Accuracy Collapse, Task-Specific Degradation, and the Hard Limits of Sub-4-Bit Quantization

Table of Contents
ELI5
Shrinking an LLM’s numbers from 16-bit to 4-bit barely changes its answers. Go below 4-bit, and accuracy collapses unevenly — hard reasoning tasks and non-English languages break first.
A quantized model aces grade-school arithmetic without losing a single point. Same model, same bit-width, but hand it a competition-level algebra problem — and the output turns incoherent. The damage is not random noise sprinkled across capabilities. It follows the internal geometry of what the model encoded during training, and that selectivity is more diagnostic than any headline about “lossless compression.”
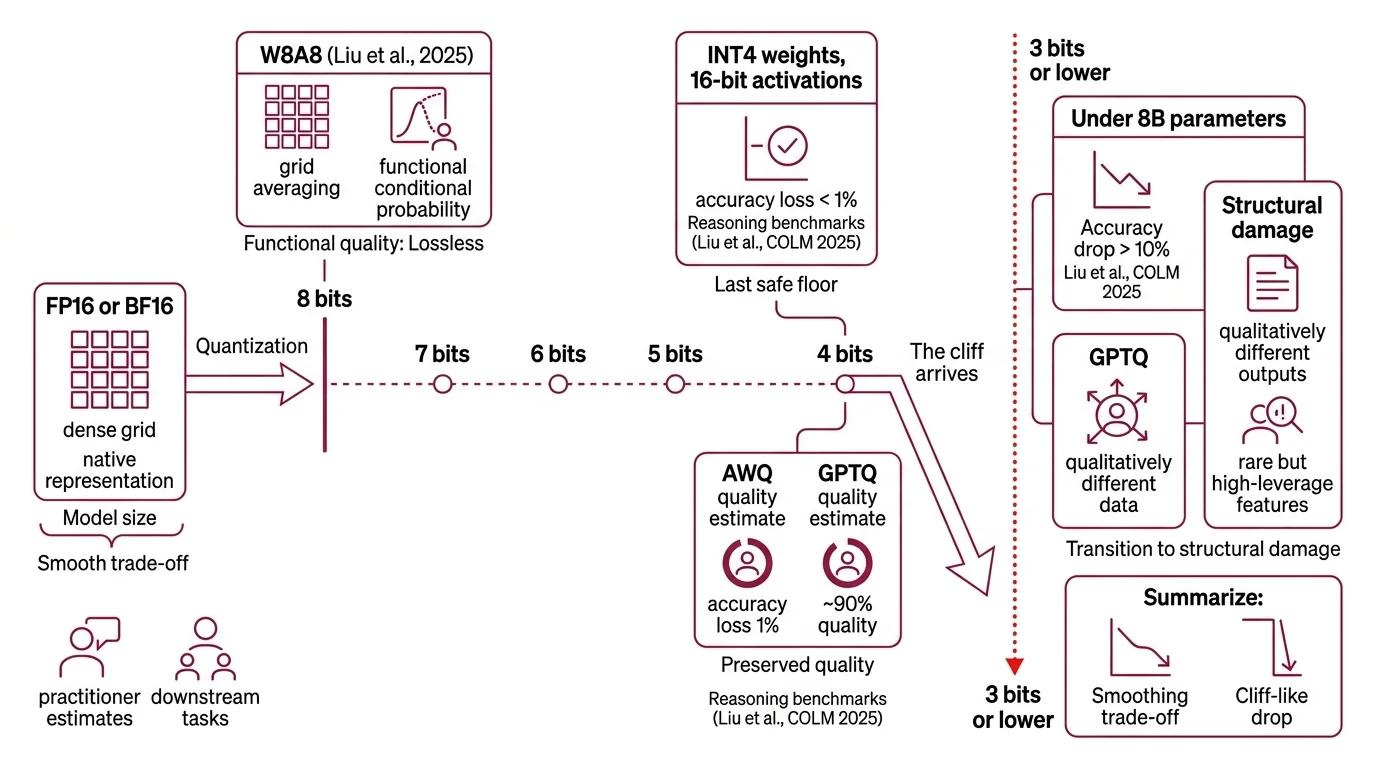
The Cliff Below Four Bits
The intuition most engineers carry — that reducing numerical precision is a smooth, continuous trade-off between model size and output quality — holds right up to the point where it stops. Quantization compresses model weights from their native floating-point representation into lower-bit integers. The question worth asking is not whether this degrades quality but where the degradation transitions from acceptable rounding to structural damage.
How much accuracy do you lose when quantizing an LLM to INT4 or lower?
W8A8 — eight-bit weights, eight-bit activations — is lossless across all tested tasks and model sizes (Liu et al., COLM 2025). At eight bits, the quantization grid remains dense enough that rounding errors average out during Inference; the model’s conditional probability distributions stay functionally intact.
Drop to INT4 — four-bit weights with sixteen-bit activations — and the picture stays surprisingly clean. Reasoning benchmarks show accuracy losses generally below one percent (Liu et al., COLM 2025), with Awq and GPTQ preserving the vast majority of the original model’s quality. Practitioner estimates put AWQ at roughly 95% and GPTQ at roughly 90% of FP16 quality — editorial figures, not controlled measurements, but directionally consistent with the peer-reviewed data. Four bits is the last safe floor for post-training quantization.
Then the cliff arrives.
At three bits, models below eight billion parameters show accuracy drops exceeding ten percent — a qualitative shift, not merely a quantitative one (Liu et al., COLM 2025). At that level, downstream tasks do not just produce worse answers; they produce structurally different outputs. The damage concentrates in weight components that encode rare but high-leverage relationships — the kind of low-frequency features that, at full precision, allow a model to distinguish between subtly different meanings or maintain coherence over long reasoning chains. The quantization grid at three bits is simply too coarse to preserve them. Models with extreme outlier channels in their weight distributions — Qwen-2.5 at 1.5B and 7B parameters, for instance — show failure patterns that trace directly to these unresolvable channels.
At two bits, the collapse is categorical. AWQ-quantized models lose coherent language capabilities entirely across all tested architectures (PTQ Benchmark, 2025). A two-bit ultra-large model underperforms a four-bit version of the smallest model in the same family. The representation space becomes too sparse to maintain the conditional dependencies that language generation requires.
Not a slope. A cliff.
The Selective Cruelty of Bit Reduction
Even above the cliff edge, the damage does not spread evenly. Quantization loss is task-dependent, language-dependent, and modality-dependent — and the pattern of what degrades first reveals something fundamental about how LLMs store different types of knowledge in their weight matrices.
Which tasks and languages degrade most under aggressive quantization?
Start with task difficulty. A reasoning model quantized to four bits with GPTQ loses zero accuracy on GSM8K, a grade-school math benchmark. On MATH-500, a harder set: 1.40% loss. On AIME-120, competition-level problems: 4.17% — a fourfold amplification of degradation across difficulty tiers, from identical quantization applied to identical weights (Liu et al., COLM 2025).
The mechanism is structural. Harder problems force the model to sustain longer chains of conditional token generation; each step involves sampling from a probability distribution shaped by quantized weights, and Temperature And Sampling settings amplify whatever distortions quantization introduces into those distributions. Errors compound forward through the chain. Grade-school problems resolve in fewer steps, giving quantization noise fewer chances to cascade into wrong answers.
Math reasoning under GPTQ and AWQ quantization on Llama-3 models shows losses averaging around eleven percent, with worst cases exceeding thirty percent (Li et al., 2025). These are indicative ranges — exact figures shift by model, calibration data, and evaluation benchmark — but the asymmetry between easy and hard tasks holds consistently across studies.
Languages tell a parallel story with a sharper edge. Non-Latin scripts suffer disproportionately, and the gap between automated metrics and human judgment is wider than most teams realize. For Japanese, one study measured a 1.7% drop on automatic metrics alongside a 16% drop on human evaluation — the model’s outputs appeared fluent to BLEU scores while being semantically degraded in ways only native readers caught (Marchisio et al., 2024). That study predates some newer calibration methods that may partially mitigate the gap, but the root cause — non-English tokens underrepresented in calibration datasets — persists as a systemic bias in quantization pipelines.
Multimodal models face a harsher threshold still. At sub-4-bit precision, multimodal LLMs collapse to near-zero accuracy on vision-language tasks while text-only models degrade modestly at the same bit-width (LUQ, 2025). Visual encoders carry spatial and relational information in weight distributions less tolerant of aggressive rounding — quantization noise disrupts them more catastrophically than it disrupts sequential language patterns.
Then there is the training variable most benchmarks overlook. Models fine-tuned with reinforcement learning show degradation roughly fourteen to sixteen percent worse on hard reasoning tasks than distilled models, which degrade more gracefully under the same compression (Liu et al., COLM 2025). Training method shapes how a model breaks — not just its architecture or parameter count. Each new training paradigm — RL from human feedback, distillation, continued pre-training — creates its own fragility profile under compression. The benchmark that validated the original model tells you nothing about how its quantized version handles the specific tasks you care about.
The Escape Hatches and Their Price
Post-training quantization is the path most practitioners reach for — compress the model after training and accept whatever degradation follows. But PTQ is not the only option, and the alternatives fundamentally reshape the trade-off curve.
Quantization-aware training (QAT) runs training with simulated quantization noise baked into the forward pass, teaching the model to compensate for reduced precision before weights are ever compressed. ParetoQ demonstrated that 1.58-bit and 2-bit models trained with QAT can outperform 4-bit PTQ models on the size-accuracy Pareto frontier (ParetoQ, 2025). A LLaMA-3 8B model at 2-bit QAT achieves a perplexity of 8.0; at 1.58-bit, 8.6 — compared to 6.2 for full precision. Sub-4-bit only survives with training-time quantization. The distinction matters because QAT demands full training infrastructure — GPU clusters, data pipelines, weeks of compute — while PTQ runs on a single workstation. Below four bits, the training procedure matters more than the compression ratio.
For teams committed to PTQ, targeted recovery is possible but narrow. Task-specific fine-tuning with as few as 545 examples — three minutes on four GPUs — restores most of the math reasoning capability lost during quantization (Li et al., 2025). The cost is specificity: a model recovered for math may silently trade away quality on other capabilities.
Tooling choices shape where the pain lands. GGUF offers flexible per-layer quantization that Llama Cpp exploits for CPU and hybrid inference; Bitsandbytes enables on-the-fly mixed-precision workflows on GPU. Mixed Precision Training strategies — keeping sensitive layers at higher precision while compressing less critical ones — represent the practical middle ground between uniform bit reduction and full-precision operation.
Compatibility notes:
- AutoGPTQ: Archived as of April 2025. Replaced by GPTQModel (v5.6.0, December 2025). Migration required for active projects.
- AutoAWQ: Deprecated. Functionality moved to vLLM’s llm-compressor. Existing AutoAWQ workflows need updating.
What the Collapse Pattern Predicts
If you are quantizing to INT4 to increase throughput in Continuous Batching inference pipelines, expect functionally lossless behavior on straightforward generative tasks. If your workload involves multi-step reasoning, budget for one-to-four percent degradation on the hardest problems in your distribution — and validate against those tasks specifically, not the median.
If your users work primarily in non-English languages — especially those with non-Latin scripts — automated quality metrics will underestimate the real damage. Human evaluation is the only reliable gate.
If you are considering sub-4-bit quantization for memory savings, the arithmetic only closes with QAT-trained models. PTQ below four bits is, for practical purposes, a one-way trip to incoherence on anything beyond simple completions. If you are running models fine-tuned with reinforcement learning, widen the degradation budget — distilled models handle quantization more gracefully, and the margin between the two widens as bit-width decreases.
Rule of thumb: treat W4A16 as the practical floor for post-training quantization. Anything below requires QAT, task-specific recovery, or both — and validate on the hardest tasks in your pipeline, not the average.
When it breaks: sub-4-bit PTQ fails catastrophically and silently on competition-level reasoning, non-Latin languages, and multimodal inputs — three domains where degradation exceeds what standard benchmarks report.
The Data Says
The boundary between four bits and three bits is not a gradual slope; it is a phase transition. Models do not get slightly worse — they lose structural capabilities in patterns correlated with task difficulty, linguistic representation, and training methodology. Quantize to four bits with confidence. Approach three bits only with QAT infrastructure. Treat two bits as a research frontier rather than a deployment option.
AI-assisted content, human-reviewed. Images AI-generated. Editorial Standards · Our Editors