Explainer Articles
In-depth explanations of AI concepts, architectures, and principles. Educational content that breaks down complex topics into understandable insights.
- Home /
- Explainer Articles
From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that …
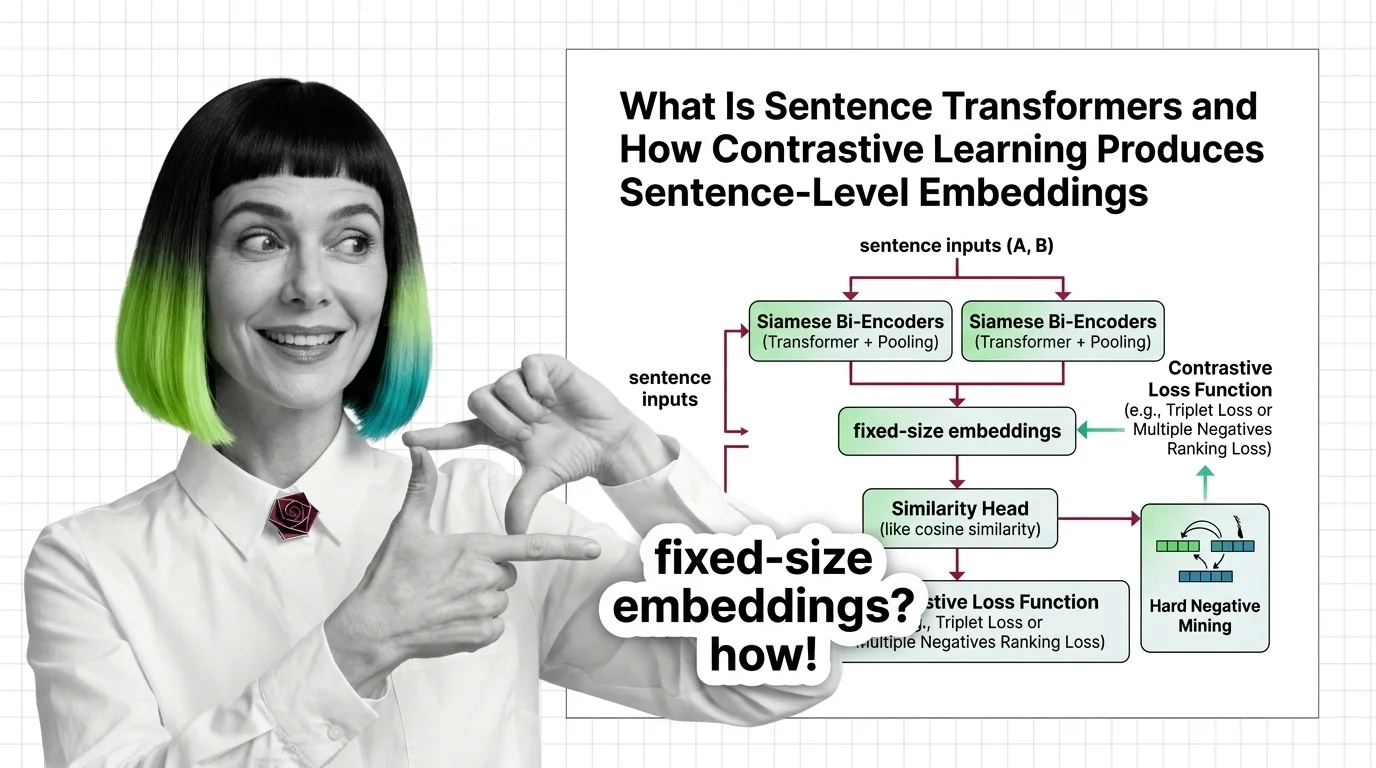
What Is Sentence Transformers and How Contrastive Learning Produces Sentence-Level Embeddings
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss …

From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search
Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and …
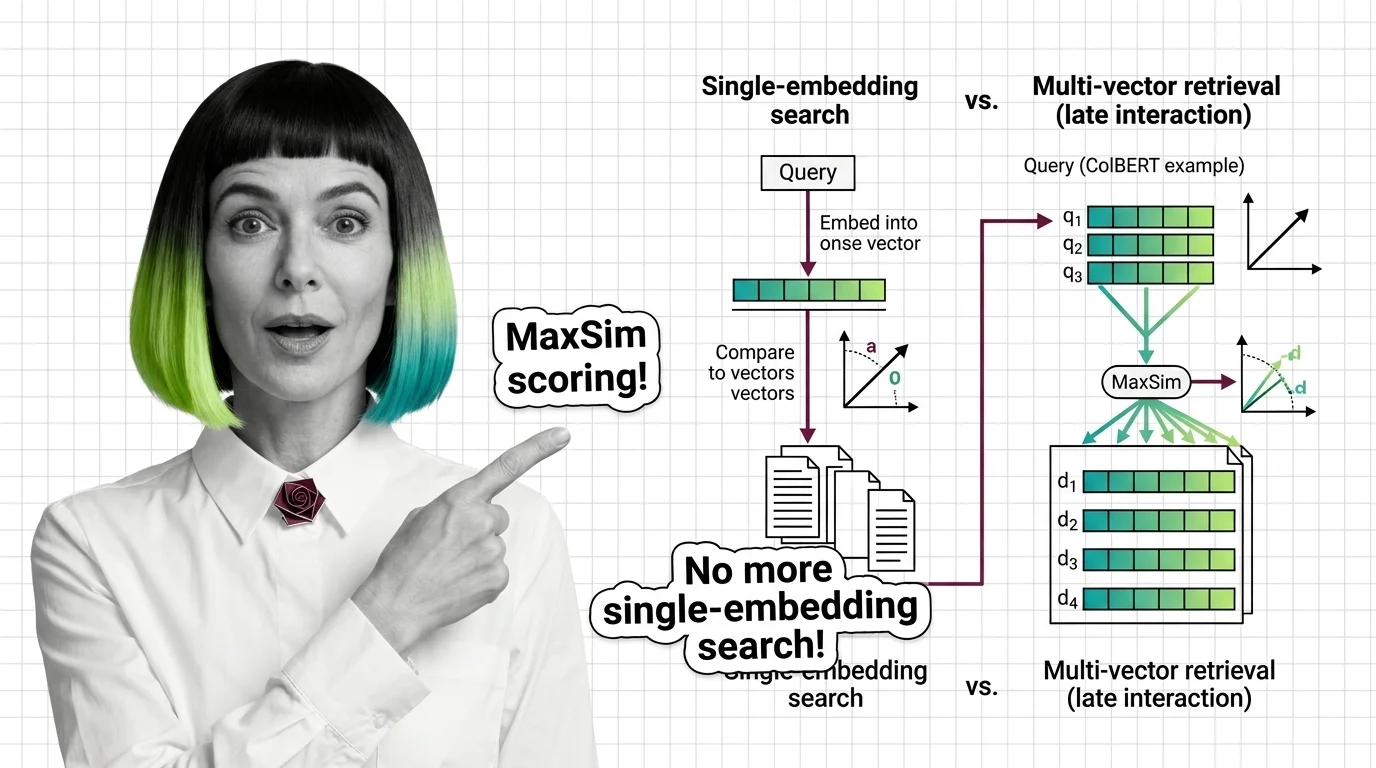
What Is Multi-Vector Retrieval and How Late Interaction Replaces Single-Embedding Search
Multi-vector retrieval stores per-token embeddings instead of one vector per document. Learn how ColBERT MaxSim scoring …

From Distance Metrics to Graph Traversal: Prerequisites for Understanding Vector Index Internals
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and …
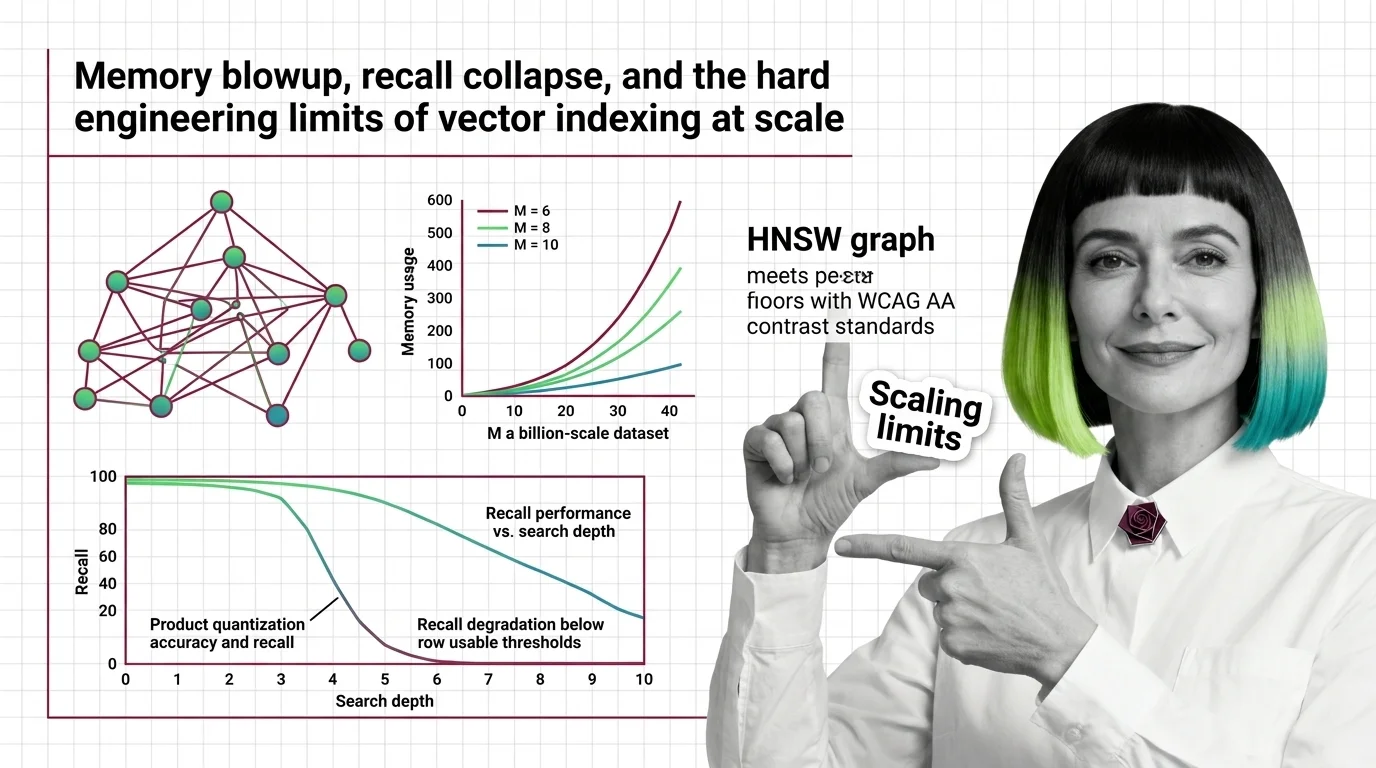
Memory Blowup, Recall Collapse, and the Hard Engineering Limits of Vector Indexing at Scale
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where …
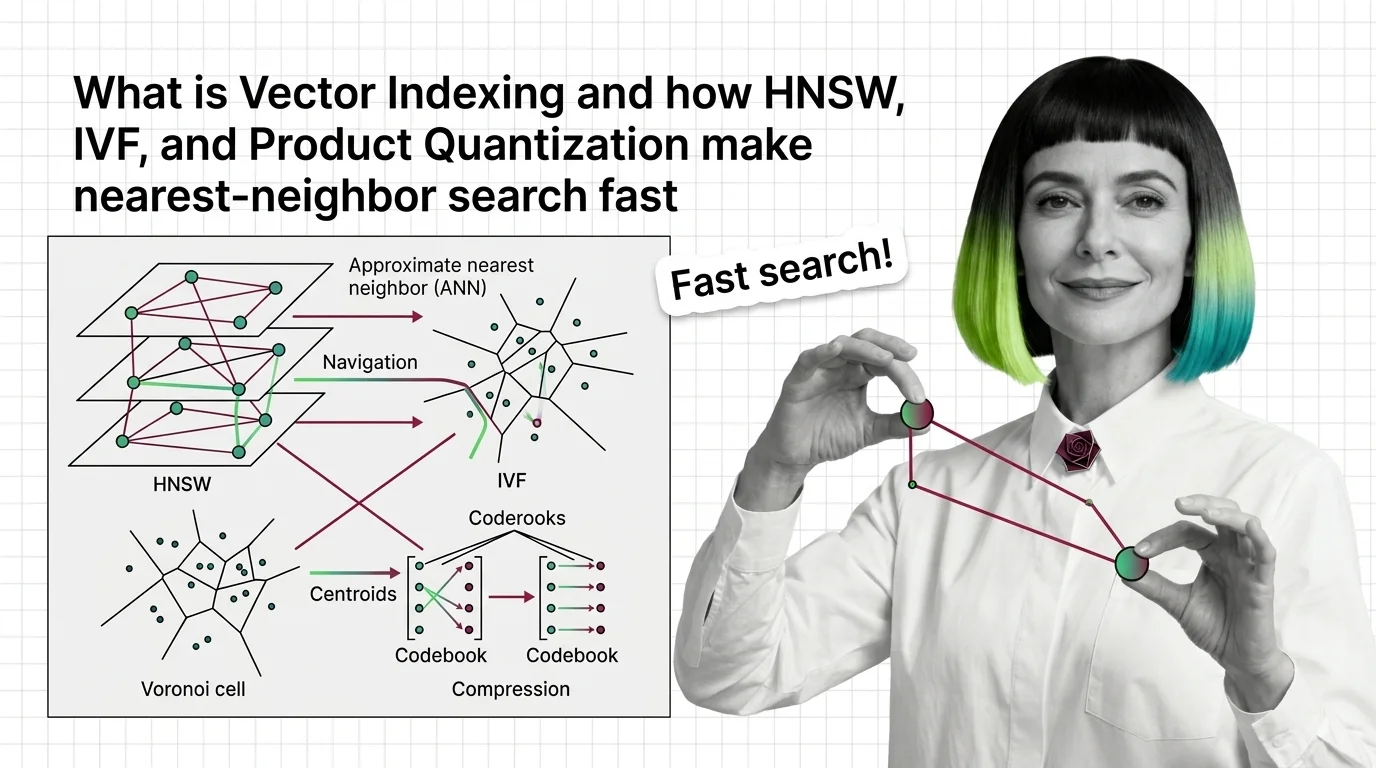
What Is Vector Indexing and How HNSW, IVF, and Product Quantization Make Nearest-Neighbor Search Fast
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and …
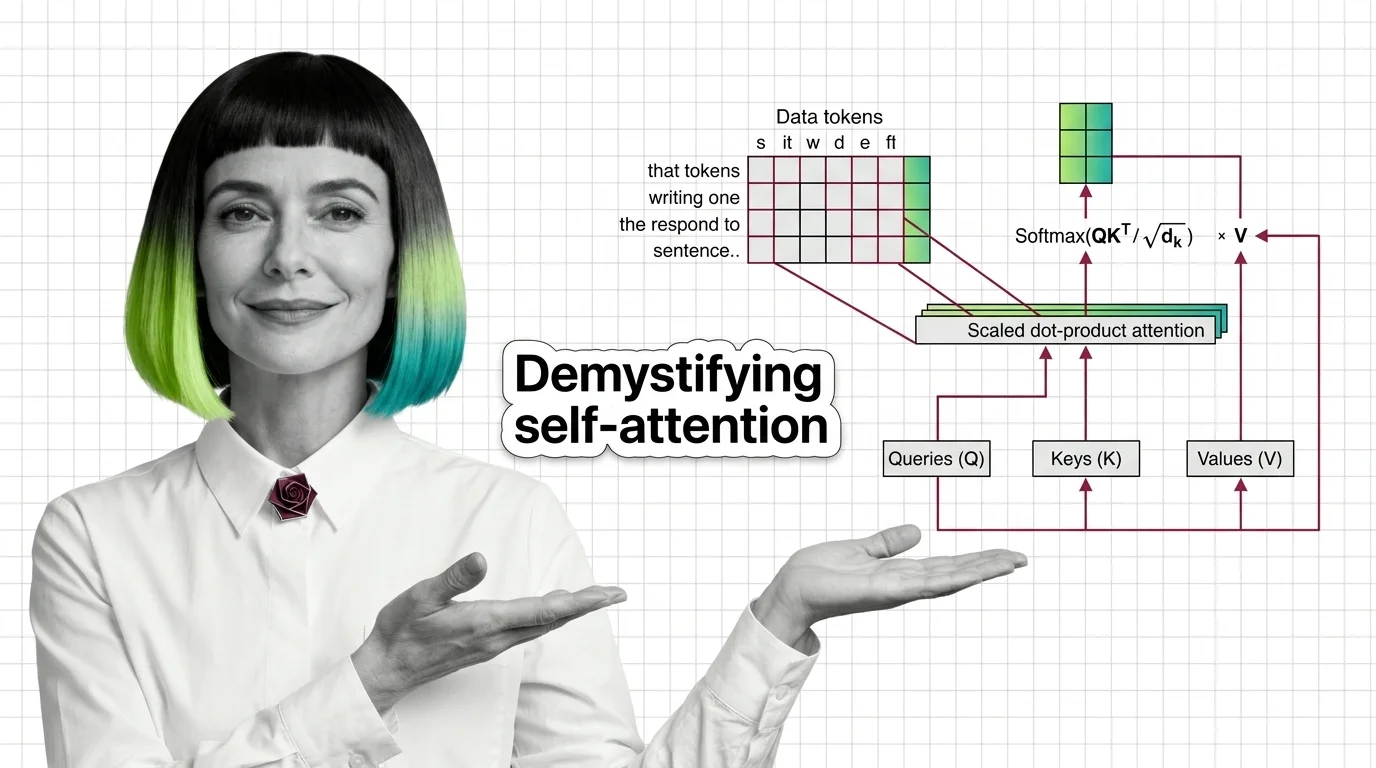
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute …

Curse of Dimensionality, Recall vs. Speed, and the Hard Limits of Approximate Nearest Neighbor Search
High-dimensional similarity search faces hard mathematical limits. Explore the curse of dimensionality, recall-speed …
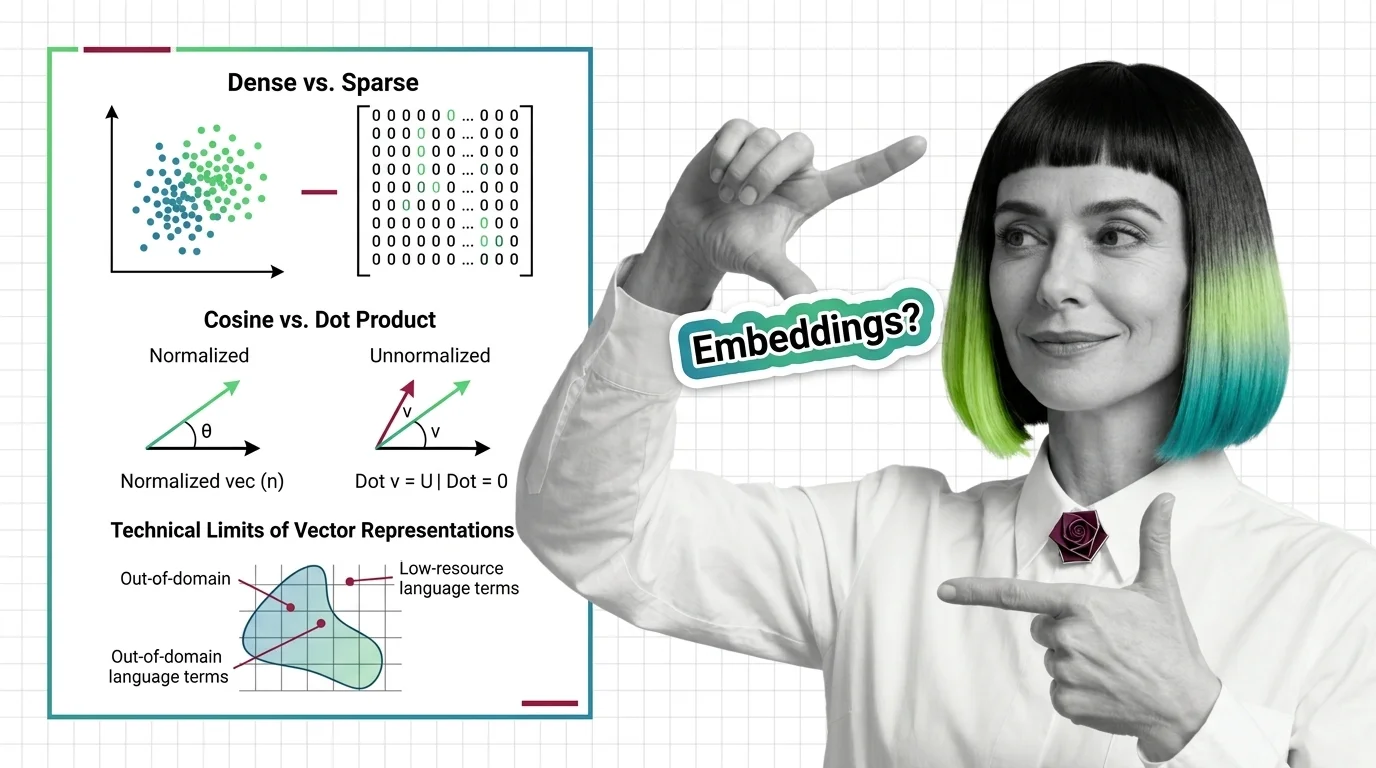
Dense vs. Sparse, Cosine vs. Dot Product, and the Technical Limits of Vector Representations
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance …
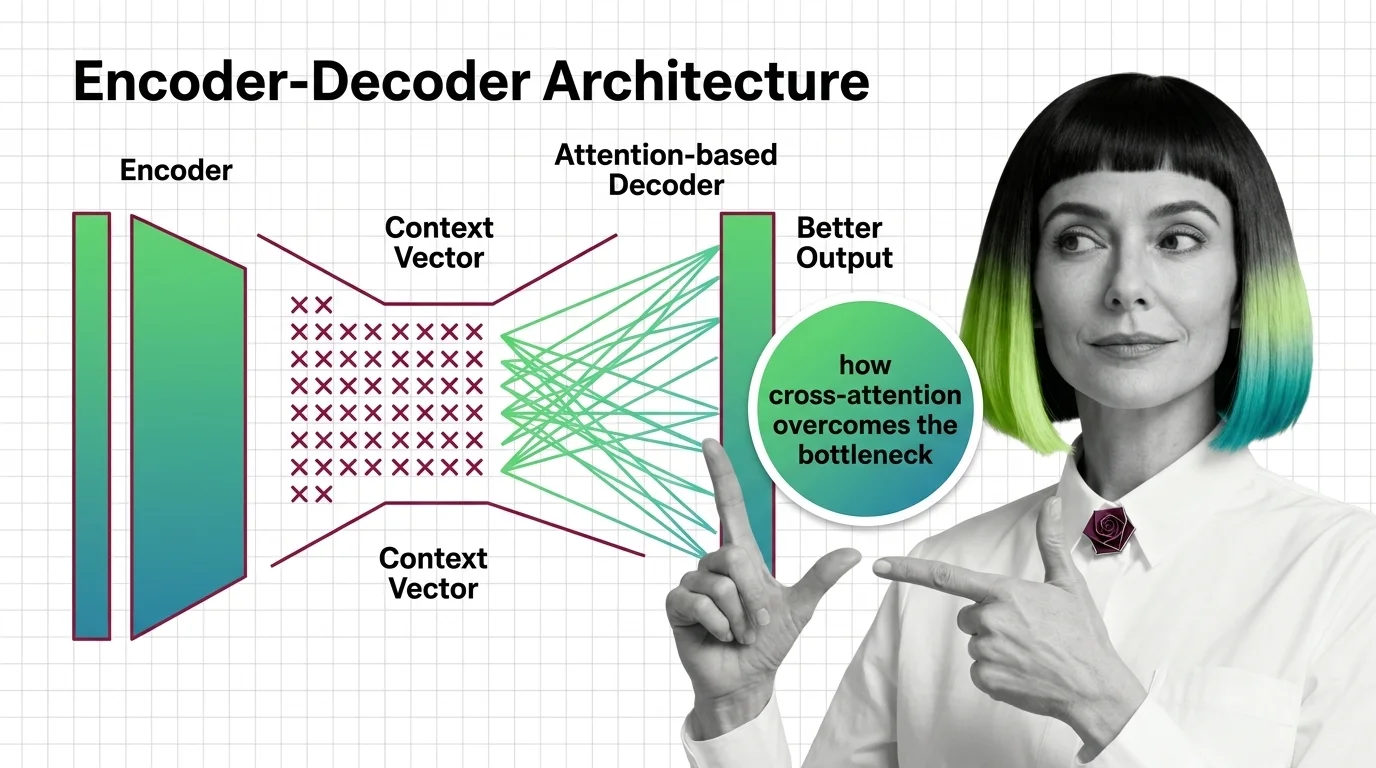
From Context Vectors to Cross-Attention: How Encoder-Decoder Design Overcame the Bottleneck Problem
The encoder-decoder bottleneck crushed long sequences into one vector. Learn how attention replaced compression with …
From Distance Metrics to Index Structures: The Building Blocks of Vector Similarity Search
Similarity search combines distance metrics, index structures, and quantization. Learn how HNSW, IVF, LSH, and product …

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
Multi-Head Attention, Positional Encoding, and the Encoder-Decoder Structure Explained
Multi-head attention, positional encoding, and encoder-decoder structure: the three mechanisms inside every transformer, …
Prerequisites for Understanding Transformers: From RNNs to Quadratic Scaling Limits
Understand why RNNs failed, how transformer self-attention trades parallelism for quadratic cost, and what these …
Self-Attention vs. Cross-Attention vs. Causal Masking: Attention Variants and Their Limits
Self-attention, cross-attention, and causal masking solve different problems inside transformers. Learn the math, …
What Are Similarity Search Algorithms and How Nearest Neighbor Methods Find Matching Vectors
Similarity search algorithms find matching vectors by measuring geometric distance, not keywords. Learn how HNSW, PQ, …

What Is an Embedding and How Neural Networks Encode Meaning into Vectors
Embeddings turn words into vector coordinates where distance equals meaning. Learn the geometry, training mechanics, and …

What Is Decoder-Only Architecture and How Autoregressive LLMs Generate Text Token by Token
Decoder-only architecture powers every major LLM today. Learn how causal masking, KV cache, and autoregressive …
What Is Encoder-Decoder Architecture and How Sequence-to-Sequence Models Process Language
Encoder-decoder models compress input sequences into vectors and generate outputs token by token. Learn how seq2seq …
What Is Tokenizer Architecture and How BPE, WordPiece, and Unigram Encode Text for LLMs
Tokenizer architecture determines how LLMs read text. Learn how BPE, WordPiece, and Unigram split text into subword …

What Is Transformer Architecture and How Self-Attention Replaced Recurrence
Transformers replaced sequential recurrence with parallel self-attention. Understand QKV computation, multi-head …
Why Decoder-Only Beat Encoder-Decoder: Scaling Laws, Data Efficiency, and the Simplicity Advantage
Decoder-only models won the scaling race by doing less. Learn how a simpler training objective, scaling laws, and MoE …
From Embeddings to Attention: The Math You Need Before Studying Transformers
Master the math behind attention mechanisms — dot products, softmax, QKV matrices, and multi-head projections — before …
Prerequisites for Understanding Transformers: From Embeddings to Matrix Multiplication
Master the math behind transformers: embeddings, matrix multiplication, positional encoding, and multi-head attention …
What Is the Attention Mechanism: Scaled Dot-Product, Self-Attention, and Cross-Attention Explained
Understand how the attention mechanism works inside transformers. Covers scaled dot-product attention, self-attention vs …
What Is the Transformer Architecture and How Self-Attention Really Works
The transformer architecture powers every major LLM. Learn how self-attention computes token relationships, why …
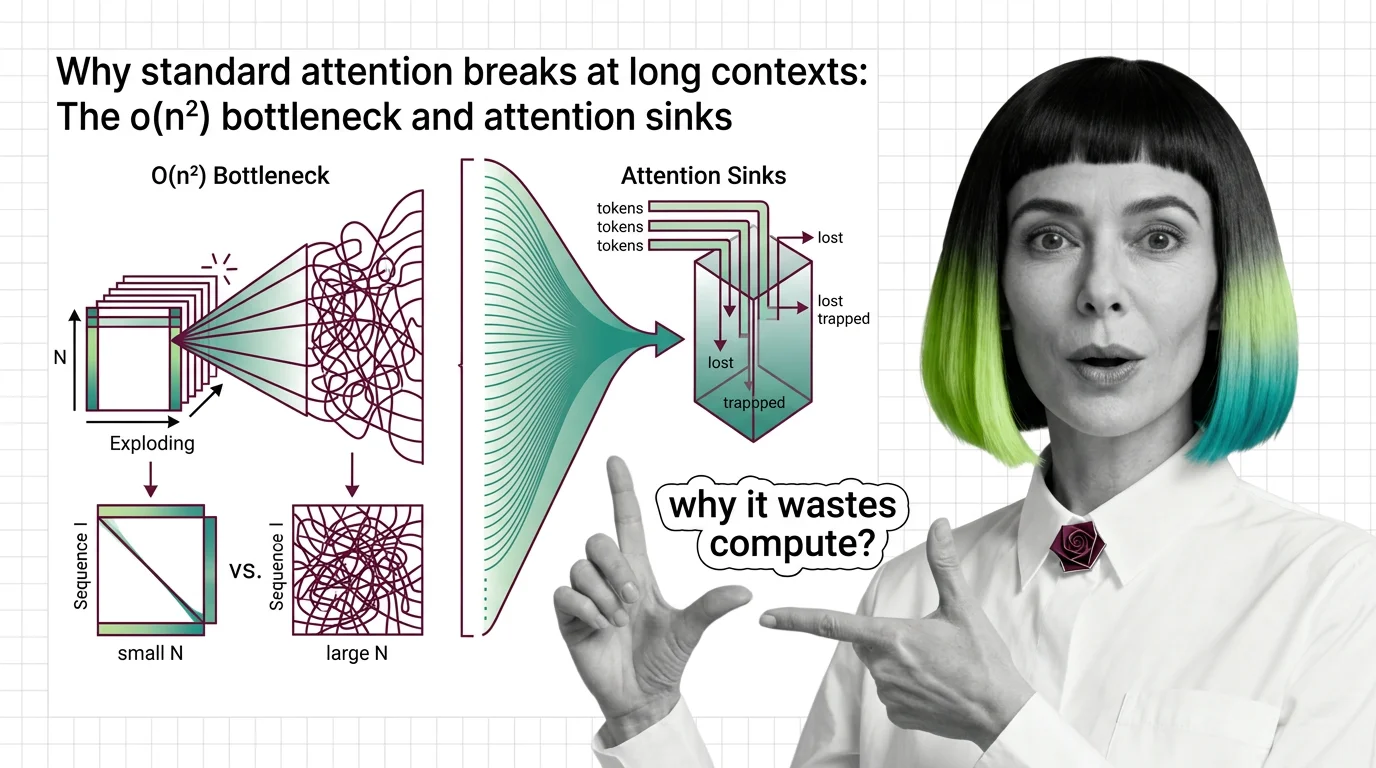
Why Standard Attention Breaks at Long Contexts: The O(n²) Bottleneck and Attention Sinks
Standard attention scales quadratically with sequence length. Learn why O(n²) breaks at long contexts, what attention …
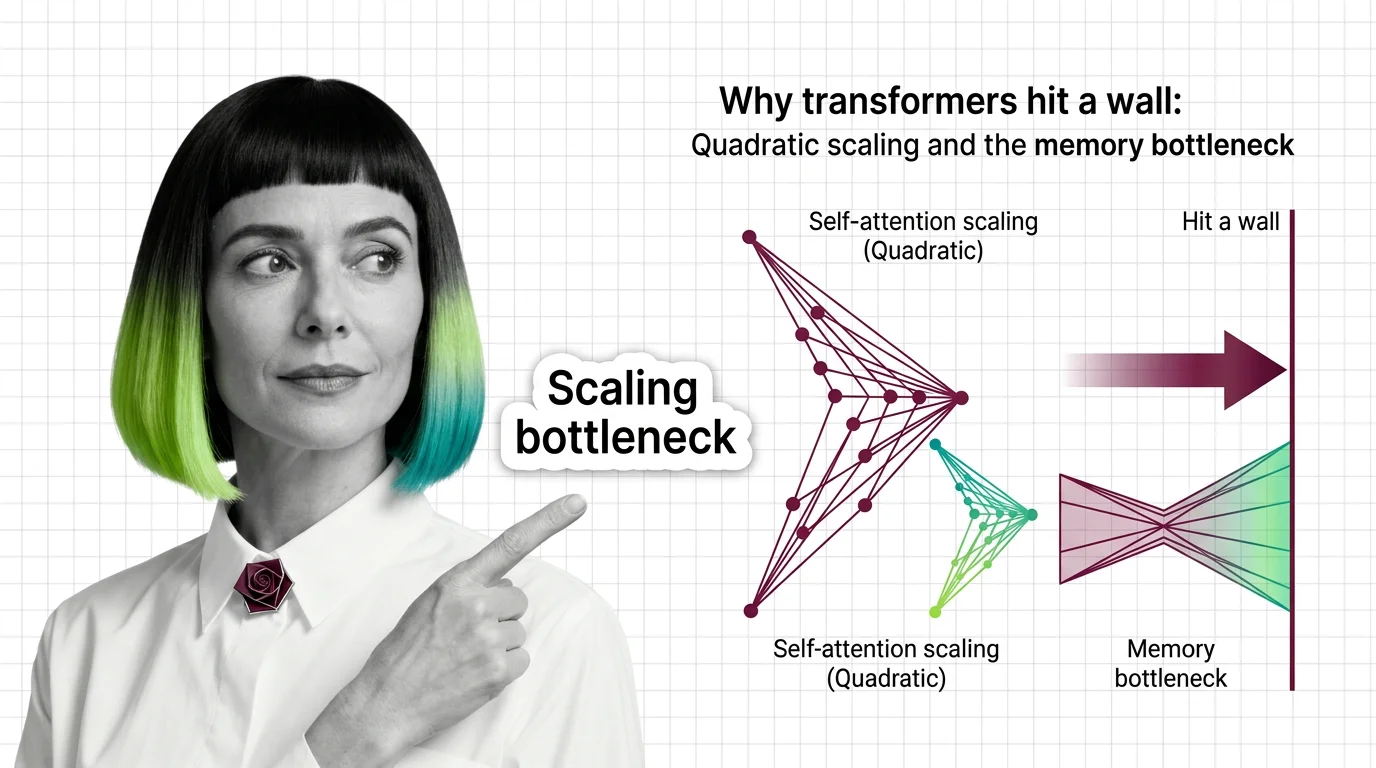
Why Transformers Hit a Wall: Quadratic Scaling and the Memory Bottleneck
Transformer self-attention scales quadratically with sequence length. Understand the O(n²) memory wall, KV cache costs, …