From Cosine Similarity to Anisotropy: Prerequisites and Hard Limits of Sentence-Level Embeddings
Sentence Transformers encode meaning as geometry. Learn the prerequisites, token limits, and anisotropy traps that …

How to Fine-Tune and Deploy Sentence Transformers for Semantic Search and Clustering in 2026
Fine-tune Sentence Transformers v5.3 for semantic search and clustering. Covers MultipleNegativesRankingLoss, Matryoshka …
Sentence Transformers v5.3 vs. Gemini Embedding and NV-Embed: The Open-Source Framework's 2026 MTEB Crossroads
Sentence Transformers v5.3 ships new contrastive losses as Gemini Embedding claims MTEB #1. Here's why the framework vs. …
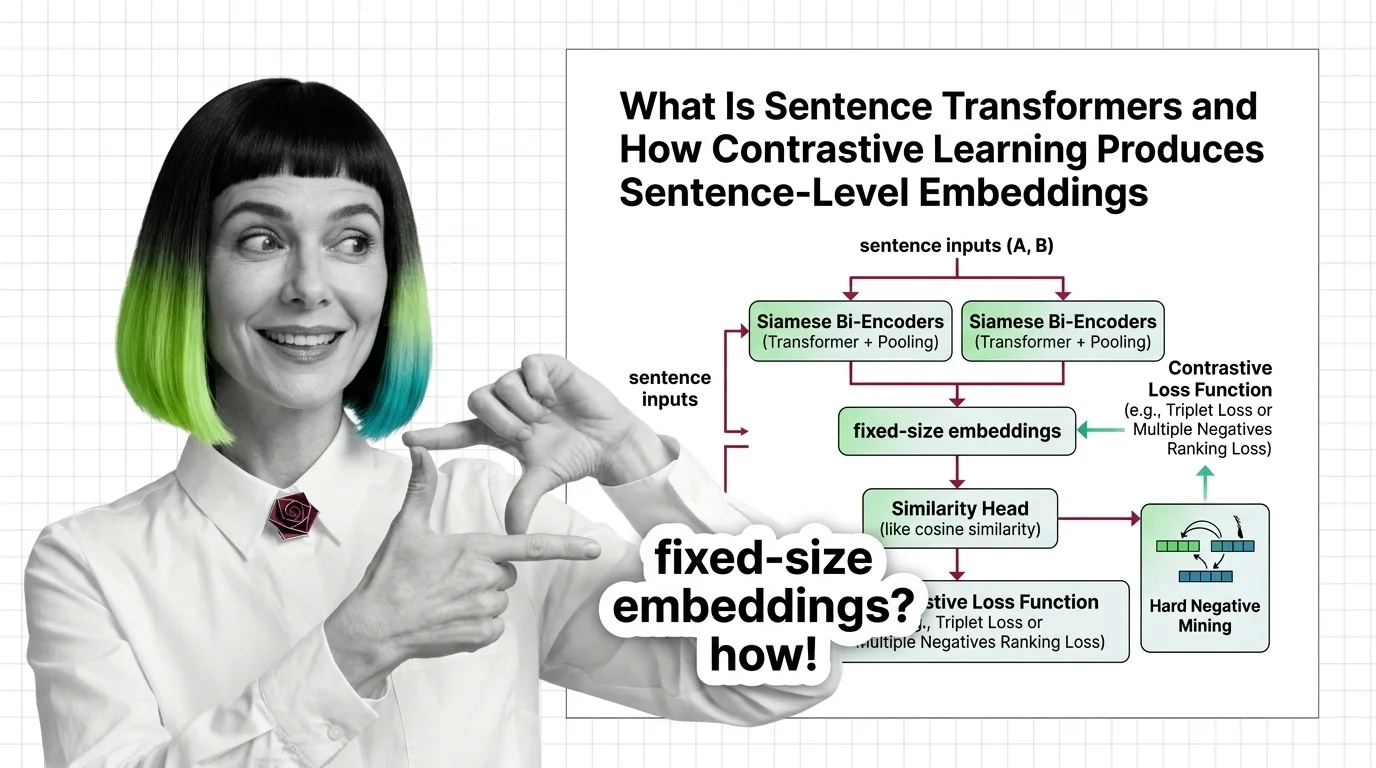
What Is Sentence Transformers and How Contrastive Learning Produces Sentence-Level Embeddings
Sentence Transformers turns transformers into sentence encoders via contrastive learning. Covers bi-encoders, loss …
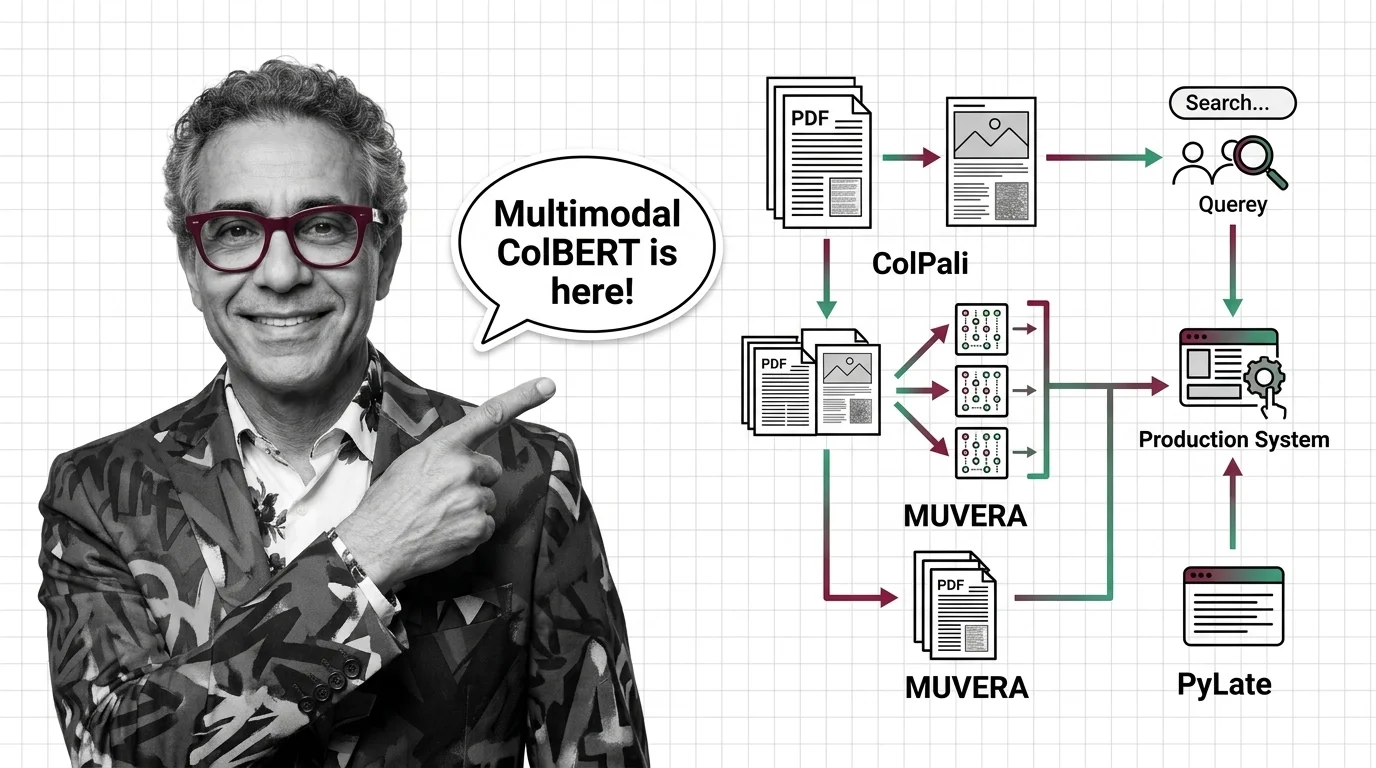
ColPali, MUVERA, and PyLate: How Multi-Vector Retrieval Went Multimodal in 2026
ColPali, MUVERA, and PyLate converged to make multi-vector retrieval multimodal and production-ready. Here's what the …

From Embeddings to Token-Level Matching: Prerequisites and Hard Limits of Multi-Vector Search
Multi-vector retrieval trades storage and latency for token-level precision. Learn the prerequisites, storage math, and …
How to Build a Multi-Vector Retrieval Pipeline with RAGatouille, ColBERTv2, and Qdrant in 2026
Build a production multi-vector retrieval pipeline with ColBERTv2, RAGatouille, and Qdrant. Specification-first …
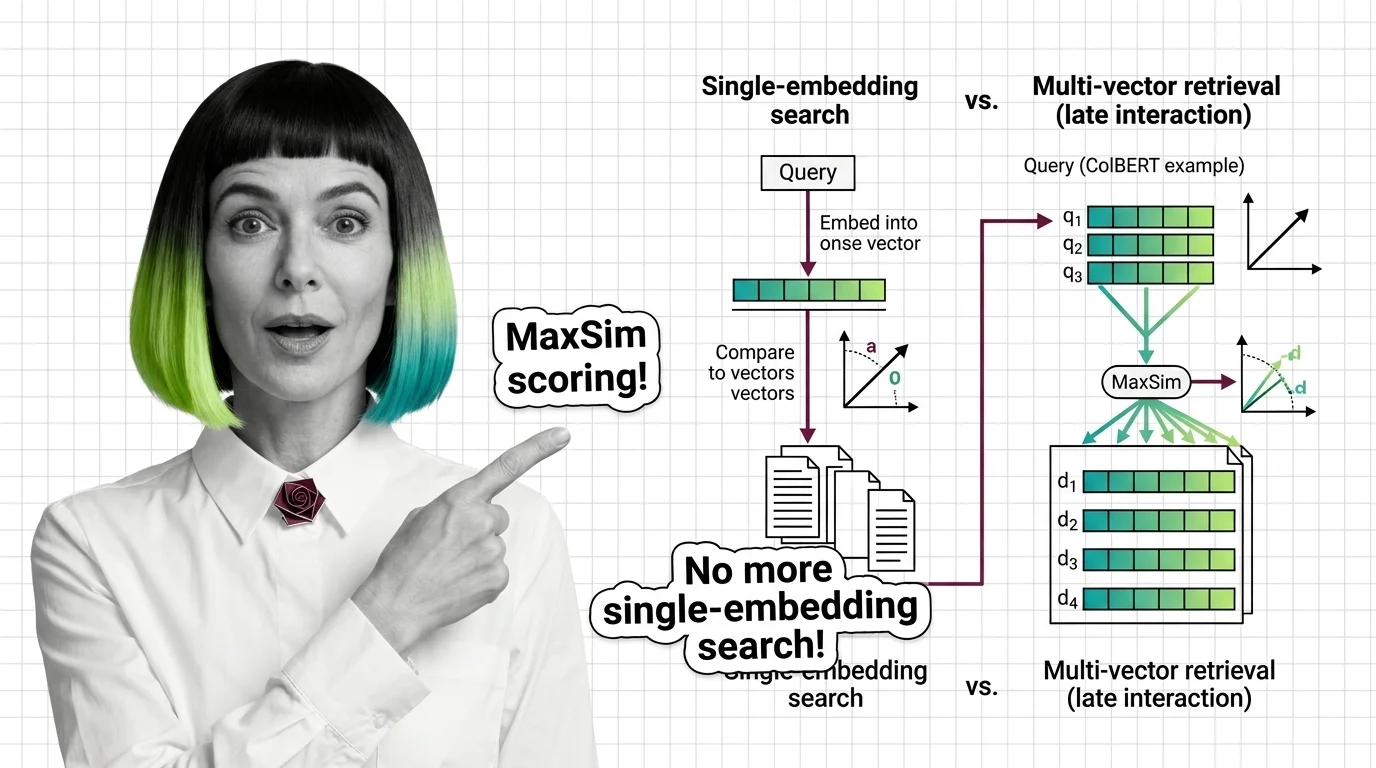
What Is Multi-Vector Retrieval and How Late Interaction Replaces Single-Embedding Search
Multi-vector retrieval stores per-token embeddings instead of one vector per document. Learn how ColBERT MaxSim scoring …

From Distance Metrics to Graph Traversal: Prerequisites for Understanding Vector Index Internals
Distance metrics, high-dimensional geometry, exact vs approximate search — the prerequisites you need before HNSW and …
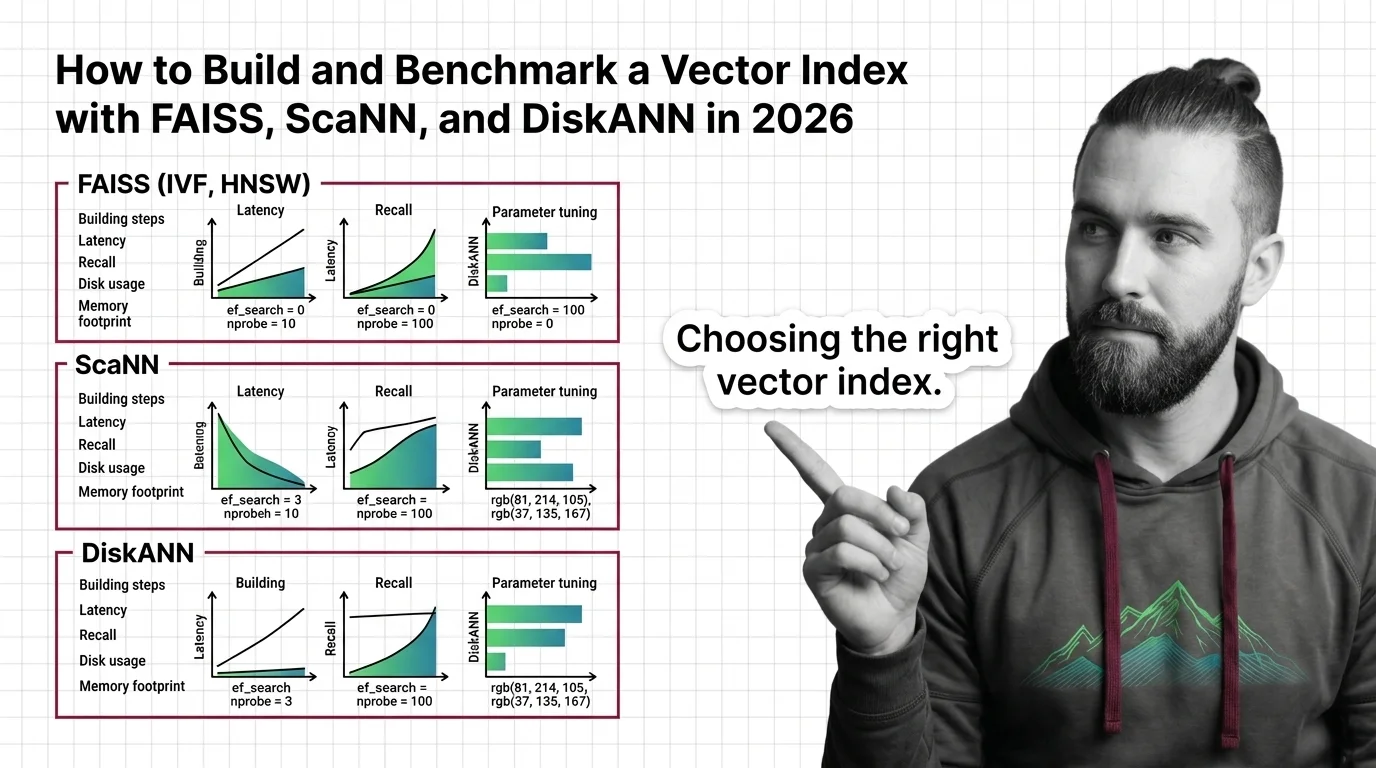
How to Build and Benchmark a Vector Index with FAISS, ScaNN, and DiskANN in 2026
Build and benchmark vector indexes with FAISS, ScaNN, and DiskANN. Choose index types by dataset size, tune parameters …
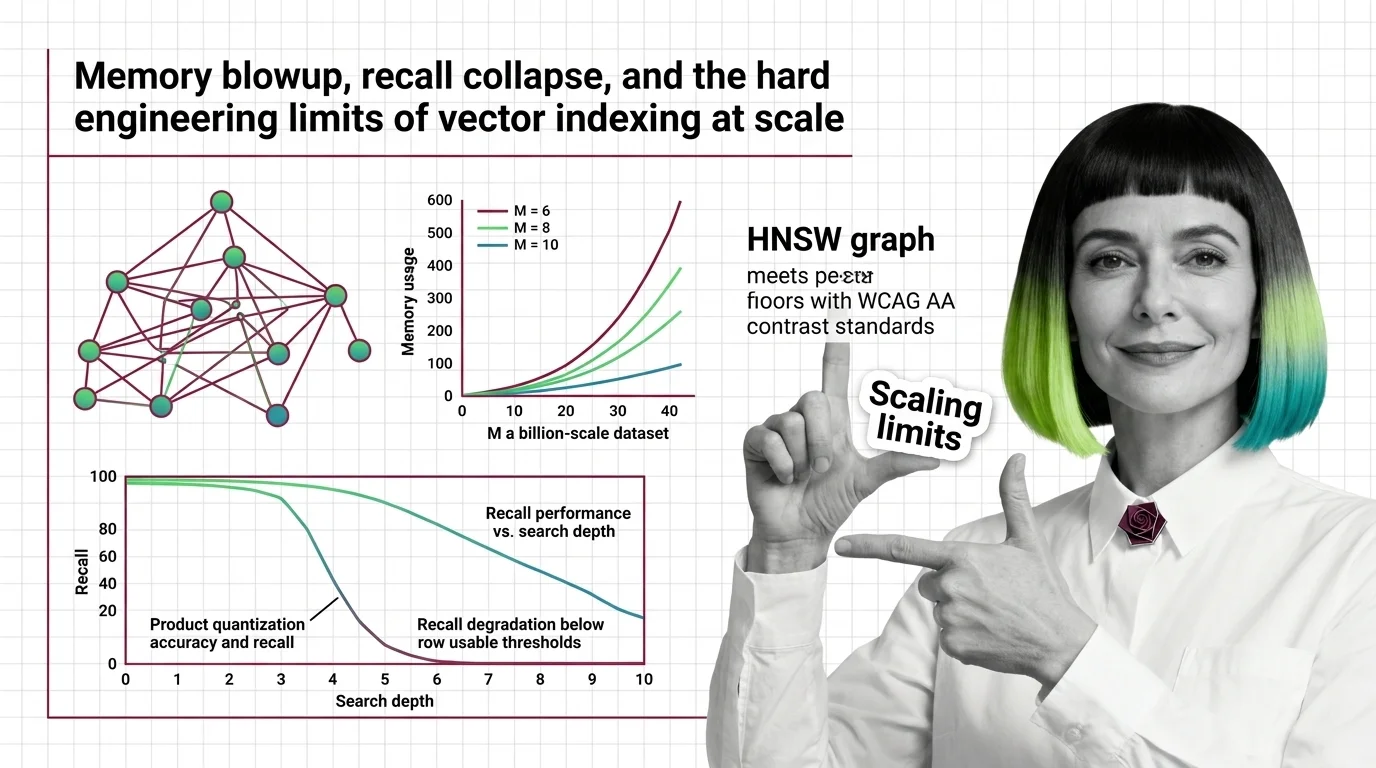
Memory Blowup, Recall Collapse, and the Hard Engineering Limits of Vector Indexing at Scale
HNSW memory grows linearly with connectivity while PQ recall collapses on high-dimensional embeddings. Learn where …
ScaNN, DiskANN, and Glass: The 2026 ANN-Benchmarks Race and Where Vector Indexing Is Heading
SymphonyQG, Glass, and ScaNN are rewriting ANN benchmark rankings. Learn which vector indexing strategies win at scale …
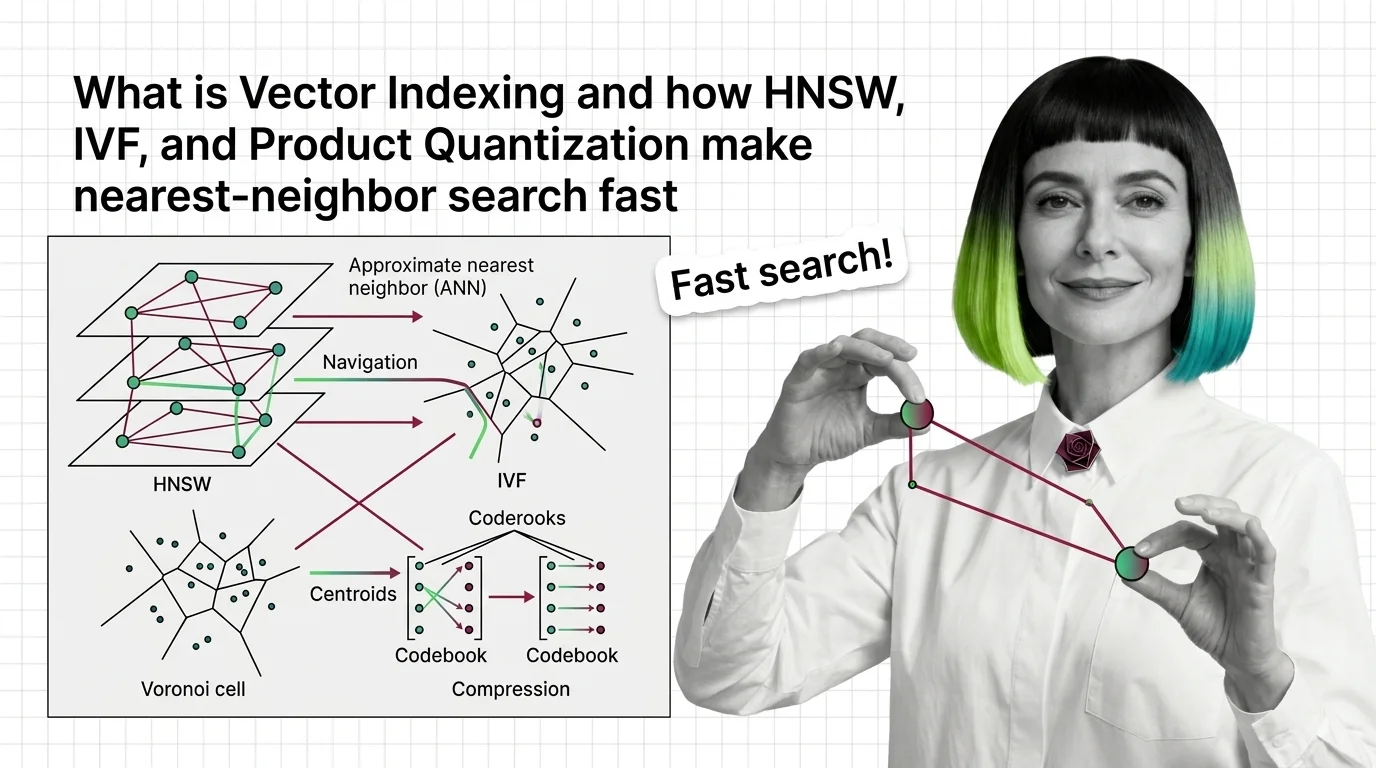
What Is Vector Indexing and How HNSW, IVF, and Product Quantization Make Nearest-Neighbor Search Fast
Vector indexing replaces brute-force search with graph, partition, and compression strategies. Learn how HNSW, IVF, and …
Approximate by Design: What Gets Lost When Vector Indexing Decides Which Results You See
Approximate nearest neighbor search silently drops results. In hiring, healthcare, and legal systems, that design …

Finer-Grained Search, Higher Barriers: Who Multi-Vector Retrieval Leaves Behind
Multi-vector retrieval boosts search quality but demands infrastructure few can afford. Who benefits from finer-grained …

Frozen Bias, Invisible Harm: The Ethical Risks of Sentence Embeddings in Automated Decision Systems
Sentence embeddings encode gender, racial, and cultural bias from training data. This essay examines the ethical risks …
Vector Search for Developers: What Transfers and What Breaks
Vector search mapped for backend developers. Learn which database instincts transfer, where approximate results break …
Transformer Internals for Developers: What Maps, What Breaks
Transformer internals mapped for backend developers. Learn which service-architecture instincts still apply, where …
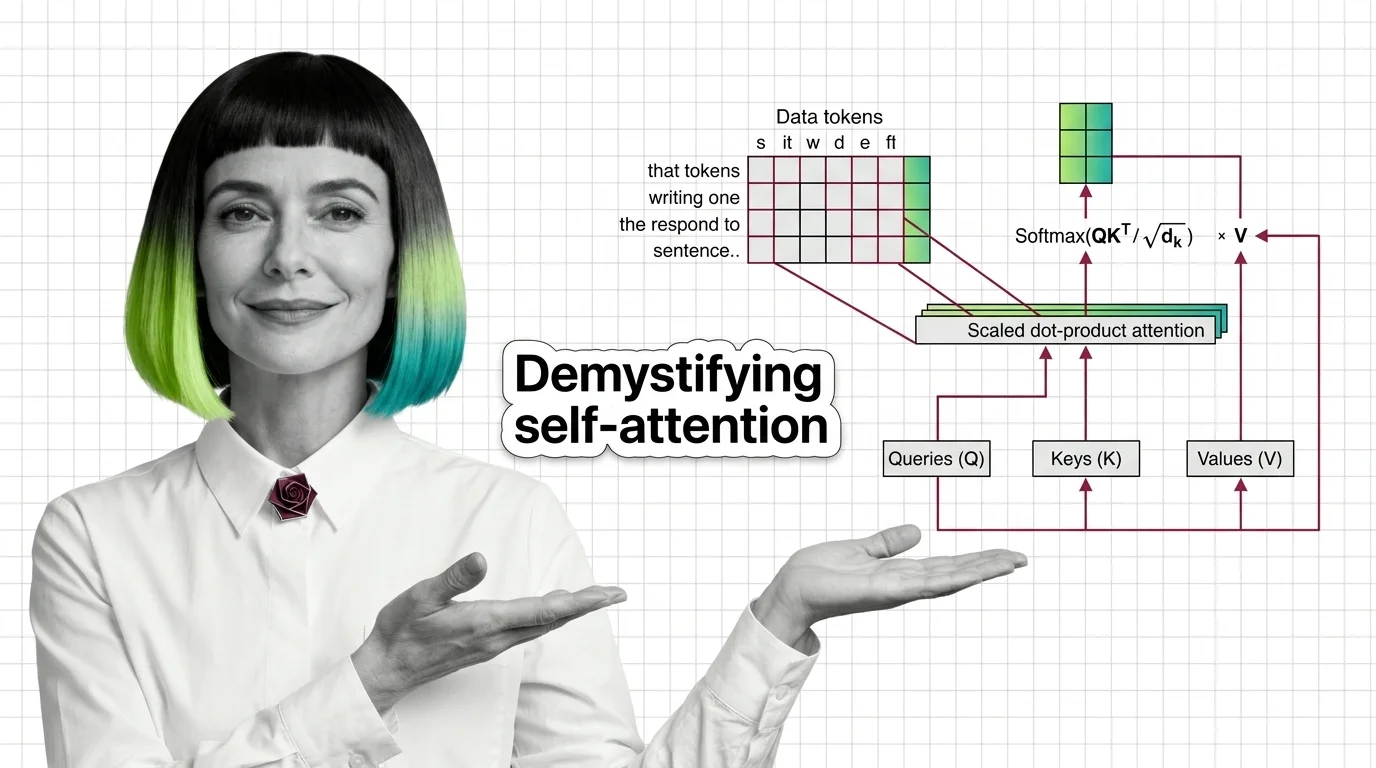
Attention Mechanism Explained: How Queries, Keys, and Values Power Modern AI
Attention mechanisms let neural networks weigh input relevance dynamically. Learn how queries, keys, and values compute …

Automated Translation at Scale: Bias, Erasure, and Accountability in Encoder-Decoder Systems
Encoder-decoder models like NLLB promise inclusion across hundreds of languages. But when systems erase gender, culture, …

Beyond O(n²): How Linear Attention, Ring Attention, and Gated DeltaNet Are Reshaping AI in 2026
Linear attention hybrids with a 3:1 ratio are replacing pure quadratic self-attention. See which labs lead, who fell …

Curse of Dimensionality, Recall vs. Speed, and the Hard Limits of Approximate Nearest Neighbor Search
High-dimensional similarity search faces hard mathematical limits. Explore the curse of dimensionality, recall-speed …

DeepSeek MLA, LLaMA 4 MoE, and Nemotron Hybrids: Decoder-Only Variants Competing in 2026
The decoder-only paradigm fractured. DeepSeek MLA, LLaMA 4 MoE, and NVIDIA Nemotron hybrids compete on inference cost — …
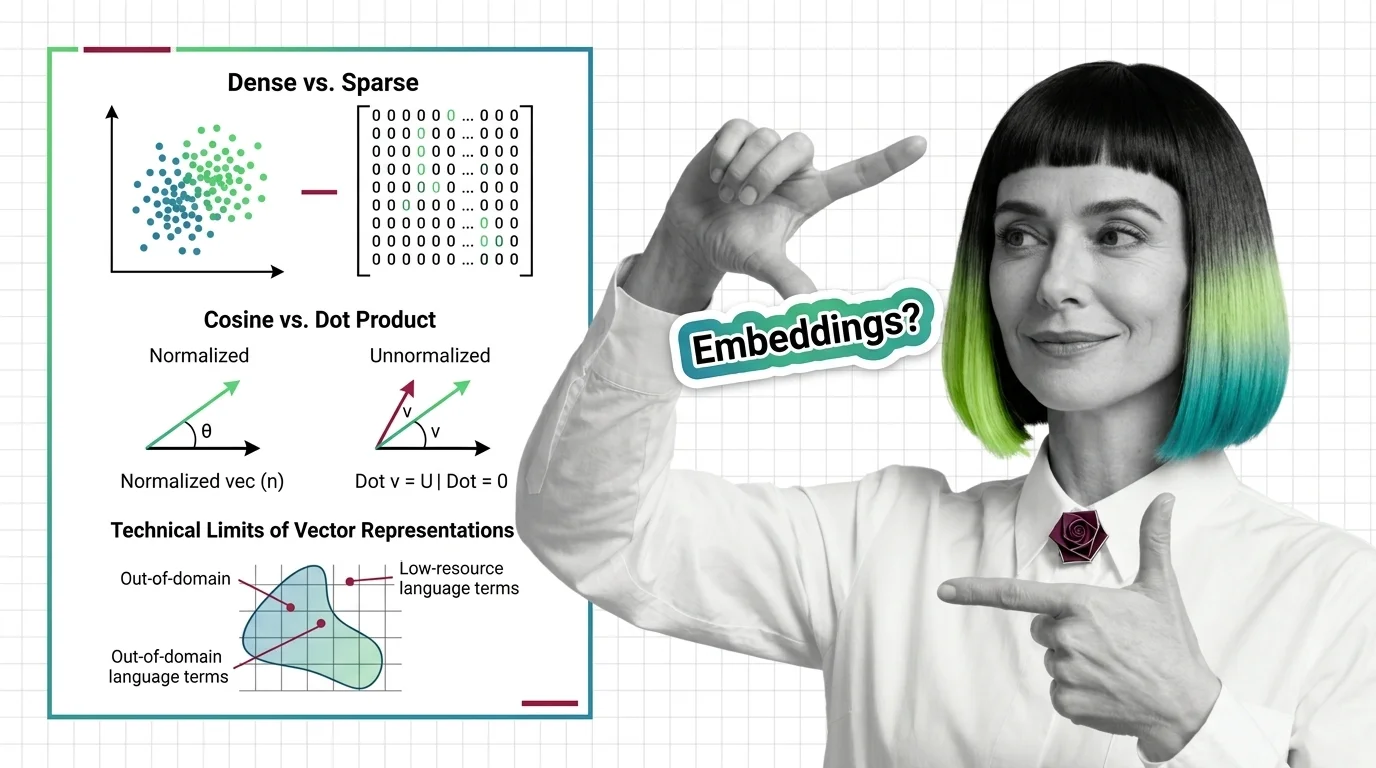
Dense vs. Sparse, Cosine vs. Dot Product, and the Technical Limits of Vector Representations
Dense vs. sparse embeddings encode meaning differently. Learn how cosine similarity, dot product, and Euclidean distance …
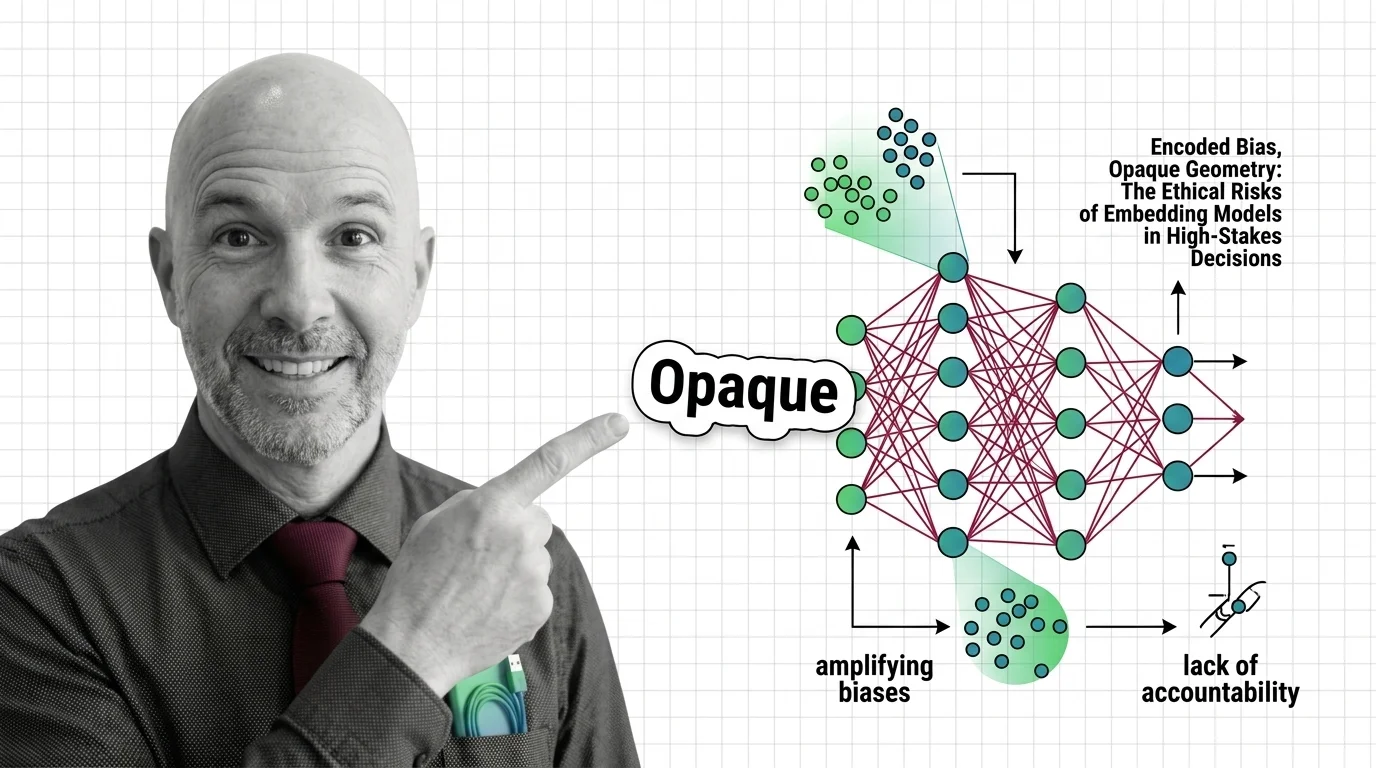
Encoded Bias, Opaque Geometry: The Ethical Risks of Embedding Models in High-Stakes Decisions
Embedding models encode historical biases into geometry that powers hiring and lending. Who is accountable when …
FAISS vs. ScaNN vs. USearch on ANN-Benchmarks: The Similarity Search Library Race in 2026
The ANN library race split into GPU-first and disk-first lanes. See which similarity search libraries lead in 2026 and …
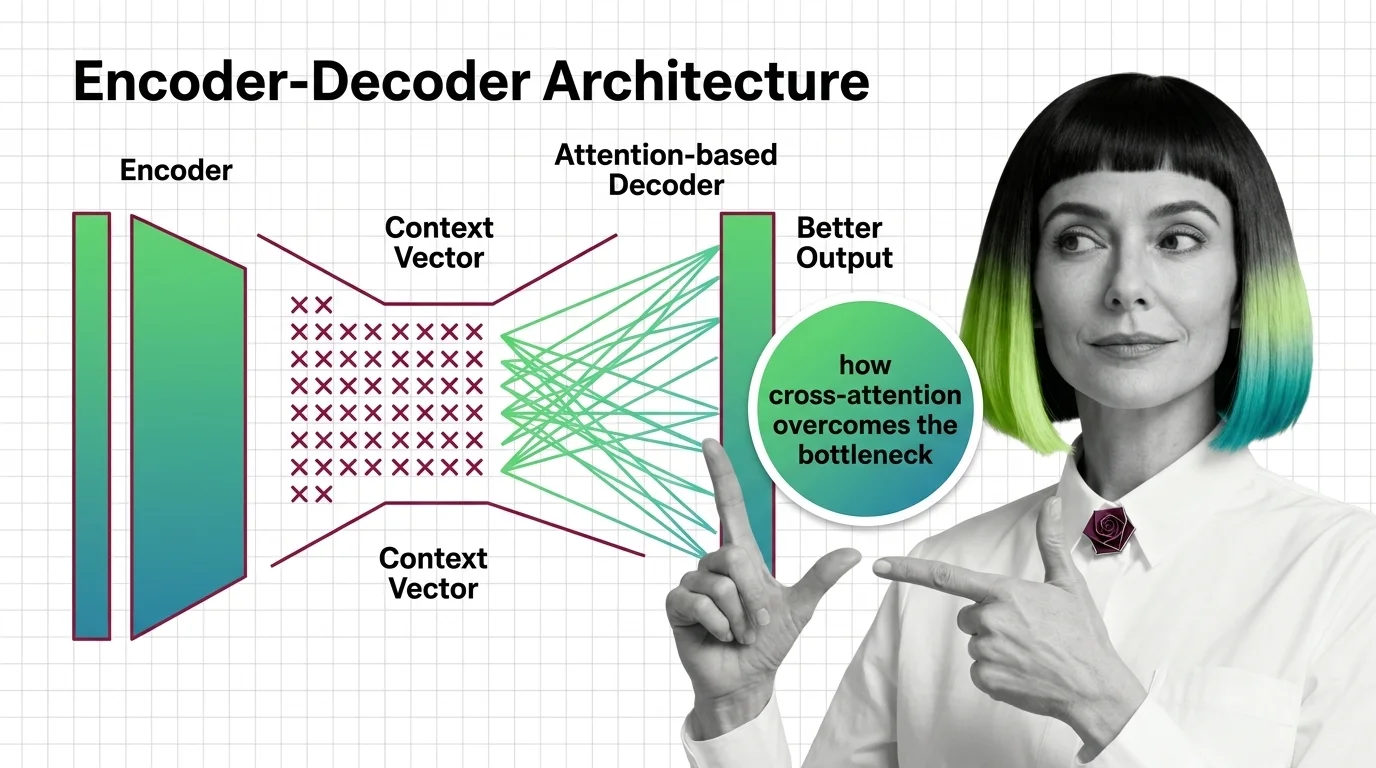
From Context Vectors to Cross-Attention: How Encoder-Decoder Design Overcame the Bottleneck Problem
The encoder-decoder bottleneck crushed long sequences into one vector. Learn how attention replaced compression with …
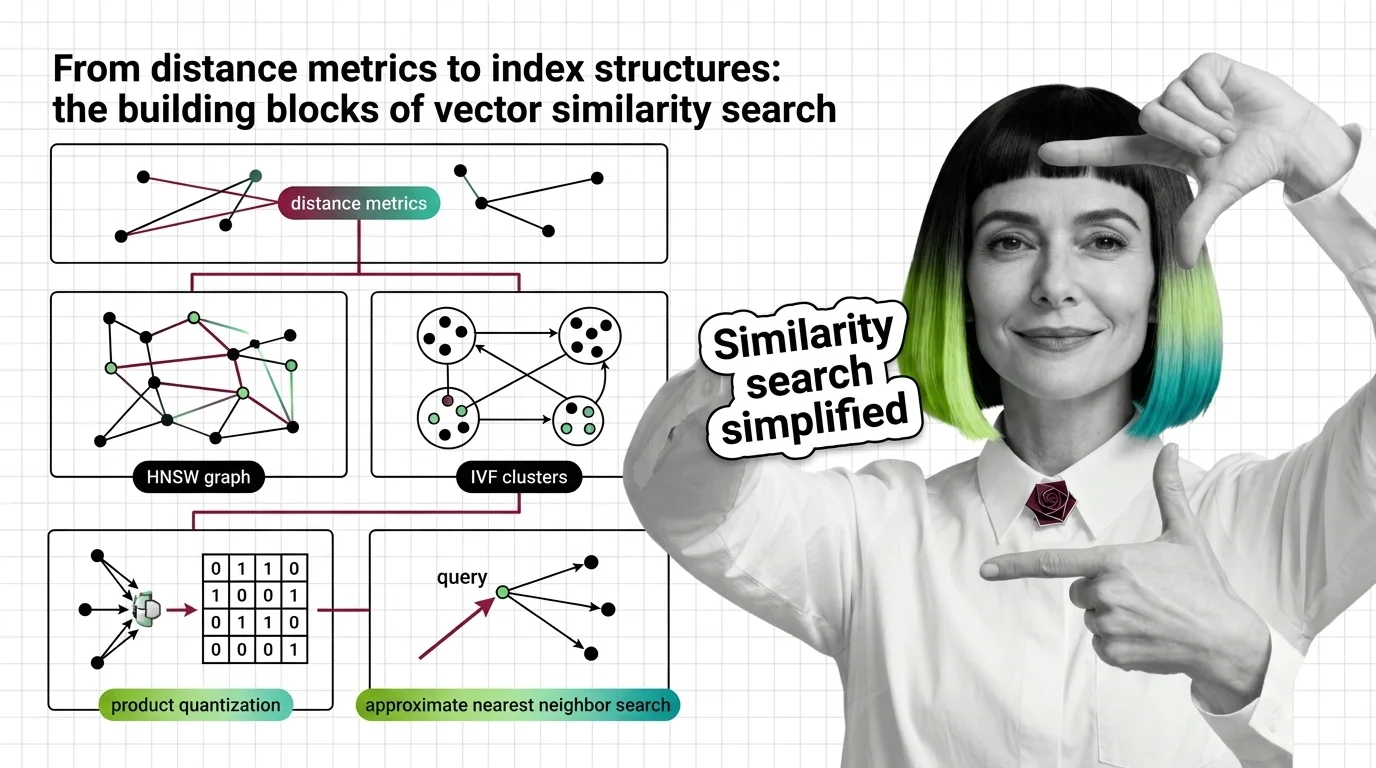
From Distance Metrics to Index Structures: The Building Blocks of Vector Similarity Search
Similarity search combines distance metrics, index structures, and quantization. Learn how HNSW, IVF, LSH, and product …

Glitch Tokens, Fertility Gaps, and the Unsolved Technical Limits of Subword Tokenization
BPE tokenizers produce glitch tokens and penalize non-Latin scripts with fertility gaps. Learn where the math breaks — …
How to Build a Decoder-Only Transformer and Select the Right Pretrained Model in 2026
Build a decoder-only transformer with correct causal masking in PyTorch, then pick between GPT-5, LLaMA 4, and DeepSeek …