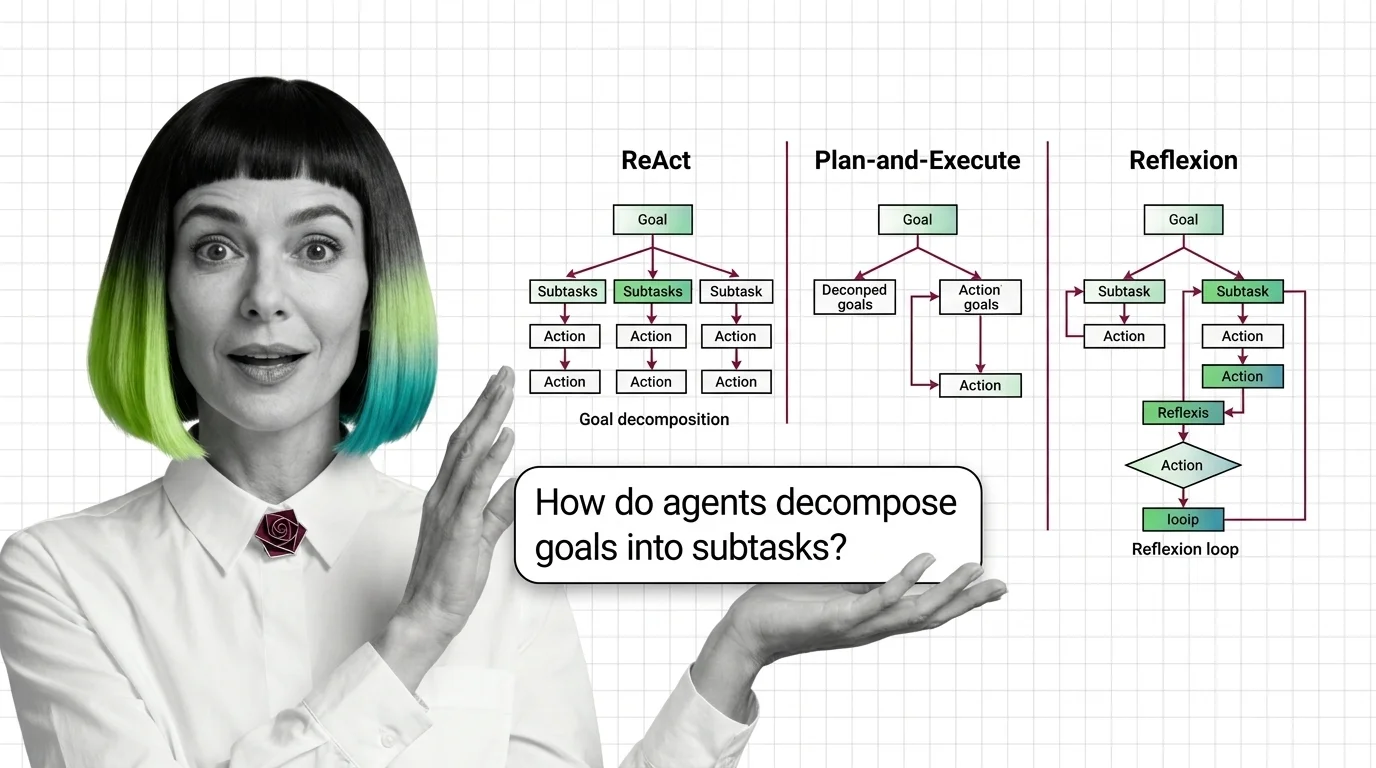
Agent Planning and Reasoning: ReAct, Plan-and-Execute, Reflexion
Agent planning is not human cognition — it is token generation conditioned on observations. How ReAct, Plan-and-Execute, …
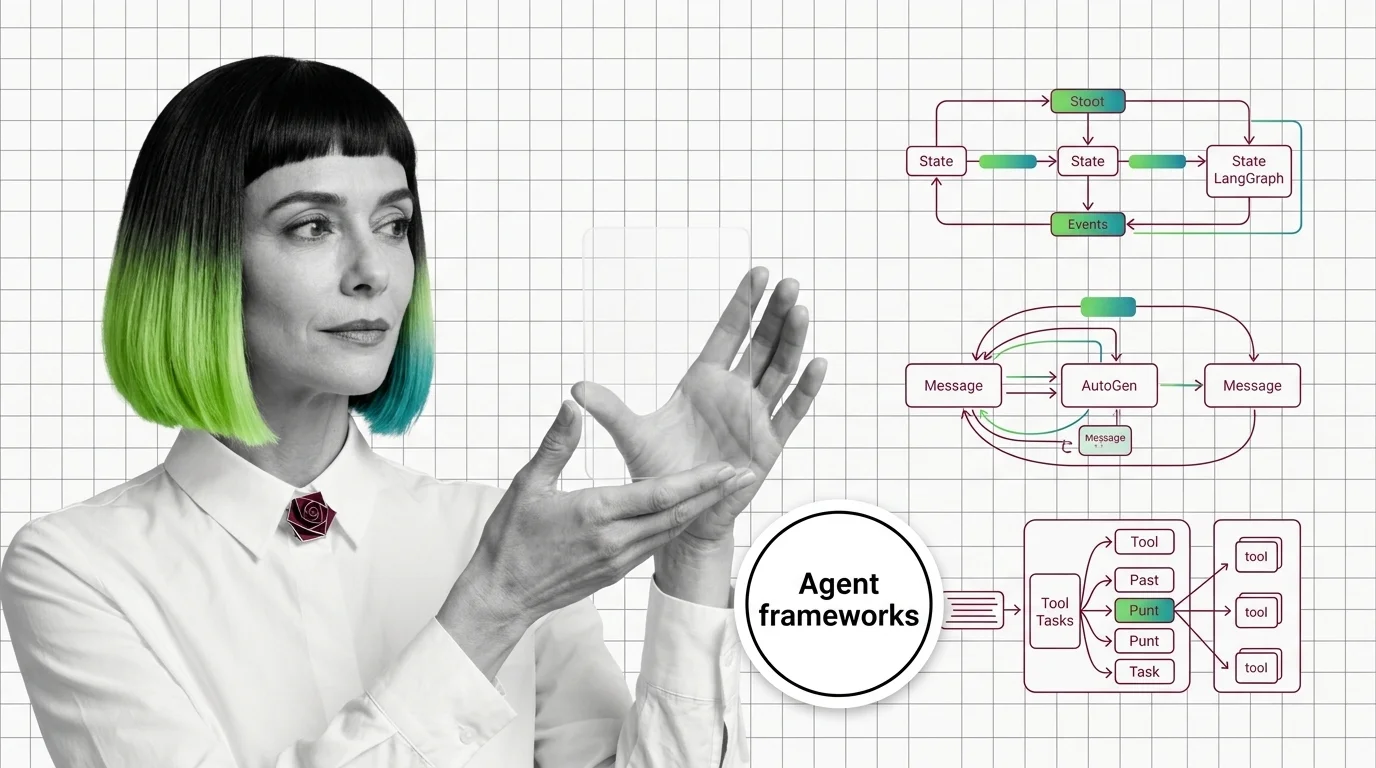
Graph vs Conversation vs Crew: LangGraph, AutoGen, CrewAI Patterns
LangGraph, AutoGen, and CrewAI commit to three different theories of how AI agents coordinate. The pattern you pick …
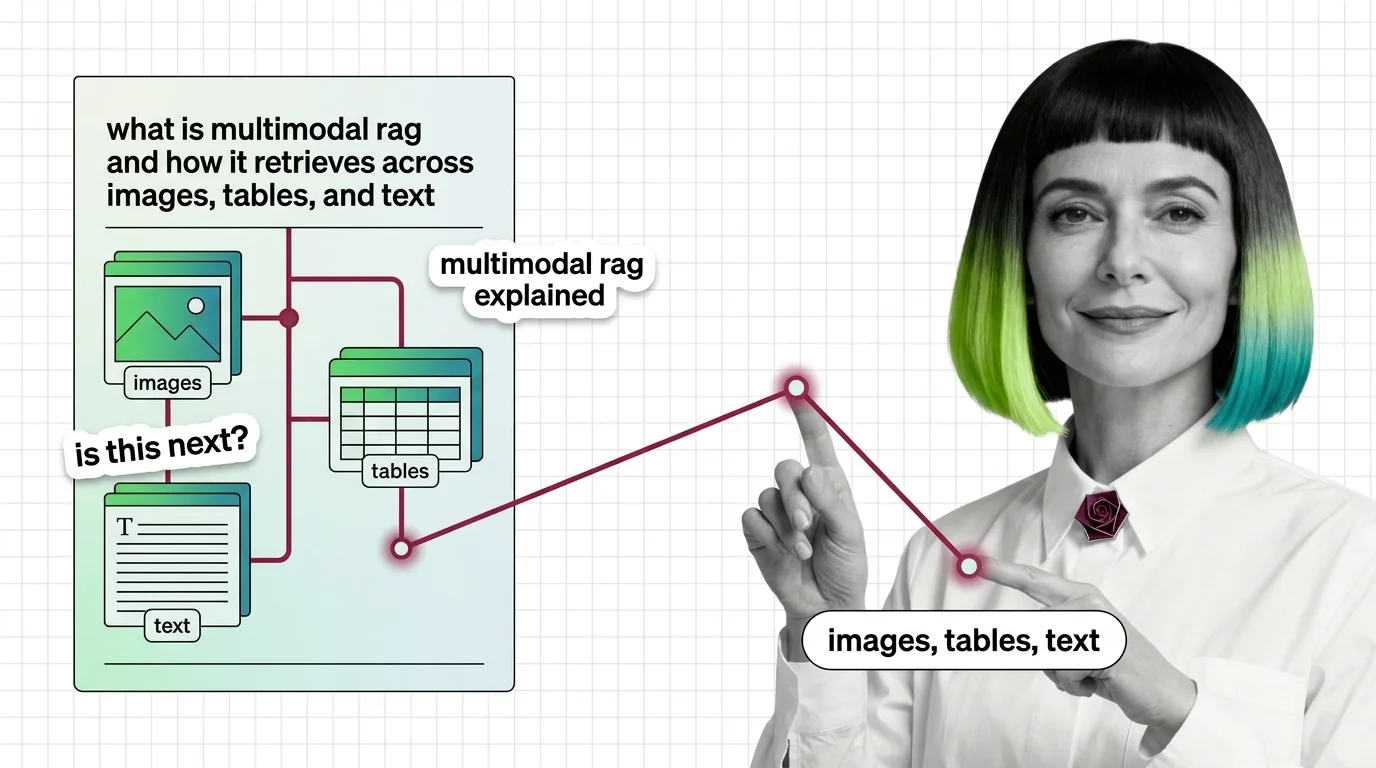
What Is Multimodal RAG and How It Retrieves Across Images, Tables, and Text
Multimodal RAG isn't text RAG with images bolted on. Learn how unified embeddings, text summaries, and vision-first …
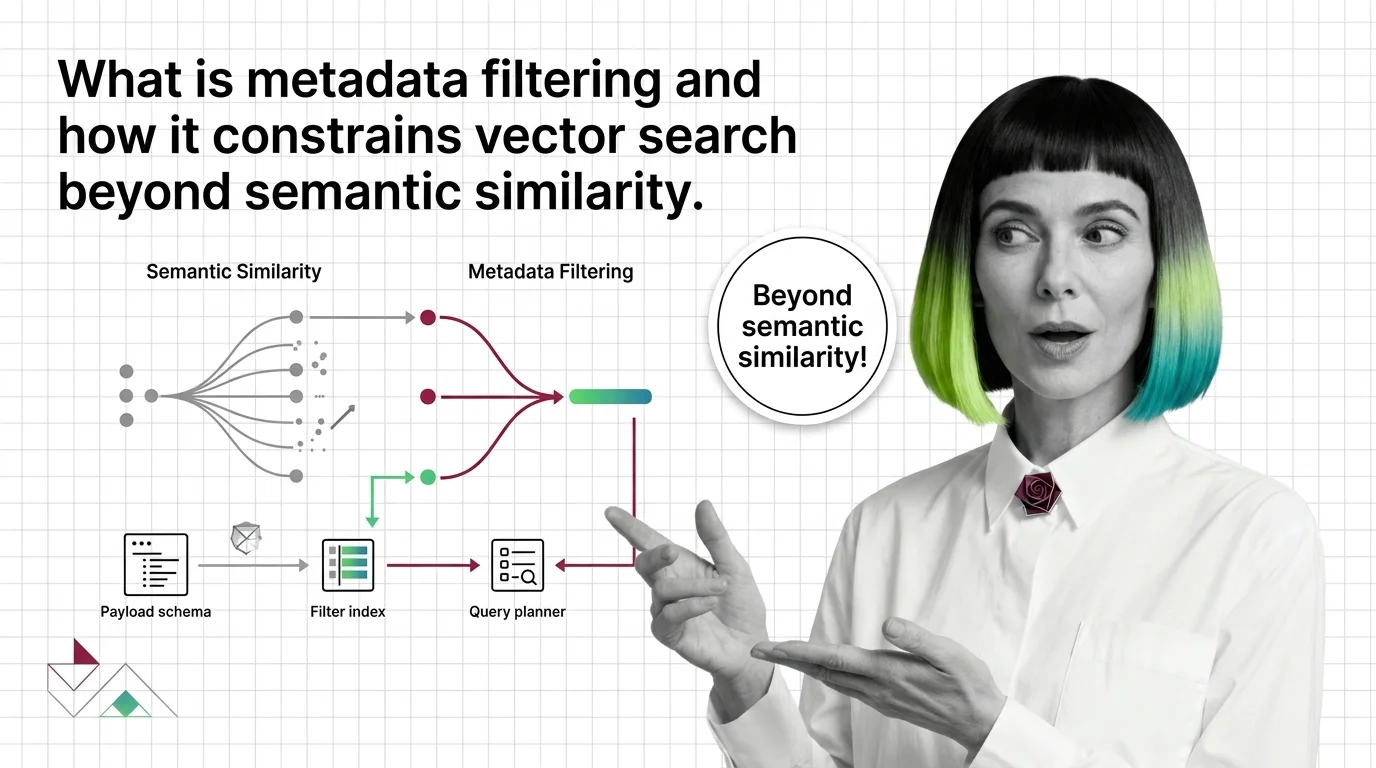
What Is Metadata Filtering and How It Constrains Vector Search Beyond Semantic Similarity
Metadata filtering attaches typed key-value payloads to each vector and applies predicates during search, narrowing …